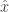I always end up bookmarking a bunch of papers from ArXiV and then looking at them a bit later than I want. So here are a few notes on some papers from the last month. I have a backlog of reading to catch up on, so I’ll probably split this into a couple of posts.
arXiv:1403.3465v1 [cs.LG]: Analysis Techniques for Adaptive Online Learning
H. Brendan McMahan
This is a nice survey on online learning/optimization algorithms that adapt to the data. These are all variants of the Follow-The-Regularized-Leader algorithms. The goal is to provide a more unified analysis of online algorithms where the regularization is data dependent. The intuition (as I see it) is that you’re doing a kind of online covariance estimation and then regularizing with respect to the distribution as you are learning it. Examples include the McMahan and Streeter (2010) paper and the Duchi et al. (2011) paper. Such adaptive regularizers also appear in dual averaging methods, where they are called “prox-functions.” This is a useful survey, especially if, like me, you’ve kind of checked in and out with the online learning literature and so may be missing the forest for the trees. Or is that the FoReL for the trees?
arXiv:1403.4011 [cs.IT]: Whose Opinion to follow in Multihypothesis Social Learning? A Large Deviation Perspective
Wee Peng Tay
This is a sort of learning from expert advice problem, though not in the setting that machine learners would consider it. The more control-oriented folks would recognize it as a multiple-hypothesis test. The model is that there is a single agent (agent 

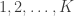

![Y_k[1], Y_k[2], \ldots, Y_k[n_k]](https://s0.wp.com/latex.php?latex=Y_k%5B1%5D%2C+Y_k%5B2%5D%2C+%5Cldots%2C+Y_k%5Bn_k%5D&bg=ffffff&fg=333333&s=0&c=20201002)


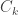
arXiv:1403.3862 [math.OC] Asynchronous Stochastic Coordinate Descent: Parallelism and Convergence Properties
Ji Liu, Stephen J. Wright
This is another paper on lock-free optimization (c.f. HOGWILD!). The key difference, as stated in the introduction, is that they “do not assume that the evaluation vector