Better late than never, I suppose. A few weeks ago I escaped the cold of New Jersey to my old haunts of San Diego. Although La Jolla was always a bit fancy for my taste, it’s hard to beat a conference which boasts views like this:

A view from the sessions at ITA 2015
I’ll just recap a few of the talks that I remember from my notes — I didn’t really take notes during the plenaries so I don’t have much to say about them. Mostly this was due to laziness, but finding the time to blog has been challenging in this last year, so I think I have to pick my battles. Here’s a smattering consisting of

(Information theory)
Emina Soljanin talked about designing codes that are good for fast access to the data in distributed storage. Initial work focused on how to repair codes under disk failures. She looked at how easy it is to retrieve the information afterwords to guarantee some QoS for the storage system. Adam Kalai talked about designing compression schemes that work for an “audience” of decoders. The decoders have different priors on the set of elements/messages so the idea is to design an encoder that works for this ensemble of decoders. I kind of missed the first part of the talk so I wasn’t quite sure how this relates to classical work in mismatched decoding as done in the information theory world. Gireeja Ranade gave a great talk about defining notions of capacity/rate need to control a system which as multiplicative uncertainty. That is, ![x[n+1] = x[n] + B[n] u[n]](https://s0.wp.com/latex.php?latex=x%5Bn%2B1%5D+%3D+x%5Bn%5D+%2B+B%5Bn%5D+u%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![B[n]](https://s0.wp.com/latex.php?latex=B%5Bn%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![| x[n]/x[0] |](https://s0.wp.com/latex.php?latex=%7C+x%5Bn%5D%2Fx%5B0%5D+%7C&bg=ffffff&fg=333333&s=0&c=20201002)
(Learning and statistics)
I learned about active regression approaches from Sivan Sabato that provably work better than passive learning. The idea there is do to use a partition of the X space and then do piecewise constant approximations to a weight function that they use in a rejection sampler. The rejection sampler (which I thought of as sort of doing importance sampling to make sure they cover the space) helps limit the number of labels requested by the algorithm. Somehow I had never met Raj Rao Nadakuditi until now, and I wish I had gotten a chance to talk to him further. He gave a nice talk on robust PCA, and in particular how outliers “break” regular PCA. He proposed a combination of shrinkage and truncation to help make PCA a bit more stable/robust. Laura Balzano talked about “estimating subspace projections from incomplete data.” She proposed an iterative algorithm for doing estimation on the Grassmann manifold that can do subspace tracking. Constantine Caramanis talked about a convex formulation for mixed regression that gives a guaranteed solution, along with minimax sample complexity bounds showing that it is basically optimal. Yingbin Liang talked about testing approaches for understanding if there is an “anomalous structure” in a sequence of data. Basically for a sequence 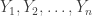
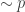

(Privacy)
Cynthia Dwork gave a tutorial on differential privacy with an emphasis on the recent work involving false discovery rate. In addition to her plenary there were several talks on differential privacy and other privacy measures. Kunal Talwar talked about their improved analysis of the SuLQ method for differentially private PCA. Unfortunately there were two privacy sessions in parallel so I hopped over to see John Duchi talk about definitions of privacy and how definitions based on testing are equivalent to differential privacy. The testing framework makes it easier to prove minimax bounds, though, so it may be a more useful view at times. Nadia Fawaz talked about privacy for time-series data such as smart meter data. She defined different types of attacks in this setting and showed that they correspond to mutual information or directed mutual information, as well as empirical results on a real data set. Raef Bassily studied a estimation problem in the streaming setting where you want to get a histogram of the most frequent items in the stream. They reduce the problem to one of finding a “unique heavy hitter” and develop a protocol that looks sort of like a code for the MAC: they encode bits into a real vector, had noise, and then add those up over the reals. It’s accepted to STOC 2015 and he said the preprint will be up soon.

