A postdoctoral position is available at the University of Michigan Electrical Engineering and Computer Science Department for a project related to anomaly detection in networked cyber-physical systems. The successful applicant will have knowledge in one or more of the following topics: convex optimization and relaxations, compressed sensing, distributed optimization, submodularity, control and dynamical systems or system identification. The project will cover both theory and algorithm development and some practical applications in fault and attack detection in transportation and energy networks. The position can start anytime in 2014 or early 2015. This is a one year position, renewable for a second year. Interested candidates should contact Necmiye Ozay at necmiye@umich.edu with a CV and some pointers to representative publications.
Tag Archives: control
Some (not-so-)recent hits from ArXiV
I always end up bookmarking a bunch of papers from ArXiV and then looking at them a bit later than I want. So here are a few notes on some papers from the last month. I have a backlog of reading to catch up on, so I’ll probably split this into a couple of posts.
arXiv:1403.3465v1 [cs.LG]: Analysis Techniques for Adaptive Online Learning
H. Brendan McMahan
This is a nice survey on online learning/optimization algorithms that adapt to the data. These are all variants of the Follow-The-Regularized-Leader algorithms. The goal is to provide a more unified analysis of online algorithms where the regularization is data dependent. The intuition (as I see it) is that you’re doing a kind of online covariance estimation and then regularizing with respect to the distribution as you are learning it. Examples include the McMahan and Streeter (2010) paper and the Duchi et al. (2011) paper. Such adaptive regularizers also appear in dual averaging methods, where they are called “prox-functions.” This is a useful survey, especially if, like me, you’ve kind of checked in and out with the online learning literature and so may be missing the forest for the trees. Or is that the FoReL for the trees?
arXiv:1403.4011 [cs.IT]: Whose Opinion to follow in Multihypothesis Social Learning? A Large Deviation Perspective
Wee Peng Tay
This is a sort of learning from expert advice problem, though not in the setting that machine learners would consider it. The more control-oriented folks would recognize it as a multiple-hypothesis test. The model is that there is a single agent (agent 

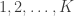

![Y_k[1], Y_k[2], \ldots, Y_k[n_k]](https://s0.wp.com/latex.php?latex=Y_k%5B1%5D%2C+Y_k%5B2%5D%2C+%5Cldots%2C+Y_k%5Bn_k%5D&bg=ffffff&fg=333333&s=0&c=20201002)


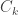
arXiv:1403.3862 [math.OC] Asynchronous Stochastic Coordinate Descent: Parallelism and Convergence Properties
Ji Liu, Stephen J. Wright
This is another paper on lock-free optimization (c.f. HOGWILD!). The key difference, as stated in the introduction, is that they “do not assume that the evaluation vector 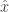

Allerton 2012 : Karl J. Åström’s Jubilee Lecture
It’s the fall again, and this year it is the 50th anniversary of the Allerton Conference. Tonight was a special Golden Jubilee lecture by Karl Johan Åström from the Lund University. He gave an engaging view of the pre-history, history, present, and future of control systems. Control is a “hidden technology” he said — it’s everywhere and is what makes all the technology that we use work, but remains largely unknown and unnoticed except during catastrophic failures. He exhorted the young’uns to do a better job at letting people know how important control systems are in everyday life.
The main message of Åström’s talk is that control theory and control practice need to get back together so that we can develop new control theories for emerging areas, including biology and physics. He called this the “holistic” view and pointed out that it really emerged out of the war effort during WWII, when control systems had to be developed for all sorts of military tasks. This got the mathematicians in the same room as the “real” engineers, and led to a lot of new theory. I guess I had always known that was a big driver, but I guess I hadn’t thought of how control really was the glue that tied things together.
Postdoc at Cornell in smart grid, learning, optimization and control
Applicants are sought for postdoctoral scholar position(s) at Cornell University in the areas of smart grid, learning, optimization, and control. Topics include, but are not limited to,
- the economics and operation of power systems with significant penetration of intermittent renewables.
- stochastic optimization, learning, game theory, mechanism design, and their applications.
- inference and control involving heavy tail distributions.
Successful candidates will participate in research activities led by Professors Lang Tong and/or Eilyan Bitar.
To apply, please send your CV, two recent papers, and 2-3 names references to Lang Tong (ltong@ece.cornell.edu) and Eilyan Bitar (eyb5@cornell.edu).
ITA Workshop 2012 : Talks
The ITA Workshop finished up today, and I know I promised some blogging, but my willpower to take notes kind of deteriorated during the week. For today I’ll put some pointers to talks I saw today which were interesting. I realize I am heavily blogging about Berkeley folks here, but you know, they were interesting talks!
Nadia Fawaz talked about differential privacy for continuous observations : in this model you see 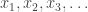

