I got the following email from Gerome Miklau:
Dear colleagues:
We are writing to inform you of the launch of DPCOMP.ORG.
DPCOMP.ORG is a public website designed with the following goals in mind: (1) to increase the visibility and transparency of state-of-the-art differentially private algorithms and (2) to present a principled and comprehensive empirical evaluation of these algorithms. The intended audience is both researchers who study privacy algorithms and practitioners who might deploy these algorithms.
Currently DPComp includes algorithms for answering 1- and 2-dimensional range queries. We thoroughly study algorithm accuracy and the factors that influence it and present our findings using interactive visualizations. We follow the evaluation methodology from the paper “Principled Evaluation of Differentially Private Algorithms using DPBench”. In the future we plan to extend it to cover other analysis tasks (e.g., higher dimensional data, private regression).
Our hope is that the research community will contribute to improving DPCOMP.ORG so that practitioners are exposed to emerging research developments. For example: if you have datasets which you believe would distinguish the performance of tested algorithms, new algorithms that could be included, alternative workloads, or even a new error metric, please let us know — we would like to include them.
Please share this email with interested colleagues and students. And we welcome any feedback on the website or findings.
Sincerely,
Michael Hay (Colgate University)
Ashwin Machanavajjhala (Duke University)
Gerome Miklau (UMass Amherst)
 i.i.d. individuals with characteristics distributed according to
i.i.d. individuals with characteristics distributed according to 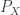 and features
and features  conditioned on the individuals according to
conditioned on the individuals according to  . The identification problem is this: given a noisy feature vector
. The identification problem is this: given a noisy feature vector  generated from a particular individual
generated from a particular individual  retrieve the index of the user corresponding to
retrieve the index of the user corresponding to  , so they are trading off identification and distortion. The solution is to code
, so they are trading off identification and distortion. The solution is to code  of
of  individuals, release a noisy version of this database. In doing so, they assume that each individual has
individuals, release a noisy version of this database. In doing so, they assume that each individual has  features and the
features and the  . So, as they put in the paper, “the primary contribution is demonstrating the equivalence between the database privacy problem and a source coding problem with additional privacy constraints.” The notion of utility is captured by a distortion measure: the encoder maps each database to a string of bits
. So, as they put in the paper, “the primary contribution is demonstrating the equivalence between the database privacy problem and a source coding problem with additional privacy constraints.” The notion of utility is captured by a distortion measure: the encoder maps each database to a string of bits  . A user with side information
. A user with side information 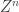 can attempt to reconstruct the database using the a lossy source code decoder. The notion of privacy by an equivocation constraint:
can attempt to reconstruct the database using the a lossy source code decoder. The notion of privacy by an equivocation constraint:
