November 11
London, UK
Colocated with CCS 2019
Differential privacy is a promising approach to privacy-preserving data analysis. Differential privacy provides strong worst-case guarantees about the harm that a user could suffer from participating in a differentially private data analysis, but is also flexible enough to allow for a wide variety of data analyses to be performed with a high degree of utility. Having already been the subject of a decade of intense scientific study, it has also now been deployed in products at government agencies such as the U.S. Census Bureau and companies like Apple and Google.
Researchers in differential privacy span many distinct research communities, including algorithms, computer security, cryptography, databases, data mining, machine learning, statistics, programming languages, social sciences, and law. This workshop will bring researchers from these communities together to discuss recent developments in both the theory and practice of differential privacy.
Specific topics of interest for the workshop include (but are not limited to):
- theory of differential privacy,
- differential privacy and security,
- privacy preserving machine learning,
- differential privacy and statistics,
- differential privacy and data analysis,
- trade-offs between privacy protection and analytic utility,
- differential privacy and surveys,
- programming languages for differential privacy,
- relaxations of the differential privacy definition,
- differential privacy vs other privacy notions and methods,
- experimental studies using differential privacy,
- differential privacy implementations,
- differential privacy and policy making,
- applications of differential privacy.
Submissions
The goal of TPDP is to stimulate the discussion on the relevance of differentially private data analyses in practice. For this reason, we seek contributions from different research areas of computer science and statistics. Authors are invited to submit a short abstract (4 pages maximum) of their work. Submissions will undergo a lightweight review process and will be judged on originality, relevance, interest and clarity. Submission should describe novel work or work that has already appeared elsewhere but that can stimulate the discussion between different communities at the workshop. Accepted abstracts will be presented at the workshop either as a talk or a poster. The workshop will not have formal proceedings and is not intended to preclude later publication at another venue. Selected papers from the workshop will be invited to submit a full version of their work for publication in a special issue of the Journal of Privacy and Confidentiality.
Submission website: https://easychair.org/conferences/?conf=tpdp2019
Important Dates
Submission: June 21 (anywhere on earth)
Notification: August 9
Workshop: 11/11
Program Committee
- Michael Hay (co-chair), Colgate University
- Aleksandar Nikolov (co-chair), University of Toronto
- Aws Albarghouthi, University of Wisconsin–Madison
- Borja Balle, Amazon
- Mark Bun, Boston University
- Graham Cormode, University of Warwick
- Rachel Cummings, Georgia Tech University
- Xi He, University of Waterloo
- Gautam Kamath, University of Waterloo
- Ilya Mironov, Google Research – Brain
- Uri Stemmer, Ben-Gurion University
- Danfeng Zhang, Penn State University
For more information, visit the workshop website at https://tpdp.cse.buffalo.edu/2019/.
 -node graph (c.f. a graphical model) representing the joint distribution on
-node graph (c.f. a graphical model) representing the joint distribution on  or
or 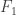 . At each time you get to observe the data from only one node of the graph. You can either observe the same node as before, explore by observing a different node, or make a decision about whether the data from from
. At each time you get to observe the data from only one node of the graph. You can either observe the same node as before, explore by observing a different node, or make a decision about whether the data from from  , where
, where  (say a Bernoulli-Gaussian prior). The question is what happens when we do estimation assuming a different prior
(say a Bernoulli-Gaussian prior). The question is what happens when we do estimation assuming a different prior  . The main result of the paper is an analysis of the excess MSE using a decoupling principle. Since I don’t really know anything about the replica method (except the name “replica method”), I had a little bit of a hard time following the talk as a non-expert, but thankfully there were a number of pictures and examples to help me follow along.
