Logarithmic Sobolev inequalities and strong data processing theorems for discrete channels
Maxim Raginsky (University of Illinois at Urbana-Champaign, USA)
Max talked about how the strong data processing inequality (DPI) is basically a log-Sobolev inequality (LSI) that is used in measure concentration. The strong DPI says that
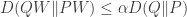
for some 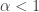 , so the idea is to get bounds on
, so the idea is to get bounds on
 .
.
What he does is construct a hierarchy of LSIs in which the strong DPI fits and then gets bounds on this ratio in terms of best constants for LSIs. The details are a bit hairy, and besides, Max has his own blog so he can write more about it if he wants…
Building Consensus via Iterative Voting
Farzad Farnoud (University of Illinois, Urbana-Champaign, USA); Eitan Yaakobi (Caltech, USA); Behrouz Touri (University of Illinois Urbana-Champaign, USA); Olgica Milenkovic (University of Illinois, USA); Jehoshua Bruck (California Institute of Technology, USA)
This paper was about rank aggregation, or how to take a bunch of votes expressed as permutations/rankings of options to produce a final option. The model is one in which people iteratively change their ranking based on the current ranking. For example, one could construct the pairwise comparison graph (a la Condorcet) and then have people change their rankings when they disagree with the majority on an edge. They show conditions under which this process converges (the graph should not have a cycle) and show that if there is a Condorcet winner, then after this process everyone will rank the Condorcet winner first. They also look at a Borda count version of this problem but to my eye that just looked like an average consensus method, but it was at the end of the talk so I might have missed something.
Information-Theoretic Study of Voting Systems
Eitan Yaakobi (Caltech, USA); Michael Langberg (Open University of Israel, Israel); Jehoshua Bruck (California Institute of Technology, USA)
Eitan gave this talk and the preceding talk. This one was about looking at voting through the lens of coding theory. The main issue is this — what sets of votes or distribution of vote profiles will lead to a Condorcet winner? Given a set of votes, one could look at the fraction of candidates who rank candidate j in the i-th position and then try to compute entropies of the resulting distributions. The idea is somehow to characterize the existence or lack of a Condorcet winner in terms of distances (Kendall tau) and these entropy measures. This is different than looking at probability distributions on permutations and asking about the probability of there existing a Condorcet cycle.
Brute force searching, the typical set and Guesswork
Mark Chirstiansen (National University of Ireland Maynooth, Ireland); Ken R Duffy (National University of Ireland Maynooth, Ireland); Flávio du Pin Calmon (Massachusetts Institute of Technology, USA); Muriel Médard (MIT, USA)
Suppose an item  is chosen
is chosen 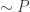 from a list and we want to guess the choice that is made. We’re only allowed to ask questions of the form “is the item
from a list and we want to guess the choice that is made. We’re only allowed to ask questions of the form “is the item  ?” Suppose now that the list is a list of codewords of blocklength
?” Suppose now that the list is a list of codewords of blocklength  drawn i.i.d. according to
drawn i.i.d. according to  . This paper looks at the number of guesses one needs if
. This paper looks at the number of guesses one needs if  is uniform on the typical set according to versus when is distributed according the distribution
is uniform on the typical set according to versus when is distributed according the distribution 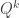 conditioned on being in the typical set. The non-uniformity of the latter turns out to make the guessing problem a lot easier.
conditioned on being in the typical set. The non-uniformity of the latter turns out to make the guessing problem a lot easier.
Rumor Source Detection under Probabilistic Sampling
Nikhil Karamchandani (University of California Los Angeles, USA); Massimo Franceschetti (University of California at San Diego, USA)
This paper looked at an SI model of infection on a graph — nodes are either Susceptible (S) or Infected (I), and there is a probability of transitioning from S to I based on your neighbors’ states. There in exponential waiting time 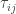 for the
for the  to infect
to infect  if is infected. The idea is that the rumor starts somewhere and infects a bunch of people and then you get to observe/measure the network. You want to find the source. This was studied by Zaman and Shah under the assumption of perfect observation of all nodes. This work looked at the case where nodes randomly report their infection state, so you only get an incomplete picture of the infection state. They characterize the effect of the reporting probability on the excess error and show that for certain tree graphs, incomplete reporting is as good as full reporting.
if is infected. The idea is that the rumor starts somewhere and infects a bunch of people and then you get to observe/measure the network. You want to find the source. This was studied by Zaman and Shah under the assumption of perfect observation of all nodes. This work looked at the case where nodes randomly report their infection state, so you only get an incomplete picture of the infection state. They characterize the effect of the reporting probability on the excess error and show that for certain tree graphs, incomplete reporting is as good as full reporting.
pairs of cards. The cards in each pair are identical. The deck is shuffled and the cards laid face down. A move consists of flipping over first one card and then another. The cards are removed from play if they match. Otherwise, they are flipped back over and the next move commences. A game ends when all pairs have been matched. We determine that, when the game is played optimally, as
.
