[Update: As Max points out in the comments, this is really a specialized version of the Donsker-Varadhan formula, also mentioned by Mokshay in a comment here. I think the difficulty with concepts like these is that they are true for deeper reasons than the ones given when you learn them — this is a special case that requires undergraduate probability and calculus, basically.]
One of my collaborators said to me recently that it’s well known that the “negative entropy is the Fenchel dual of the log-partition function.” Now I know what these words meant, but it somehow was not a fact that I had learned elsewhere, and furthermore, a sentence like that is frustratingly terse. If you already know what it means, then it’s a nice shorthand, but for those trying to figure it out, it’s impenetrable jargon. I tried running it past a few people here who are generally knowledgeable but are not graphical model experts, and they too were unfamiliar with it. While this is just a simple thing about conjugate duality, I think it doesn’t really show up in information theory classes unless the instructor talks a bit more about exponential family distributions, maximum entropy distributions, and other related concepts. Bert Huang has a post on Jensen’s inequality as a justification.
We have a distribution in the exponential family:

As a side note, I often find that the exponential family is not often covered in systems EE courses. Given how important it is in statistics, I think it should be a bit more of a central concept — I’m definitely going to try and work it in to the detection and estimation course.
For the purposes of this post I’m going to assume 
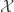
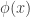



Where the partition function is

The entropy of the distribution is easy to calculate:
![H(p) = \mathbb{E}[ - \log p(x; \theta) ] = A(\theta) - \langle \theta, \mathbb{E}[\phi(x)] \rangle](https://s0.wp.com/latex.php?latex=H%28p%29+%3D+%5Cmathbb%7BE%7D%5B+-+%5Clog+p%28x%3B+%5Ctheta%29+%5D+%3D+A%28%5Ctheta%29+-+%5Clangle+%5Ctheta%2C+%5Cmathbb%7BE%7D%5B%5Cphi%28x%29%5D+%5Crangle&bg=ffffff&fg=333333&s=0&c=20201002)
The Fenchel dual of a function 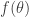
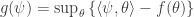
So what’s the Fenchel dual of the log partition function? We have to take the gradient:
![\nabla_{\theta} \left( \langle \psi, \theta \rangle - A(\theta) \right) = \psi - \frac{1}{Z(\theta)} \sum_{x} \exp( \langle \theta, \phi(x) \rangle ) \phi(x) = \psi - \mathbb{E}[ \phi(x) ]](https://s0.wp.com/latex.php?latex=%5Cnabla_%7B%5Ctheta%7D+%5Cleft%28+%5Clangle+%5Cpsi%2C+%5Ctheta+%5Crangle+-+A%28%5Ctheta%29+%5Cright%29+%3D+%5Cpsi+-+%5Cfrac%7B1%7D%7BZ%28%5Ctheta%29%7D+%5Csum_%7Bx%7D+%5Cexp%28+%5Clangle+%5Ctheta%2C+%5Cphi%28x%29+%5Crangle+%29+%5Cphi%28x%29+%3D+%5Cpsi+-+%5Cmathbb%7BE%7D%5B+%5Cphi%28x%29+%5D&bg=ffffff&fg=333333&s=0&c=20201002)
So now setting this equal to zero, we see that at the optimum 
![\langle \psi, \theta^* \rangle = \langle \mathbb{E}[ \phi(x) ], \theta^* \rangle](https://s0.wp.com/latex.php?latex=%5Clangle+%5Cpsi%2C+%5Ctheta%5E%2A+%5Crangle+%3D+%5Clangle+%5Cmathbb%7BE%7D%5B+%5Cphi%28x%29+%5D%2C+%5Ctheta%5E%2A+%5Crangle&bg=ffffff&fg=333333&s=0&c=20201002)
And the dual function is:
![g(\psi) = \langle \mathbb{E}[ \phi(x) ], \theta^* \rangle - A(\theta^*) = - H(p)](https://s0.wp.com/latex.php?latex=g%28%5Cpsi%29+%3D+%5Clangle+%5Cmathbb%7BE%7D%5B+%5Cphi%28x%29+%5D%2C+%5Ctheta%5E%2A+%5Crangle+-+A%28%5Ctheta%5E%2A%29+%3D+-+H%28p%29&bg=ffffff&fg=333333&s=0&c=20201002)
The standard approach seems to go the other direction by computing the dual of the negative entropy, but that seems more confusing to me (perhaps inspiring Bert’s post above). Since the log partition function and negative entropy are both convex, it seems easier to exploit the duality to prove it in one direction only.
 : New Jersey driver
: New Jersey driver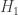 : New York driver
: New York driver be a binary variable indicating whether or not I observe dangerous driving behavior. Based on my entirely subjective experience, I would say the in terms of likelihoods,
be a binary variable indicating whether or not I observe dangerous driving behavior. Based on my entirely subjective experience, I would say the in terms of likelihoods,
 from New Jersey and New York, respectively, I would have to say
from New Jersey and New York, respectively, I would have to say
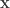 and each test is the row or a matrix
and each test is the row or a matrix  : the
: the  -the entry of
-the entry of  -th item is part of the
-th item is part of the  -th group. The multiplication
-th group. The multiplication  is taken using Boolean OR. The twist in this paper is that they consider a situation where
is taken using Boolean OR. The twist in this paper is that they consider a situation where  elements can “pretend” to be positive in each test, with a possibly different group in each test. This is different than “noisy group testing” which was considered previously, which is more like
elements can “pretend” to be positive in each test, with a possibly different group in each test. This is different than “noisy group testing” which was considered previously, which is more like  . They show achievable rates for detecting the positives using random coding methods (i.e. a random
. They show achievable rates for detecting the positives using random coding methods (i.e. a random  strings
strings 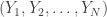 from an HMM, can we create a multilinear system whose outputs have the same joint distribution? A multilinear system looks like this:
from an HMM, can we create a multilinear system whose outputs have the same joint distribution? A multilinear system looks like this: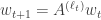 for
for 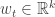 with
with 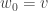