David Tse gave an interesting talk about sequencing DNA via short reads as a communication problem. I had actually had some thoughts along these lines earlier because I am starting to collaborate with my friend Tony Chiang on some informatics problems around next generation sequencing. David wanted to know how many (noiseless) reads 



Michael Jordan talked about the “big data bootstrap” (paper here). You have 

Anant Sahai talked about how to look at some decentralized linear control problems as implicitly doing some sort of network coding in the deterministic model. One way to view this is to identify unstable modes in the plant as communicating with each other using the controllers as relays in the network. By structurally massaging the control problem into a canonical form, they can make this translation a bit more formal and can translate results about linear stabilization from the 80s into max-flow min-cut type results for network codes. This is mostly work by Se Yong Park, who really ought to have a more complete webpage.
Paolo Minero talked about controlling a linear plant over a rate-limited communication link whose capacity evolves according to a Markov chain. What are the conditions on the rate to ensure stability? He made a connection to Markov jump linear systems that gives the answer in the scalar case, but the necessary and sufficient conditions in the vector case don’t quite match. I always like seeing these sort of communication and control results, even though I don’t work in this area at all. They’re just cool.
There were three talks on consensus in the morning, which I will only touch on briefly. Behrouz Touri gave a talk about part of his thesis work, which was on the Hegselman-Krause opinion dynamics model. It’s not possible to derive a Lyapunov function for this system, but he found a time-varying Lyapunov function, leading to an analysis of the convergence which has some nice connections to products of random stochastic matrices and other topics. Ali Jadbabaie talked about work with Pooya Molavi on non-Bayesian social learning, which combines local Bayesian updating with DeGroot consensus to do distributed learning of a parameter in a network. He had some new sufficient conditions involving disconnected networks that are similar in flavor to his preprint. José Moura talked about distributed Kalman filtering and other consensus meets sensing (consensing?) problems. The algorithms are similar to ones I’ve been looking at lately, so I will have to dig a bit deeper into the upcoming IT Transactions paper.
Linkage
I never knew Jell-O could be so graceful.
I kind of like this version of Take Five from Sachal Music.
Sometimes the Library of Congress does awesome things. This jukebox is up there.
I wouldn’t have believed before that there is money in a bannass stand, but I could be wrong.
The clarity in this press nugget leaves a lot to be desired. The statement “the trio has found a way to determine the smallest number of nodes that must be externally controlled to force a given network from any initial state to any desired final state,” is so vague! The full article is here. It turns out they are looking at a linear control problem 


Wiener on control versus learning
I’ve seen this quote excerpted in parts before, but not the whole thing:
I repeat, feedback is a method for controlling a system by reinserting into it the results of its past performance. If these results are merely used as numerical data for the criticism of the system and its regulation, we have the simple feedback of the control engineers. If, however, the information which proceeds backward from the performance is able to change the general method and pattern of performance, we have a process which may well be called learning.
– Norbert Wiener, The Human Use of Human Beings
It is a strange distinction Wiener is trying to make here. First, Wiener tries to make “numerical data” a simple special case, and equates control as the manipulation of numerical data. However, he doesn’t contrast numbers with something else (presumably non-numerical) which can “change the general method and pattern.” Taking it from the other direction, he implies that mere control engineering cannot accomplish “learning.” That is, from numerical data and “criticism of the system” we cannot change how the system works. By Wiener’s lights, pretty much all of the work in mathematical control and machine learning would be classified as control.
I am, of course, missing the context in which Wiener was writing. But I’m not sure what I’m missing. For example, at the time a “control engineer” may have been more of a regulator, so in the first case Wiener may be referring to putting a human in the loop. In the book he makes a distinction between data and algorithms (the “taping”) which has been fuzzed up by computer science. If this distinction leads to drawing a line between control and learning, then is there a distinction between control and learning?
The Information Structuralist
Welcome to Max Raginsky’s new blog, The Information Structuralist, which in two weeks has already produced more useful content than this poor blog does in several months.
Allerton deadline extended
According to the website, the 2010 Allerton deadline has been extended by three weeks to July 7. Many ISIT attendees may breathe a collective sigh of relief.