 in practical scenarios, and dealing with multiple disclosures via stronger composition rules. They further ignore real technical hurdles in realizing “pure” differential privacy in favor of “illustrations” with the goal of painting proponents of differential privacy as ideologues and hucksters. Of course context and judgement are important in designing query mechanisms and privacy-preserving analysis systems. Furthermore, in many cases microdata have to be released for legal reasons. I think few people believe that differential privacy is a panacea, but it at least provides a real quantifiable approach to thinking about these privacy problems that one can build theories and algorithms around. The key is to figure out how to make those work on real data, and there’s a lot more research to be done on that front.
in practical scenarios, and dealing with multiple disclosures via stronger composition rules. They further ignore real technical hurdles in realizing “pure” differential privacy in favor of “illustrations” with the goal of painting proponents of differential privacy as ideologues and hucksters. Of course context and judgement are important in designing query mechanisms and privacy-preserving analysis systems. Furthermore, in many cases microdata have to be released for legal reasons. I think few people believe that differential privacy is a panacea, but it at least provides a real quantifiable approach to thinking about these privacy problems that one can build theories and algorithms around. The key is to figure out how to make those work on real data, and there’s a lot more research to be done on that front.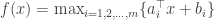
 belonging to some convex polytope
belonging to some convex polytope 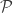 . This is a bit different than the kind of convex programs I’ve been looking at (which are more ERM-like). Such programs occur often in resource allocation problems. Here the private information of users are the offsets
. This is a bit different than the kind of convex programs I’ve been looking at (which are more ERM-like). Such programs occur often in resource allocation problems. Here the private information of users are the offsets  . They propose a number of methods for generating differentially private approximations to this problem. Analyzing the sensitivity of this optimization is tricky, so they use an upper bound based on the diameter of the feasible set $\mathcal{P}$ to find an appropriate noise variance. The exponential mechanism also gives a feasible mechanism, although the exact dependence of the suboptimality gap on
. They propose a number of methods for generating differentially private approximations to this problem. Analyzing the sensitivity of this optimization is tricky, so they use an upper bound based on the diameter of the feasible set $\mathcal{P}$ to find an appropriate noise variance. The exponential mechanism also gives a feasible mechanism, although the exact dependence of the suboptimality gap on 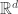 .
. -dimensional data points
-dimensional data points ![\{ \mathbf{x}_i : i \in [n] \}](https://s0.wp.com/latex.php?latex=%5C%7B+%5Cmathbf%7Bx%7D_i+%3A+i+%5Cin+%5Bn%5D+%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) the Lasso tries to fit the model
the Lasso tries to fit the model 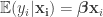 by minimizing the
by minimizing the 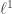 penalized squared error
penalized squared error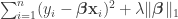 .
. i.i.d. copies of a pair of random variables
i.i.d. copies of a pair of random variables  so the data is
so the data is ![\{(\mathbf{X}_i, Y_i) : i \in [n] \}](https://s0.wp.com/latex.php?latex=%5C%7B%28%5Cmathbf%7BX%7D_i%2C+Y_i%29+%3A+i+%5Cin+%5Bn%5D+%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) . The assumptions are on the random variables
. The assumptions are on the random variables 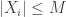 is bounded, the variable
is bounded, the variable  , and
, and  , where
, where  and
and  are unknown constants. Basically that’s all that’s needed — given a bound on
are unknown constants. Basically that’s all that’s needed — given a bound on  , he derives a bound on the mean-squared prediction error.
, he derives a bound on the mean-squared prediction error.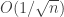 , can be improved to
, can be improved to  . Most often this involves additional assumptions on the loss functions (which can sometimes get a bit baroque and hard to check). This paper considers constant step-size algorithms but where instead they consider the averaged iterate $\latex \bar{\theta}_n = \sum_{k=0}^{n-1} \theta_k$. I’m trying to slot this in with other things I know about stochastic optimization still, but it’s definitely worth a skim if you’re interested in the topic.
. Most often this involves additional assumptions on the loss functions (which can sometimes get a bit baroque and hard to check). This paper considers constant step-size algorithms but where instead they consider the averaged iterate $\latex \bar{\theta}_n = \sum_{k=0}^{n-1} \theta_k$. I’m trying to slot this in with other things I know about stochastic optimization still, but it’s definitely worth a skim if you’re interested in the topic.![x_i \in [0,1]](https://s0.wp.com/latex.php?latex=x_i+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) and we want to compute the average
and we want to compute the average 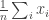 in a differentially private way. One way to do this is to release
in a differentially private way. One way to do this is to release 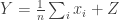 , where
, where  has a Laplace distribution:
has a Laplace distribution: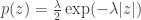 .
. the average can change by at most
the average can change by at most  . Let
. Let 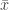 and
and  be the average of the original data and the data with one element changed. The output density in these two cases has distribution
be the average of the original data and the data with one element changed. The output density in these two cases has distribution  and
and  , so for a
, so for a 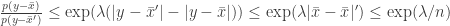
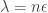 we get an
we get an ![\mathbf{x}_i \in [0,1]^d](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bx%7D_i+%5Cin+%5B0%2C1%5D%5Ed&bg=ffffff&fg=333333&s=0&c=20201002) ? Well, one candidate is release a differentially private version of the mean by computing
? Well, one candidate is release a differentially private version of the mean by computing  , where
, where  has a distribution that looks Laplace-like but in higher dimensions:
has a distribution that looks Laplace-like but in higher dimensions:
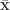 and
and 
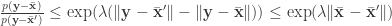
 (by replacing
(by replacing  with
with  , for example), so the overall bound is
, for example), so the overall bound is  , which means choosing
, which means choosing  we get
we get 
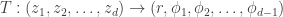 whose Jacobian is
whose Jacobian is .
.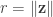 we get
we get .
.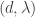 . We can generate this by taking the sum of
. We can generate this by taking the sum of  exponential variables with parameter
exponential variables with parameter  . The direction we can pick uniformly by sampling
. The direction we can pick uniformly by sampling  , there is a convex probability distribution
, there is a convex probability distribution  on the real line with a finite entropy, such that
on the real line with a finite entropy, such that  , where
, where  and
and  are independent random variables, distributed according to
are independent random variables, distributed according to 