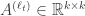 as the transition for state
as the transition for state  (e.g. a stochastic matrix) and we want the output to be
(e.g. a stochastic matrix) and we want the output to be 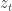 . This is sort of at the nexus of control/Markov chains and HMMs and uses some of the tensor ideas that are getting hot in machine learning. As the abstract puts it, the results are that they can efficiently construct realizations if
. This is sort of at the nexus of control/Markov chains and HMMs and uses some of the tensor ideas that are getting hot in machine learning. As the abstract puts it, the results are that they can efficiently construct realizations if 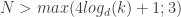 , where
, where  is the size of the output alphabet size, and
is the size of the output alphabet size, and  is the minimal order of the realization.”
is the minimal order of the realization.”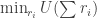
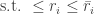

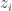 are private but the charging rates
are private but the charging rates  can be public. This is in contrast to the mechanism design literature popularized by Aaron Roth and collaborators. They do an analysis of a projected gradient descent procedure with Laplace noise added for differential privacy. It’s a stochastic gradient method but seems to converge in just a few time steps — clearly the number of iterations may impact the privacy parameter, but for the examples they showed it was only a handful of time steps.
can be public. This is in contrast to the mechanism design literature popularized by Aaron Roth and collaborators. They do an analysis of a projected gradient descent procedure with Laplace noise added for differential privacy. It’s a stochastic gradient method but seems to converge in just a few time steps — clearly the number of iterations may impact the privacy parameter, but for the examples they showed it was only a handful of time steps. for computing a function
for computing a function  interactively, where Alice has
interactively, where Alice has  , Bob has
, Bob has  :
:
 on
on  -tuples of variables
-tuples of variables  -accurately approaches the minimum information complexity over all protocols for computing
-accurately approaches the minimum information complexity over all protocols for computing  during the protocol. The mechanism seeems a bit like communication with feedback a la Horstein, but I got a bit confused as to what was going on — basically it seems that Alice and Bob need to be able to agree on the estimate during the protocol and use a few extra bits added to the communication to maintain this estimate. If I had an extra
during the protocol. The mechanism seeems a bit like communication with feedback a la Horstein, but I got a bit confused as to what was going on — basically it seems that Alice and Bob need to be able to agree on the estimate during the protocol and use a few extra bits added to the communication to maintain this estimate. If I had an extra 
