I promised some ITA blogging, so here it is. Maybe Alex will blog a bit too. These notes will by necessity be cursory, but I hope some people will find some of these papers interesting enough to follow up on them.
A Reverse Pinsker Inequality
Daniel Berend, Peter Harremoës , Aryeh Kontorovich
Aryeh gave this talk on what we can say about bounds in the reverse direction of Pinsker’s inequality. Of course, in general you can’t say much, but what they do is show an expansion of the KL divergence in terms of the total variation distance in terms of the balance coefficient of the distribution 
Unfolding the entropy power inequality
Mokshay Madiman, Liyao Wang
Mokshay gave a talk on the entropy power inequality. Given vector random variables 



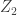
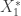

Improved lower bounds on the total variation distance and relative entropy for the Poisson approximation
Igal Sason
The previous lower bounds mentioned in the title were based on the Chen-Stein method, and they can be strengthened by sharpening the analysis in the Chen-Stein method.
Fundamental limits of caching
Mohammad A. Maddah-Ali, Urs Niesen`
This talk was on tradeoffs in caching. If there are 


Simple outer bounds for multiterminal source coding
Thomas Courtade
This was a very cute result on using the HGR maximal correlation to get outer bounds for multiterminal source coding without first deriving a single letterization of the outer bound. The main ideas are to use two properties of the HGR correlation : it tensorizes (to get the multiletter part) and the strong DPI from Elza Erkip and Tom Cover’s paper (referenced above).

Pingback: HGR maximal correlation revisited : a corrected reverse inequality | An Ergodic Walk