The Johnson-Lindenstrauss lemma shows how to project points in much lower dimension without significant distortion of their pairwise Euclidean distances.
Say you have n arbitrary vectors 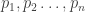

Use a fat random (normalized) Gaussian matrix of dimensions 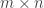
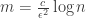
to project the points in m dimensions.
Then, with probability at least 1/2, the projected points 
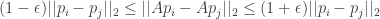
This is quite remarkable since we reduced the dimension from 

This is a very fat matrix.

A number of other matrices beyond Gaussian have been shown to also work with similar guarantees.
The Johnson-Lindenstrauss lemma sounds similar to the Restricted Isometry Property (RIP).
A fat
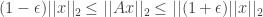
for all vectors 

This means that the matrix A does not distort the 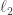
As before, well-known results have shown that random Gaussian matrices satisfy RIP with high probability if we set

To understand the similarities and differences between RIP and JL, we need to see how these results are proven. The central question is how fat random matrices distort the length of vectors and with what probability.
All known proofs of JL (for each matrix family) start with a lemma that deals with one fixed vector:
Lemma 1:
For each given vector
![Pr[ (1-\epsilon) ||x||_2 \leq ||Ax||_2 \leq (1+\epsilon) ||x||_2] \geq 1- P_{fail}(m,n) \quad (1)](https://s0.wp.com/latex.php?latex=Pr%5B+%281-%5Cepsilon%29+%7C%7Cx%7C%7C_2+%5Cleq+%7C%7CAx%7C%7C_2+%5Cleq+%281%2B%5Cepsilon%29+%7C%7Cx%7C%7C_2%5D+%5Cgeq+1-+P_%7Bfail%7D%28m%2Cn%29+%5Cquad+%281%29&bg=ffffff&fg=333333&s=0&c=20201002)
The key issue is between for all versus for each vector quantifiers.
If we first fix the vector and throw the matrix randomly, this is much easier than promising something for a random matrix that once realized, works w.h.p. for all vectors.
Clearly, if first realize the matrix, there are certainly vectors where lemma 1 cannot hold: since the matrix is fat, it has a nullspace so there are nonzero vectors that have 
How small we can make 
To prove JL for some family of matrices we need to make 
If we have lemma 1 with this guarantee, we just do a union bound over all 

It turns out that for Gaussian iid matrices, if you make 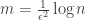
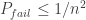
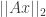


To prove RIP, exactly the same recipe can be followed: first prove Lemma 1 for one vector and then do a union bound over all 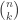


The general recipe emerges. Say you want to prove a good property for all hairy vectors.
First show that for each fixed vector a random matrix has the good property with probability at least 
Then ensure 
Finally, a union bound establishes the property for all hairy vectors.

Is a hairy vector a cowlick in the hairy ball theorem (the only technical thing that came up when googling “hairy”) or is it just a troublesome exception that fails?