Logarithmic Sobolev inequalities and strong data processing theorems for discrete channels
Maxim Raginsky (University of Illinois at Urbana-Champaign, USA)
Max talked about how the strong data processing inequality (DPI) is basically a log-Sobolev inequality (LSI) that is used in measure concentration. The strong DPI says that
for some 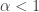

What he does is construct a hierarchy of LSIs in which the strong DPI fits and then gets bounds on this ratio in terms of best constants for LSIs. The details are a bit hairy, and besides, Max has his own blog so he can write more about it if he wants…
Building Consensus via Iterative Voting
Farzad Farnoud (University of Illinois, Urbana-Champaign, USA); Eitan Yaakobi (Caltech, USA); Behrouz Touri (University of Illinois Urbana-Champaign, USA); Olgica Milenkovic (University of Illinois, USA); Jehoshua Bruck (California Institute of Technology, USA)
This paper was about rank aggregation, or how to take a bunch of votes expressed as permutations/rankings of options to produce a final option. The model is one in which people iteratively change their ranking based on the current ranking. For example, one could construct the pairwise comparison graph (a la Condorcet) and then have people change their rankings when they disagree with the majority on an edge. They show conditions under which this process converges (the graph should not have a cycle) and show that if there is a Condorcet winner, then after this process everyone will rank the Condorcet winner first. They also look at a Borda count version of this problem but to my eye that just looked like an average consensus method, but it was at the end of the talk so I might have missed something.
Information-Theoretic Study of Voting Systems
Eitan Yaakobi (Caltech, USA); Michael Langberg (Open University of Israel, Israel); Jehoshua Bruck (California Institute of Technology, USA)
Eitan gave this talk and the preceding talk. This one was about looking at voting through the lens of coding theory. The main issue is this — what sets of votes or distribution of vote profiles will lead to a Condorcet winner? Given a set of votes, one could look at the fraction of candidates who rank candidate j in the i-th position and then try to compute entropies of the resulting distributions. The idea is somehow to characterize the existence or lack of a Condorcet winner in terms of distances (Kendall tau) and these entropy measures. This is different than looking at probability distributions on permutations and asking about the probability of there existing a Condorcet cycle.
Brute force searching, the typical set and Guesswork
Mark Chirstiansen (National University of Ireland Maynooth, Ireland); Ken R Duffy (National University of Ireland Maynooth, Ireland); Flávio du Pin Calmon (Massachusetts Institute of Technology, USA); Muriel Médard (MIT, USA)
Suppose an item 




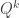
Rumor Source Detection under Probabilistic Sampling
Nikhil Karamchandani (University of California Los Angeles, USA); Massimo Franceschetti (University of California at San Diego, USA)
This paper looked at an SI model of infection on a graph — nodes are either Susceptible (S) or Infected (I), and there is a probability of transitioning from S to I based on your neighbors’ states. There in exponential waiting time