Due to jetlag, my CAREER proposal deadline, and perhaps a bit of general laziness, I didn’t take as many notes at ISIT as I would have, so my posting will be somewhat light (in addition to being almost a month delayed). If someone else took notes on some talks and wants to guest-post on it, let me know!
Strong Large Deviations for Composite Hypothesis Testing
Yen-Wei Huang (Microsoft Corporation, USA); Pierre Moulin (University of Illinois at Urbana-Champaign, USA)
This talk was actually given by Vincent Tan since neither of the authors could make it (this seems to be a theme of talks I’ve attended this summer. The paper was about testing a simple hypothesis 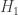 versus a composite hypothesis
versus a composite hypothesis  where under the observations are i.i.d. with respect to one of possibly
where under the observations are i.i.d. with respect to one of possibly  different distributions. There are therefore different errors and the goal is to characterize these errors when we ask for the probability of true detection to be greater than
different distributions. There are therefore different errors and the goal is to characterize these errors when we ask for the probability of true detection to be greater than  . This is a sort of generalized Neyman-Pearson setup. They look at the vector of log-likelihood ratios and show that a threshold test is nearly optimal. At the time, I understood the idea of the proof, but I think it’s one of things where you need to really read the paper.
. This is a sort of generalized Neyman-Pearson setup. They look at the vector of log-likelihood ratios and show that a threshold test is nearly optimal. At the time, I understood the idea of the proof, but I think it’s one of things where you need to really read the paper.
Randomized Sketches of Convex Programs with Sharp Guarantees
Mert Pilanci (University of California, Berkeley, USA); Martin J. Wainwright (University of California, Berkeley, USA)
This talk was about using random projections to lower the complexity of solving a convex program. Suppose we want to minimize 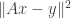 over
over  given
given  . A sketch would be to solve
. A sketch would be to solve 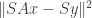 where
where  is a random projection. One question is how to choose
is a random projection. One question is how to choose  . They show that choosing to be a randomized Hadamard matrix (the paper studies Gaussian matrices), then the objective value of the sketched program is at most
. They show that choosing to be a randomized Hadamard matrix (the paper studies Gaussian matrices), then the objective value of the sketched program is at most 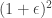 times the value of the original program as long as the the number of rows of is larger than
times the value of the original program as long as the the number of rows of is larger than  , where
, where 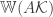 is the Gaussian width of the tangent cone of the contraint set at the optimum value. For more details look at their preprint on ArXiV.
is the Gaussian width of the tangent cone of the contraint set at the optimum value. For more details look at their preprint on ArXiV.
On Efficiency and Low Sample Complexity in Phase Retrieval
Youssef Mroueh (MIT-IIT, USA); Lorenzo Rosasco (DIBRIS, Unige and LCSL – MIT, IIT, USA)
This was another talk not given by the authors. The problem is recovery of a complex vector  from phaseless measurements of the form
from phaseless measurements of the form 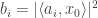 where
where  are complex spherically symmetric Gaussian vectors. Recovery from such measurements is nonconvex and tricky, but an alternating minimizing algorithm can reach a local optimum, and if you start it in a “good” initial position, it will find a global optimum. The contribution of this paper is provide such a smart initialization. The idea is to “pair” the measurements to create new measurements
are complex spherically symmetric Gaussian vectors. Recovery from such measurements is nonconvex and tricky, but an alternating minimizing algorithm can reach a local optimum, and if you start it in a “good” initial position, it will find a global optimum. The contribution of this paper is provide such a smart initialization. The idea is to “pair” the measurements to create new measurements  . This leads to a new problem (with half as many measurements) which is still hard, so they find a convex relaxation of that. I had thought briefly about such sensing setups a long time ago (and by thought, I mean puzzled over it at a coffeshop once), so it was interesting to see what was known about the problem.
. This leads to a new problem (with half as many measurements) which is still hard, so they find a convex relaxation of that. I had thought briefly about such sensing setups a long time ago (and by thought, I mean puzzled over it at a coffeshop once), so it was interesting to see what was known about the problem.
Sorting with adversarial comparators and application to density estimation
Jayadev Acharya (University of California, San Diego, USA); Ashkan Jafarpour (University of California, San Diego, USA); Alon Orlitsky (University of California, San Diego, USA); Ananda Theertha Suresh (University of California, San Diego, USA)
Ashkan gave this talk on a problem where you have  samples from an unknown distribution
samples from an unknown distribution  and a set of distributions
and a set of distributions  to compare against. You want to find the distribution that is closest in
to compare against. You want to find the distribution that is closest in  . One way to do this is via Scheffe tournament tht compares all pairs of distributions — this runs in time
. One way to do this is via Scheffe tournament tht compares all pairs of distributions — this runs in time  time. They show a method that runs in
time. They show a method that runs in  time by studying the structure of the comparators used in the sorting method. The motivation is that running comparisons can be expensive (especially if they involve human decisions) so we want to minimize the number of comparisons. The paper is significantly different than the talk, but I think it would definitely be interesting to those interested in discrete algorithms. The density estimation problem is really just a motivator — the sorting problem is far more general.
time by studying the structure of the comparators used in the sorting method. The motivation is that running comparisons can be expensive (especially if they involve human decisions) so we want to minimize the number of comparisons. The paper is significantly different than the talk, but I think it would definitely be interesting to those interested in discrete algorithms. The density estimation problem is really just a motivator — the sorting problem is far more general.

