I attended one talk on databases and unfortunately missed the second one, so the writeup I have is based on the paper…
IDENTIFICATION AND LOSSY RECONSTRUCTION IN NOISY DATABASES
(Ertem Tuncel; University of California, Riverside and Deniz Gunduz; Centre Tecnologic de Telecomunicacions de Catalunya)
This was the talk I did attend. The goal was to information-theoritize the notion of compressing databases. You get 
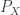





A THEORY OF UTILITY AND PRIVACY OF DATA SOURCES
Lalitha Sankar; Princeton University, S. Raj Rajagopalan; HP Labs, H. Vincent Poor; Princeton University
This talk I missed, which is all the more sad because I work on this stuff. But I did get to see a version of it at ITA and also at the IPAM workshop on privacy (as a poster). This is again an attempt to information-theoretize the problem of data disclosure: given a database 




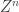
They then set about finding the best utility-privacy (= distortion-equivocation) tradeoff. This is a different model than differential privacy, and rests on a number of information-theoretic assumptions that may be relaxed in the future. For example, assuming individuals are i.i.d., that distributions are known, that the side information sequence is known, and so on would give pause to the differential privacy crowd. Much like the epsilon in differential privacy, the equivocation has a meaning but its syntactic effect is hard to parse. I guess this is why syntactic definitions of privacy like k-anonymity are popular — it’s easy to see what they mean “on the ground.”


I couldn’t have done a better job describing my paper this well :).
Thanks!
L.
p.s.: What was your paper at ISIT on?
On how to code when there is an adversary who can see your codeword causally (but with delay). We can show nice results for some limited channel models, but the complete picture is still a little opaque.