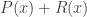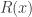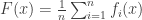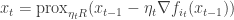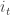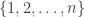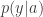I’ll round out the end of my ISIT blogging with very brief takes on a few more papers. I took it pretty casually this year in terms of note taking, and while I attended many more talks, my notes for most of them consist of a title and a star next to the ones where I want to look at the paper more closely. That’s probably closer to how most people attend conferences, only they probably use the proceedings book. I actually ended up shredding the large book of abstracts to use as bedding for my vermicompost (I figured they might appreciate eating a little Turkish paper for a change of diet).
On Connectivity Thresholds in Superposition of Random Key Graphs on Random Geometric Graphs
B Santhana Krishnan (Indian Institute of Technology, Bombay, India); Ayalvadi Ganesh (University of Bristol, United Kingdom); D. Manjunath (IIT Bombay, India)
This looked at a model where you have a random geometric graph (RGG) together with a uniformly chosen random subset  of
of  of size
of size 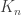 at each node. The subset is the set of keys available at each node; two nodes can talk (securely) if they share a key in common. We keep the edge in the RGG is if the link can be secured. The question is whether the secure-link graph is connected. It turns out that the important scaling is in terms of
at each node. The subset is the set of keys available at each node; two nodes can talk (securely) if they share a key in common. We keep the edge in the RGG is if the link can be secured. The question is whether the secure-link graph is connected. It turns out that the important scaling is in terms of  , where
, where 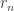 is the connectivity radius of the RGG. This sort of makes sense, as the threshold is more or less
is the connectivity radius of the RGG. This sort of makes sense, as the threshold is more or less 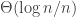 , so the keys provide a kind of discount factor on effective radius needed for connectivity — if the number of keys per node is small then you need a larger radius to compensate.
, so the keys provide a kind of discount factor on effective radius needed for connectivity — if the number of keys per node is small then you need a larger radius to compensate.
Secure Network Coding for Distributed Secret Sharing with Low Communication Cost
Nihar B Shah (University of California at Berkeley, USA); K. v. Rashmi (University of California at Berkeley, USA); Kannan Ramchandran (University of California at Berkeley, USA)
This paper was on secret sharing — a dealer wants to distribute  shares of a secret such that any
shares of a secret such that any  of them can be used to reconstruct the secret but
of them can be used to reconstruct the secret but  or fewer cannot. The idea here is that the dealer has to distribute these shares over the network, which means that if a receiver is not connected directly to the dealer then the share will be passed insecurely through another node. Existing approaches based on pairwise agreement protocols are communication intensive. The idea here is use ideas from network coding to share masked versions of shares so that intermediate nodes will not get valid shares from others. To do this the graph needs to satisfy a particular condition (-propagating), which is defined in the paper. A neat take on the problem, and worth looking at if you’re interested in that sort of thing.
or fewer cannot. The idea here is that the dealer has to distribute these shares over the network, which means that if a receiver is not connected directly to the dealer then the share will be passed insecurely through another node. Existing approaches based on pairwise agreement protocols are communication intensive. The idea here is use ideas from network coding to share masked versions of shares so that intermediate nodes will not get valid shares from others. To do this the graph needs to satisfy a particular condition (-propagating), which is defined in the paper. A neat take on the problem, and worth looking at if you’re interested in that sort of thing.
Conditional Equivalence of Random Systems and Indistinguishability Proofs
Ueli Maurer (ETH Zurich, Switzerland)
This was scheduled to be in the same session as my paper with Vinod, but was moved to an earlier session. Maurer’s “programme” as it were, is to think about security via three kinds of systems — real systems with real protocols and pseudorandomness, idealized systems with real protocols but real randomness, and perfect systems which just exist on paper. The first two are trivially indistinguishable from a computational perspective, and the goal is to show that the last two are information-theoretically indistinguishable. This conceptual framework is actually useful for me to separate out the CS and IT sides of the security design question. This paper tried to set up a framework in which there is a distinguisher D which tries to make queries to two systems and based on the answers has to decide if they are different or not. I think if you’re interested in sort of a systems-theoretic take on security you should take a look at this.
Tight Bounds for Universal Compression of Large Alphabets
Jayadev Acharya (University of California, San Diego, USA); Hirakendu Das (University of California San Diego, USA); Ashkan Jafarpour (UCSD, USA); Alon Orlitsky (University of California, San Diego, USA); Ananda Theertha Suresh (University of California, San Diego, USA)
The main contribution of this paper was to derive bounds on compression of patterns of sequences over unknown/large alphabets. The main result is that the worst case pattern redundancy for i.i.d. distributions is basically 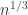 where is the blocklength. The main result is a new upper bound which uses some tricks like sampling a random number of points, where the number of samples is Poisson distributed, and a partition of the set of distributions induced by Poisson sampling.
where is the blocklength. The main result is a new upper bound which uses some tricks like sampling a random number of points, where the number of samples is Poisson distributed, and a partition of the set of distributions induced by Poisson sampling.
To Surprise and Inform
Lav R. Varshney (IBM Thomas J. Watson Research Center, USA)
Lav talked about communication over a channel where the goal is to communicate subject to a constraint on the Bayesian surprise 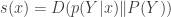 where
where  and
and  are the input and output of the channel. He gets a single-letter expression for the capacity under a bound on the max surprise and gives an example for which the same distribuion maximizes mutual information and achieves the minimax surprise. The flip side is to ask for capacity when each output should be surprising (or “attention seeking”). He gets a single letter capacity here as well, but the structure of the solution seems to be a bit more complicated.
are the input and output of the channel. He gets a single-letter expression for the capacity under a bound on the max surprise and gives an example for which the same distribuion maximizes mutual information and achieves the minimax surprise. The flip side is to ask for capacity when each output should be surprising (or “attention seeking”). He gets a single letter capacity here as well, but the structure of the solution seems to be a bit more complicated.