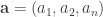


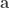
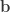
![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002)

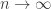
 representing some sensitive quantity are to be surveyed by an untrusted statistician. Concretely, suppose that the individual bits represent whether the person is a drug user or not. The statistician/surveyor wants to know the fraction
representing some sensitive quantity are to be surveyed by an untrusted statistician. Concretely, suppose that the individual bits represent whether the person is a drug user or not. The statistician/surveyor wants to know the fraction 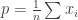 of users in the population. However, individuals don’t trust the surveyor. What to do?
of users in the population. However, individuals don’t trust the surveyor. What to do?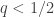 . The individual flips the coin in private. If it comes up heads, they lie and report
. The individual flips the coin in private. If it comes up heads, they lie and report  . If it comes up tails, they tell the truth
. If it comes up tails, they tell the truth  . The surveyor doesn’t see the outcome of the coin, but can compute the average of the
. The surveyor doesn’t see the outcome of the coin, but can compute the average of the  . What is the expected value of this average?
. What is the expected value of this average?![\mathbb{E}\left[ \frac{1}{n} \sum_{i=1}^{n} y_i \right] = \frac{1}{n} \sum_{i=1}^{n} (q (1 - x_i) + (1 -q) x_i) = q + (1 - 2q) p](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+y_i+%5Cright%5D+%3D+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+%28q+%281+-+x_i%29+%2B+%281+-q%29+x_i%29+%3D+q+%2B+%281+-+2q%29+p&bg=ffffff&fg=333333&s=0&c=20201002) .
. then estimate
then estimate  .
.
 , we can see that the protocol guarantees differential privacy. This gives a possibly friendlier interpretation of
, we can see that the protocol guarantees differential privacy. This gives a possibly friendlier interpretation of  in terms of the “lying probability”
in terms of the “lying probability”  . We can plot this:
. We can plot this:
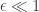 , but in practice this turns out to be quite difficult. Why so pessimistic? The differential privacy thread model is pretty pessimistic — it’s your plausible deniability given that everyone else in the data set has revealed their data to the surveyor “in the clear.” This is the fundamental tension in thinking about the practical implications of differential privacy — we don’t want to make conditional guarantees (“as long as everyone else is secret too”) but the price of an unconditional guarantee can be high in the worst case.
, but in practice this turns out to be quite difficult. Why so pessimistic? The differential privacy thread model is pretty pessimistic — it’s your plausible deniability given that everyone else in the data set has revealed their data to the surveyor “in the clear.” This is the fundamental tension in thinking about the practical implications of differential privacy — we don’t want to make conditional guarantees (“as long as everyone else is secret too”) but the price of an unconditional guarantee can be high in the worst case. and each test is the row or a matrix
and each test is the row or a matrix  -the entry of
-the entry of  -th item is part of the
-th item is part of the  -th group. The multiplication
-th group. The multiplication  is taken using Boolean OR. The twist in this paper is that they consider a situation where
is taken using Boolean OR. The twist in this paper is that they consider a situation where  elements can “pretend” to be positive in each test, with a possibly different group in each test. This is different than “noisy group testing” which was considered previously, which is more like
elements can “pretend” to be positive in each test, with a possibly different group in each test. This is different than “noisy group testing” which was considered previously, which is more like  . They show achievable rates for detecting the positives using random coding methods (i.e. a random
. They show achievable rates for detecting the positives using random coding methods (i.e. a random  strings
strings 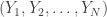 from an HMM, can we create a multilinear system whose outputs have the same joint distribution? A multilinear system looks like this:
from an HMM, can we create a multilinear system whose outputs have the same joint distribution? A multilinear system looks like this: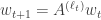 for
for 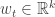 with
with 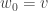

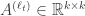 as the transition for state
as the transition for state  (e.g. a stochastic matrix) and we want the output to be
(e.g. a stochastic matrix) and we want the output to be 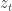 . This is sort of at the nexus of control/Markov chains and HMMs and uses some of the tensor ideas that are getting hot in machine learning. As the abstract puts it, the results are that they can efficiently construct realizations if
. This is sort of at the nexus of control/Markov chains and HMMs and uses some of the tensor ideas that are getting hot in machine learning. As the abstract puts it, the results are that they can efficiently construct realizations if 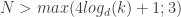 , where
, where  is the size of the output alphabet size, and
is the size of the output alphabet size, and 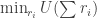
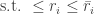

