Assumptionless consistency of the Lasso
Sourav Chatterjee
The title says it all. Given 
![\{ \mathbf{x}_i : i \in [n] \}](https://s0.wp.com/latex.php?latex=%5C%7B+%5Cmathbf%7Bx%7D_i+%3A+i+%5Cin+%5Bn%5D+%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)
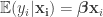
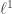
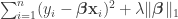
The paper analyzes the Lasso in the setting where the data are random, so there are 

![\{(\mathbf{X}_i, Y_i) : i \in [n] \}](https://s0.wp.com/latex.php?latex=%5C%7B%28%5Cmathbf%7BX%7D_i%2C+Y_i%29+%3A+i+%5Cin+%5Bn%5D+%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)





On Learnability, Complexity and Stability
Silvia Villa, Lorenzo Rosasco, Tomaso Poggio
This is a handy survey on the three topics in the title. It’s only 10 pages long, so it’s a nice fast read.
Adaptivity of averaged stochastic gradient descent to local strong convexity for logistic regression
Francis Bach
A central challenge in stochastic optimization is understanding when the convergence rate of the excess loss, which is usually 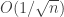

On Differentially Private Filtering for Event Streams
Jerome Le Ny
Jerome Le Ny has been putting differential privacy into signal processing and control contexts for the past year, and this is another paper in that line of work. This is important because we’re still trying to understand how time-series data can be handled in the differential privacy setting. This paper looks at “event streams” which are discrete-valued continuous-time signals (think of count processes), and the problem is to design a differentially private filtering system for such signals.
Gossips and Prejudices: Ergodic Randomized Dynamics in Social Networks
Paolo Frasca, Chiara Ravazzi, Roberto Tempo, Hideaki Ishii
This appears to be a gossip version of Acemoglu et al.’s work on “stubborn” agents in the consensus setting. They show similar qualitative behavior — opinions fluctuate but their average over time converges (the process is ergodic). This version of the paper has more of a tutorial feel to it, so the results are a bit easier to parse.
