We are at ISIT and I realize I am going over the same points multiple times with my students, so I thought of summarizing everything here.
How to give a better ISIT Talk.
1. Take your talks very seriously.
Do practice runs. Many of them. Your only hope for academia is by giving great talks. Give a practice talk to your friends. In the middle of your talk pause and quiz them: ok, did you get why alpha and beta are not independent? (hint: they did not).
If they did not, it is your problem not their problem.
2. They do not remember what alpha is.
In most talks, your audience does not understand what the notation is, what the problem is, or why they should care. Think of yourself: how often do you sleep or suffer through talks without even knowing what the problem is?
Do not treat your audience like that.
It is a typical scene when the presenter is focusing on a minor technical issue for ten minutes when 90% of the audience does not even know what exactly the problem is, or care.
One important exception is when your audience works on the same problem. Typically only a small part of your talk should be focused on these experts (see also 13).
3. Do a multi-resolution talk.
A useful guideline is: for an 18 minute talk, 7-9 minutes should go on explaining the formulation of your problem and why should anybody care. 5-6 minutes on explaining *what* the solution is and 4 minutes or so, on the actual painful technical stuff. The first part should be aimed at a first year grad student level. The second at a senior grad student in the general ISIT area and the last part to the expert working on related problems. If fewer than 90% of your audience are checking email in the last part of your talk, consider that a success.
4. Try to make things simple, not difficult.
It is a common mistake for starting grad students to think that their work is too simple. For that reason they will not mention known things (like explaining that ML decoding for the erasure channel consists of solving linear equations, because they fear this is too simple and well known).
Always mention the basic foundations while you try to explain something non-trivial. Your goal is not to sound smart but rather to have your audience walk out knowing something more.
Even when your audience hears things they already know, they get a warm fuzzy feeling, they do not think you are dumb.
5. Add redundancy, repeat a lot in words.
Do not say ‘We try to minimize d(k)’.
Say `we try to minimize the degree d which as I mentioned, is a function of the number of symbols k’. Repeat things all the time: Summarize what you will talk about, and in conclusions say the main points again.
6. Go back to basic concepts in words, repeat definitions.
Try to mention the basic mathematical components not the jargon you have introduced. Do not not say ‘Therefore, the code is MSR-optimal‘ but ‘Therefore, the code minimizes the repair communication (what we call MSR optimal)‘. Try to reduce your statements back to fundamental things like probabilities, graphs, rank of matrices, etc whenever possible. Do not just define some alpha jargon in the first slide and talk about that damn alpha throughout your talk.
7. Never go over time.
I have often seen even experienced speakers getting a warning that they have 3 minutes and still trying to go through their ten last slides. When you are running out of time, the goal is not to talk faster.
Say something like ‘Unfortunately or fortunately for you, I do not have time to go into the proof so I will have to skip it. The main ingredient involves analyzing random matchings which is done through Hall’s theorem and union bounds. Please talk to me offline if you are interested…”
Then, go through your conclusions slowly, repeating your main points.
This is another example of multi-resolution: you explain the techniques at a high level first. Even if you had time, you would still first have to give a one sentence high level description and then get into the the details.
8. Draw attention to important slides.
People are probably checking the Euro final when you are at slide 4, explaining what your problem is all about. Wake them up and give a notification that this is the one slide they do not want to miss. Do this right before the critical points.
9. Every slide should have one simple message.
After you make your slides ask yourself: what is the goal of this slide, I just want to explain this part. Iteratively try to simplify your slides into smaller and smaller messages. It is easier for your audience to grasp one packet of information at a time. Do not have derivations on slides (especially for an 18 minute talk), unless there is one very simple trick you really want to show. Showing math does not make you look smarter.
10. Be minimalist.
Every word on your slides, every symbol or equation you put up there dilutes the attention of your audience. Look at each bullet/slide and ask, do I really need this part or can I remove it?
11. Be excited.
Vary the tone of your voice, it may wake up somebody. You need to entertain and perform. Think: if you are not excited with your results why should anybody else be?
12. Cite people.
When somebody has related prior work, cite them on your slide. That has the benefit of waking them up when they see or hear their name.
As Rota says: `Everyone in the audience has come to listen to your lecture with the secret hope of hearing their work mentioned.‘
13. Connect to what your audience cares about.
This is non-trivial and requires experience. If you are giving a talk in a fountain codes session, you do not have to spend ten minutes defining things your audience knows already. Still define it quickly to make sure everybody is on the same page on notation. Knowing how to be at the right resolution for your audience becomes easier in time.
14. Prepare your logistics.
Know the room (go there before), know who your session chair is, have your macbook projector dongle, pre-load your slides on a USB. Bring your charger, disconnect from the internet (fun Skype messages pop-up during talks). If you are using a different machine, test your Powerpoint slides (hint: they look completely different).
15. Talk to people afterwards.
Talk to people about their work and your work. Remember that this is a professional networking event. Do not hang out with your friends, you have plenty of time for that after you go back home. Networking with other students and faculty is very important, in my case I learn more by talking to people offline than in talks.
16. Engineering theory is essentially story-telling.
Our papers and talks are essentially story-telling: Here is a model for a wireless channel, here is a proof about this model. A good story has an intellectual message that will hopefully help people think about a real engineering problem in a cleaner way.
The other aspect of our job is creating algorithms that are hopefully useful in real systems. Think: what is your story and how will you present it in your talk.
17. Read the brilliant Ten Lessons I Wish I Had Been Taught by Gian-Carlo Rota.