. The main result of the paper is an analysis of the excess MSE using a decoupling principle. Since I don’t really know anything about the replica method (except the name “replica method”), I had a little bit of a hard time following the talk as a non-expert, but thankfully there were a number of pictures and examples to help me follow along. targets
targets  uniformly distributed in the unit interval, and what we can do is query at each time
uniformly distributed in the unit interval, and what we can do is query at each time ![S_n \subseteq [0,1]](https://s0.wp.com/latex.php?latex=S_n+%5Csubseteq+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) and get a response
and get a response  where
where  and
and  where
where  is the Lebesgue measure. So basically you can query a set and you get a noisy indicator of whether you hit any targets, where the noise depends on the size of the set you query. At some point
is the Lebesgue measure. So basically you can query a set and you get a noisy indicator of whether you hit any targets, where the noise depends on the size of the set you query. At some point  you stop and guess the target locations. You are
you stop and guess the target locations. You are  successful if the probability that you are within
successful if the probability that you are within  of each target is less than
of each target is less than  . The targeting rate is the limit of
. The targeting rate is the limit of ![\log(1/\delta) / \mathbb{E}[\tau]](https://s0.wp.com/latex.php?latex=%5Clog%281%2F%5Cdelta%29+%2F+%5Cmathbb%7BE%7D%5B%5Ctau%5D&bg=ffffff&fg=333333&s=0&c=20201002) as
as  (I’m being fast and loose here). Clearly there are some connections to group testing and communication with feedback, etc. They show there is a significant gap between the adaptive and nonadaptive rate here, so you can find more targets if you can adapt your queries on the fly. However, since rate is defined for a fixed number of targets, we could ask how the gap varies with
(I’m being fast and loose here). Clearly there are some connections to group testing and communication with feedback, etc. They show there is a significant gap between the adaptive and nonadaptive rate here, so you can find more targets if you can adapt your queries on the fly. However, since rate is defined for a fixed number of targets, we could ask how the gap varies with  and
and  if the corresponding entry
if the corresponding entry 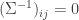 in the inverse covariance matrix. They show a relationship between the KL divergence of two distributions and their corresponding graphs. The divergence is lower bounded by a constant if they differ in a single edge — this indicates that estimating the edge structure is important when estimating the distribution.
in the inverse covariance matrix. They show a relationship between the KL divergence of two distributions and their corresponding graphs. The divergence is lower bounded by a constant if they differ in a single edge — this indicates that estimating the edge structure is important when estimating the distribution.![\mathbb{E}[ \ell(W, \hat{W}) ]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+%5Cell%28W%2C+%5Chat%7BW%7D%29+%5D&bg=ffffff&fg=333333&s=0&c=20201002) of a
of a  -dimensional parameter
-dimensional parameter  which is observed noisily by separate encoders. Think of a CEO-style problem where there is a conditional distribution
which is observed noisily by separate encoders. Think of a CEO-style problem where there is a conditional distribution  such that the observation at each node is a
such that the observation at each node is a  matrix whose columns are i.i.d. and where the
matrix whose columns are i.i.d. and where the  . Each sensor gets independent observations from the same model and can compress its observations to
. Each sensor gets independent observations from the same model and can compress its observations to  bits and sends it over independent channels to an estimator (so no MAC here). The main result is a lower bound on the expected loss as s function of the number of bits latex
bits and sends it over independent channels to an estimator (so no MAC here). The main result is a lower bound on the expected loss as s function of the number of bits latex 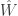 . The key is to use the strong data processing inequality to handle the mutual information — the constants that make up the ratio between the mutual informations is important. I’m sure Max will blog more about the result so I’ll leave a full explanation to him (see what I did there?)
. The key is to use the strong data processing inequality to handle the mutual information — the constants that make up the ratio between the mutual informations is important. I’m sure Max will blog more about the result so I’ll leave a full explanation to him (see what I did there?) , then you can take the Fourier transform
, then you can take the Fourier transform  of
of  . This turns out to be a probability distribution, so you can sample random
. This turns out to be a probability distribution, so you can sample random  i.i.d. and build a randomized Fourier approximation of
i.i.d. and build a randomized Fourier approximation of  -Regularized M-Estimators
-Regularized M-Estimators