.
.

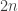

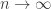
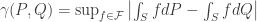
 is a measurable space on which
is a measurable space on which  is a class of real-valued bounded measurable functions on
is a class of real-valued bounded measurable functions on  -divergences (also known as Ali-Silvey distances), but does contain the total variational distance.
-divergences (also known as Ali-Silvey distances), but does contain the total variational distance. converges if we have to estimate it from samples of
converges if we have to estimate it from samples of ![\{p_i : i \in [n]\}](https://s0.wp.com/latex.php?latex=%5C%7Bp_i+%3A+i+%5Cin+%5Bn%5D%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) . For some given
. For some given ![p \in [\epsilon,1-\epsilon]](https://s0.wp.com/latex.php?latex=p+%5Cin+%5B%5Cepsilon%2C1-%5Cepsilon%5D&bg=ffffff&fg=333333&s=0&c=20201002) and
and 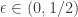 , each coin is “heavy” (
, each coin is “heavy” (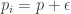 ) with probability
) with probability  and “light” (
and “light” (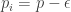 ) with probability
) with probability 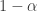 . The goal is to use a sequential flipping strategy to find a heavy coin with probability at least
. The goal is to use a sequential flipping strategy to find a heavy coin with probability at least  .
.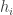 heads and
heads and  tails, then the likelihood ratio is
tails, then the likelihood ratio is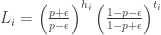
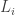 so far (breaking ties arbitrarily).
so far (breaking ties arbitrarily). . These appear in the stopping criterion. The algorithm keeps flipping coins until there exists at least one $i$ for which
. These appear in the stopping criterion. The algorithm keeps flipping coins until there exists at least one $i$ for which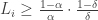
 heads and tails for a coin $i$,
heads and tails for a coin $i$,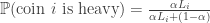 ,
,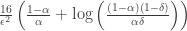
 (plus lower-order terms), since that is the maximum possible expected hitting time for a random walk on an n-vertex graph [2]; the same bound applies to the random cop [4]. It is easy to see that the greedy cop who merely moves toward the drunk at every step can achieve
(plus lower-order terms), since that is the maximum possible expected hitting time for a random walk on an n-vertex graph [2]; the same bound applies to the random cop [4]. It is easy to see that the greedy cop who merely moves toward the drunk at every step can achieve 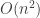 ; in fact, we will show that the greedy cop cannot in general do better. Our smart cop, however, gets her man in expected time
; in fact, we will show that the greedy cop cannot in general do better. Our smart cop, however, gets her man in expected time 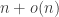 .
.
 -user interference channel with gains
-user interference channel with gains  between transmitter
between transmitter 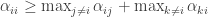
 bins/categories (days), how big should
bins/categories (days), how big should 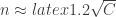 , as we know, but we can expand this to deal with approximate matches (you need only 7 people to get 2 birthdays in the same week with probability around 1/2). If you want to put a graph on it you can ask social-network coincidence questions and get some scalings as a function of the number of edges and number of categories — here there are
, as we know, but we can expand this to deal with approximate matches (you need only 7 people to get 2 birthdays in the same week with probability around 1/2). If you want to put a graph on it you can ask social-network coincidence questions and get some scalings as a function of the number of edges and number of categories — here there are  which I had found interesting:
which I had found interesting: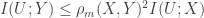 .
. , but by another quantity:
, but by another quantity:
 is given by the following definition.
is given by the following definition. . We define
. We define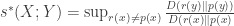 ,
, denotes the
denotes the  -marginal distribution of
-marginal distribution of  and the supremum on the right hand side is over all probability distributions
and the supremum on the right hand side is over all probability distributions 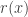 that are different from the probability distribution
that are different from the probability distribution  . If either
. If either  to be 0.
to be 0.
 have joint distribution
have joint distribution  (I know I am changing notation here but it’s easier to explain). The key to showing their result is through deriving variational characterizations of
(I know I am changing notation here but it’s easier to explain). The key to showing their result is through deriving variational characterizations of 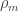 and
and 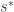 in terms of the function
in terms of the function
 , and
, and 
 ? If either
? If either 
 . However,
. However, 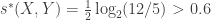 and there exists a sequence of variables
and there exists a sequence of variables  satisfying the Markov chain such that
satisfying the Markov chain such that  such that the ratio approaches
such that the ratio approaches 