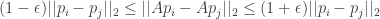



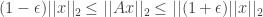


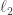

![Pr[ (1-\epsilon) ||x||_2 \leq ||Ax||_2 \leq (1+\epsilon) ||x||_2] \geq 1- P_{fail}(m,n) \quad (1)](https://s0.wp.com/latex.php?latex=Pr%5B+%281-%5Cepsilon%29+%7C%7Cx%7C%7C_2+%5Cleq+%7C%7CAx%7C%7C_2+%5Cleq+%281%2B%5Cepsilon%29+%7C%7Cx%7C%7C_2%5D+%5Cgeq+1-+P_%7Bfail%7D%28m%2Cn%29+%5Cquad+%281%29&bg=ffffff&fg=333333&s=0&c=20201002)





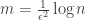
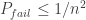
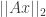


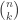





 regular graph will be a very high quality expander (for very small sets) and therefore a (very small) constant fraction of bit-flipping errors can be corrected by
regular graph will be a very high quality expander (for very small sets) and therefore a (very small) constant fraction of bit-flipping errors can be corrected by  check nodes, if we take
check nodes, if we take  to be the incidence matrix of the bipartite graph (the parity check matrix of the code), we can form
to be the incidence matrix of the bipartite graph (the parity check matrix of the code), we can form 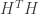 and look at its eigenvalues
and look at its eigenvalues and Tanner’s spectral bound on expansion is that expansion
and Tanner’s spectral bound on expansion is that expansion  is greater than
is greater than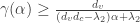 for any size of expanding sets $\alpha$. Unfortunately this bound cannot certify expansion for any
for any size of expanding sets $\alpha$. Unfortunately this bound cannot certify expansion for any  , which is exactly the point where it starts being useful for coding theory. Perhaps there are stronger spectral bounds that could establish more expansion, the book
, which is exactly the point where it starts being useful for coding theory. Perhaps there are stronger spectral bounds that could establish more expansion, the book  probability. This is what is refered to as ‘locally-tree like’. I do not know of any stronger statements but I think it can be easily shown that for any fixed cycle length, the expected number of cycles of that length is constant for regular random graphs.
probability. This is what is refered to as ‘locally-tree like’. I do not know of any stronger statements but I think it can be easily shown that for any fixed cycle length, the expected number of cycles of that length is constant for regular random graphs. bipartite expander graphs. But given a fixed measurement matrix how do we certify that it is good and should be implemented in a system?
bipartite expander graphs. But given a fixed measurement matrix how do we certify that it is good and should be implemented in a system? measurements one recovers almost all sparse signals of size up to $0.05 n$ (whp over supports) and the
measurements one recovers almost all sparse signals of size up to $0.05 n$ (whp over supports) and the  measurement matrix has
measurement matrix has  non-zeros. (see our recent
non-zeros. (see our recent  distributed sources and they want to create a good erasure code in a network: a data collector who accesses any
distributed sources and they want to create a good erasure code in a network: a data collector who accesses any  system is storing incorrect equations. These could be originating from bit-flipping errors in the storage medium or (more likely) if a malicious node was injecting errors during a previous repair in the storage system.
system is storing incorrect equations. These could be originating from bit-flipping errors in the storage medium or (more likely) if a malicious node was injecting errors during a previous repair in the storage system. and only send the projections. The error detection works since the projected data follows the same
and only send the projections. The error detection works since the projected data follows the same  using a small seed
using a small seed  , and project on that. All the storage nodes need to share the small seed
, and project on that. All the storage nodes need to share the small seed  .
.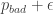 where
where  is the total variation bound obtained from the pseudo-random generator.
is the total variation bound obtained from the pseudo-random generator. nodes in an
nodes in an  (sometimes also found as
(sometimes also found as 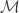 in the literature) one can use an
in the literature) one can use an  , encode into
, encode into  ) and store each packet into a storage node. The reliability achieved is that any
) and store each packet into a storage node. The reliability achieved is that any 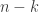 failures without losing data. But most of the time we only have one failure. We then want to repair this failure by creating a new encoded packet by communicating as little information as possible from
failures without losing data. But most of the time we only have one failure. We then want to repair this failure by creating a new encoded packet by communicating as little information as possible from  surviving storage nodes. There are two cases:
surviving storage nodes. There are two cases: . Another issue is that one can reduce this repair bandwidth if the storage per node
. Another issue is that one can reduce this repair bandwidth if the storage per node  is allowed to increase and there is a tradeoff involved.
is allowed to increase and there is a tradeoff involved. .
. of failed nodes. The second result in this paper is that all the other interior points of the tradeoff curve (except the points of minimum repair and minimum storage) cannot be achieved with linear codes for exact repair. ( Of course this does not preclude the possibility that they can be approached infinitely close by making the code packets smaller and smaller).
of failed nodes. The second result in this paper is that all the other interior points of the tradeoff curve (except the points of minimum repair and minimum storage) cannot be achieved with linear codes for exact repair. ( Of course this does not preclude the possibility that they can be approached infinitely close by making the code packets smaller and smaller). if the number of nodes helping for the repair is sufficiently large
if the number of nodes helping for the repair is sufficiently large  , the MSR cut-set point can be achived for exact repair. For this regime the paper presents explicit code constructions that use a small finite fields and build on
, the MSR cut-set point can be achived for exact repair. For this regime the paper presents explicit code constructions that use a small finite fields and build on 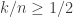 regime. The paper uses the symbol extension technique introduced in the Cadambe-Jafar paper
regime. The paper uses the symbol extension technique introduced in the Cadambe-Jafar paper 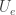 .
.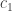 (without allowing backtracking) of this graph, consisting of edges
(without allowing backtracking) of this graph, consisting of edges  , define a monomial
, define a monomial 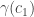 that is the product of terms
that is the product of terms  for all the edges of the cycle.
for all the edges of the cycle. .
.