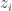 are private but the charging rates
are private but the charging rates  can be public. This is in contrast to the mechanism design literature popularized by Aaron Roth and collaborators. They do an analysis of a projected gradient descent procedure with Laplace noise added for differential privacy. It’s a stochastic gradient method but seems to converge in just a few time steps — clearly the number of iterations may impact the privacy parameter, but for the examples they showed it was only a handful of time steps.
can be public. This is in contrast to the mechanism design literature popularized by Aaron Roth and collaborators. They do an analysis of a projected gradient descent procedure with Laplace noise added for differential privacy. It’s a stochastic gradient method but seems to converge in just a few time steps — clearly the number of iterations may impact the privacy parameter, but for the examples they showed it was only a handful of time steps.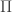 for computing a function
for computing a function  interactively, where Alice has
interactively, where Alice has  , Bob has
, Bob has  , and
, and  :
:
 on
on  during the protocol. The mechanism seeems a bit like communication with feedback a la Horstein, but I got a bit confused as to what was going on — basically it seems that Alice and Bob need to be able to agree on the estimate during the protocol and use a few extra bits added to the communication to maintain this estimate. If I had an extra
during the protocol. The mechanism seeems a bit like communication with feedback a la Horstein, but I got a bit confused as to what was going on — basically it seems that Alice and Bob need to be able to agree on the estimate during the protocol and use a few extra bits added to the communication to maintain this estimate. If I had an extra  where each codeword is a superposition of
where each codeword is a superposition of  columns, one each from groups of size
columns, one each from groups of size  . Thus encoding is
. Thus encoding is  where
where  is a sparse vector. I saw a talk by Barron and Joseph from a previous ISIT about this, but the framework extends to rate distortion (achieving the rate distortion function), and channel coding. The main point is to lower the complexity of the code at the expense of the gap to optimal rate — encoding and decoding are polynomial time but the rate gap for rate-distortion goes to zero as
is a sparse vector. I saw a talk by Barron and Joseph from a previous ISIT about this, but the framework extends to rate distortion (achieving the rate distortion function), and channel coding. The main point is to lower the complexity of the code at the expense of the gap to optimal rate — encoding and decoding are polynomial time but the rate gap for rate-distortion goes to zero as 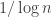 . Ramji gave a really nice and clear talk on this — I hope he puts the slides up!
. Ramji gave a really nice and clear talk on this — I hope he puts the slides up!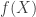 on
on  , we can define
, we can define  . The entropy is the expectation of this random variable, and the varentropy is the variance. Their main result is a upper bound on the varentropu of log concave distributions
. The entropy is the expectation of this random variable, and the varentropy is the variance. Their main result is a upper bound on the varentropu of log concave distributions 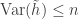 . This bound doesn’t depend on the distribution and is sharp if
. This bound doesn’t depend on the distribution and is sharp if  from its expectation, which gives a AEP that doesn’t really assume anything about the joint distribution of the variables except for log-concavity. There was more in the talk, but I eagerly await the paper.
from its expectation, which gives a AEP that doesn’t really assume anything about the joint distribution of the variables except for log-concavity. There was more in the talk, but I eagerly await the paper. a deletion more.
a deletion more. where
where  is the Shannon capacity of the DMC. In the broadcast setting we run into the problem that the errors for the two receivers are entangled. However, their message sets are disjoint. The way out is to look at the average error for each (averaged over the other user’s message). The main result is that the rates only depend on the conditional marginals, and they have a strong converse.
is the Shannon capacity of the DMC. In the broadcast setting we run into the problem that the errors for the two receivers are entangled. However, their message sets are disjoint. The way out is to look at the average error for each (averaged over the other user’s message). The main result is that the rates only depend on the conditional marginals, and they have a strong converse. such that the probabilities are non-increasing. The redundancy for this class is infinite, alas, so they restrict the support to size
such that the probabilities are non-increasing. The redundancy for this class is infinite, alas, so they restrict the support to size  -differential privacy yield better sample complexity results than
-differential privacy yield better sample complexity results than 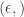 -differential privacy. This feels similar in flavor to a
-differential privacy. This feels similar in flavor to a  a marginal
a marginal 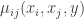 . If you want to create a rule
. If you want to create a rule 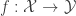 for classification, you might want to pick one that has best worst-case performance. One approach is to take the one which has best worst-case performance over all joint distributions on all variables that agree with the empirical marginals. This optimization looks hard because of the exponential number of variables, but they in fact show via convex duality and LP relaxations that it can be solved efficiently. To which I say: wow! More details are in the paper, but the proofs seem to be waiting for a journal version.
for classification, you might want to pick one that has best worst-case performance. One approach is to take the one which has best worst-case performance over all joint distributions on all variables that agree with the empirical marginals. This optimization looks hard because of the exponential number of variables, but they in fact show via convex duality and LP relaxations that it can be solved efficiently. To which I say: wow! More details are in the paper, but the proofs seem to be waiting for a journal version.