The last time we saw that a packing lemma, together with a good choice of reference output distribution  (the Fano-* distribution) could give a converse for nonstationary DMC:
(the Fano-* distribution) could give a converse for nonstationary DMC:

where the distribution on 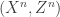 is given by the Fano distribution on the codebook, i.e. uniform input distribution on codewords followed by applying the channel. The next step in the argument is to apply this result to the MAC with inputs
is given by the Fano distribution on the codebook, i.e. uniform input distribution on codewords followed by applying the channel. The next step in the argument is to apply this result to the MAC with inputs  and
and  .
.
First start with a code for the MAC —  codewords
codewords  for user 1,
for user 1,  codewords
codewords  for user 2, and decoding regions
for user 2, and decoding regions 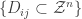 for message pair
for message pair  . Suppose the average error is bounded by
. Suppose the average error is bounded by 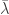 :
:

If we think about a fixed codeword  for user 2, then coding for user 1 is like coding over a nonstationary DMC, and vice versa. It turns out that we can’t apply the result directly though, and instead we want to consider only those
for user 2, then coding for user 1 is like coding over a nonstationary DMC, and vice versa. It turns out that we can’t apply the result directly though, and instead we want to consider only those  for which doesn’t have too high error probability, and vice versa. That is, define the set
for which doesn’t have too high error probability, and vice versa. That is, define the set
 .
.
Now by looking at the uniform distribution on pairs in  we can apply the previous result to get the following result.
we can apply the previous result to get the following result.
Lemma. An 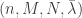 code for the MAC satisfies for some
code for the MAC satisfies for some 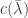 :
:

Where the distribution of  is given by the uniform distribution on the codewords in passed through the DM-MAC
is given by the uniform distribution on the codewords in passed through the DM-MAC 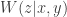 .
.
So it looks like we’re done, right? Just pass to single-letterization and that’s it! Unfortunately, what we don’t have here is that 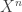 and
and  are independent. That’s because we have a picture that looks like this:
are independent. That’s because we have a picture that looks like this:

The set of codewords for the converse is not a product set.
That is, is not a product set, so the uniform distribution on doesn’t factor into independent distributions on the codewords for users 1 and 2. So can we find a large product set contained in and get a converse that way? It turns out this is hard. This is why Ahlswede (and before, Dueck) need wringing techniques. These results (saved for next time) basically say something like this: “given some random vectors whose mutual information is not too big, we can find some entries and fixed values for those entries such that the vectors are even less dependent when conditioned on those fixed values. Furthermore, the probability that those entries have those fixed values is not too small.” That is, we can “locate” the dependence in the random vectors and squeeze it out by conditioning on fixed values.
The rest of the proof strategy goes like this: use wringing techniques to find a subcode such that  are almost independent. Then if we can get the same rate bounds, we can use the continuity of mutual information to approximate the distribution with a product distribution without affecting the rate by too much, which shows it’s sufficient to consider independent
are almost independent. Then if we can get the same rate bounds, we can use the continuity of mutual information to approximate the distribution with a product distribution without affecting the rate by too much, which shows it’s sufficient to consider independent  .
.
This whole approach is confusing because a priori you know that the inputs have to be independent. But because this is a converse bound, the random variables that appear in the mutual information expressions don’t necessarily have the operational significance that we think. In the next post on this topic I’ll describe one of the two wringing lemmas, and then I’ll try to tie the proof up after that.


what a nice way to express Lemma 3 in words … :)
I understand (or I think I do) that $X^n$ and $Y^n$ are not independent … but what I don’t understand for sure is why it is enough that they are “almost” independent, and it is not needed that they are “totally independent” …
If they are “almost” independent then you can approximate the distribution with a product distribution. Let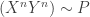 be the almost independent distribution and let
be the almost independent distribution and let  be independent such that
be independent such that 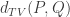 (the total variational distance) is small (in fact vanishing with
(the total variational distance) is small (in fact vanishing with  ). Then we can approximate
). Then we can approximate 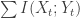 with
with 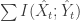 . At least that’s the idea.
. At least that’s the idea.
Oh! this is the reason for Lemma 4 … and its use the proof of Corollary 2 :)
By the way, I came across this awesome paper by Rudolf Alshwede through this other nice paper:
“On the Fingerprinting Capacity Under the Marking Assumption” N. Prasanth Anthapadmanabhan, Alexander Barg, and Ilya Dumer. IEEE Transactions on Information Theory 54(6): 2678-2689 (2008)
where the proof of Theorem 5.1 relies heavily in the Rudolf Alshwede’s paper, but in an entirely different setting :)
Ah yes, I saw Prasanth present that material a while ago, and it’s quite related to AVCs (which is how I became interested).
Pingback: The strong converse for the MAC, part 4 « An Ergodic Walk
Pingback: The strong converse for the MAC summary « An Ergodic Walk