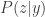From one of the presentation of Zhao and Chia at Allerton this year, I was made aware of a paper by Elza Erkip and Tom Cover on “The efficiency of investment information” that uses one of my favorite quantities, the Hirschfeld–Gebelein–Rényi maximal correlation; I first discovered it in this gem of a paper by Witsenhausen.
The Hirschfeld–Gebelein–Rényi maximal correlation 


![\sup_{f \in \mathcal{F}_X, g \in \mathcal{G}_Y} \mathbb{E}[ f(X) g(Y) ]](https://s0.wp.com/latex.php?latex=%5Csup_%7Bf+%5Cin+%5Cmathcal%7BF%7D_X%2C+g+%5Cin+%5Cmathcal%7BG%7D_Y%7D+%5Cmathbb%7BE%7D%5B+f%28X%29+g%28Y%29+%5D&bg=ffffff&fg=333333&s=0&c=20201002)
where 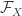
![\mathbb{E}[ f(X) ] = 0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+f%28X%29+%5D+%3D+0&bg=ffffff&fg=333333&s=0&c=20201002)
![\mathbb{E}[ f(X)^2 ] = 1](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+f%28X%29%5E2+%5D+%3D+1&bg=ffffff&fg=333333&s=0&c=20201002)
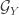
![\mathbb{E}[ g(Y) ] = 0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+g%28Y%29+%5D+%3D+0&bg=ffffff&fg=333333&s=0&c=20201002)
![\mathbb{E}[ g(Y)^2 ] = 1](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+g%28Y%29%5E2+%5D+%3D+1&bg=ffffff&fg=333333&s=0&c=20201002)


The fact in the Erkip-Cover paper is this one:

That is, the square of the HGR maximal correlation is the best (or worst, depending on your perspective) ratio of the two sides in the Data Processing Inequality:

It’s a bit surprising to me that this fact is not as well known. Perhaps it’s because the “data processing” is happening at the front end here (by choosing