The Gelfand-Pinsker Channel: Strong Converse and Upper Bound for the Reliability Function
Himanshu Tyagi, Prakash Narayan
Strong Converse for Gel’fand-Pinsker Channel
Pierre Moulin
Both of these papers proved the strong converse for the Gel’fand-Pinsker channel, e.g. the discrete memoryless channel with iid state sequence  , where the realized state sequence is known ahead of time at the encoder. The first paper proved a technical lemma about the image size of “good codeword sets” which are jointly typical conditioned on a large subset of the typical set of
, where the realized state sequence is known ahead of time at the encoder. The first paper proved a technical lemma about the image size of “good codeword sets” which are jointly typical conditioned on a large subset of the typical set of 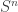 sequences. That is, given a code and a set of almost
sequences. That is, given a code and a set of almost 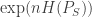 typical sequences in for which the average probability of error is small, then they get a bound on the rate of the code. They then derive bounds on error exponents for the channel. The second paper has a significantly more involved argument, but one which can be extended to multiaccess channels with states known to the encoder.
typical sequences in for which the average probability of error is small, then they get a bound on the rate of the code. They then derive bounds on error exponents for the channel. The second paper has a significantly more involved argument, but one which can be extended to multiaccess channels with states known to the encoder.
Combinatorial Data Reduction Algorithm and Its Applications to Biometric Verification
Vladimir B. Balakirsky, Anahit R. Ghazaryan, A. J. Han Vinck
The goal of this paper was to compute short fingerprints 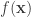 from long binary strings
from long binary strings 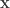 so that a verifier can look at a new long vector
so that a verifier can look at a new long vector 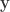 and tell whether or not is close to based on . This is a little different from hashing, where we could first compute
and tell whether or not is close to based on . This is a little different from hashing, where we could first compute 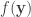 . They develop a scheme which stores the index of a reference vector
. They develop a scheme which stores the index of a reference vector  that is “close” to and the distance
that is “close” to and the distance  . This can be done with low complexity. They calculated false accept and reject rates for this scheme. Since the goal is not reconstruction or approximation, but rather a kind of classification, they can derive a reference vector set which has very low rate.
. This can be done with low complexity. They calculated false accept and reject rates for this scheme. Since the goal is not reconstruction or approximation, but rather a kind of classification, they can derive a reference vector set which has very low rate.
Two-Level Fingerprinting Codes
N. Prasanth Anthapadmanabhan, Alexander Barg
This looks at a variant of the fingerprinting problem, in which you a content creator makes several fingerprinted versions of an object (e.g. a piece of software) and then a group of pirates can take their versions and try to create a new object with a valid fingerprint. The marking assumption mean that the pirates can only alter the positions in their copies which are different. The goal is to build a code such that a verifier looking at an object produced by  pirates can identify at least one of the pirates. In the two-level problem, the objects are coarsely classified into groups (e.g. by geographic region) and the verifier wants to be able to identify one of the groups of one of the pirates when there are more than pirates. They provide some conditions for traceability and constructions, This framework can also be extended to multiple levels.
pirates can identify at least one of the pirates. In the two-level problem, the objects are coarsely classified into groups (e.g. by geographic region) and the verifier wants to be able to identify one of the groups of one of the pirates when there are more than pirates. They provide some conditions for traceability and constructions, This framework can also be extended to multiple levels.

Where is a good place to get a good and quick introduction to Gelfand-Pinsker? It’s not my regular area and the Merhav-Weissman paper is not helpful.
I don’t know of a “tutorial” presentation, but the ideas are quite similar to those from Wyner-Ziv, which is covered in Cover and Thomas…