I started working this fall on an interesting problem (shameless plug!) with Francesco Orabona, Tamir Hazan, and Tommi Jaakkola. What we do there is basically a measure concentration result, but I wanted to write a bit about the motivation for the paper. It’s nicely on the edge of that systems EE / CS divide, so I thought it might be a nice topic for the blog. One name for this idea is “MAP perturbations” so the first thing to do is explain what that means. The basic idea is to take a posterior probability distribution (derived from observed data) and do a random perturbation of the probabilities, and then take the maximum of that perturbed distribution. Sometimes this is called “perturb-and-MAP” but as someone put it, that sounds a bit like “hit-and-run.”
The basic problem is to sample from a particular joint distribution on  variables. For simplicity, let’s consider an -bit vector
variables. For simplicity, let’s consider an -bit vector 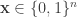 . There are
. There are  possible values, so explicitly maximizing the distribution could be computationally tricky. However we are often aided by the fact probability model has some structure. For example, the bits may be identified with labels {foreground,background} and correspond to pixels in an image, and there may be some local constraints which make it more likely for adjacent pixels to have the same label. In general, these local constraints get lumped together into a potential function
possible values, so explicitly maximizing the distribution could be computationally tricky. However we are often aided by the fact probability model has some structure. For example, the bits may be identified with labels {foreground,background} and correspond to pixels in an image, and there may be some local constraints which make it more likely for adjacent pixels to have the same label. In general, these local constraints get lumped together into a potential function  which assigns a score to each
which assigns a score to each 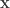 . The distribution on is a Gibbs distribution:
. The distribution on is a Gibbs distribution:

where the normalizing constant  is the infamous partition function:
is the infamous partition function:
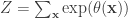
It’s infamous because it’s often hard to compute explicitly. This also makes sampling from the Gibbs distribution hard.
The MAP rule chooses the that maximizes this distribution. Doing this means you don’t need to calculate since you can maximize the potential function instead:
 .
.
This isn’t any easier in general, computationally, but people have put lots of blood, sweat, and tears into creating MAP solvers that use tricks to do this maximization. In some cases, these solvers work pretty well. Our goal will be to use the good solvers as a black box.
Unfortunately, in a lot of applications, we really would like to sample from he Gibbs distribution, because the number-one best configuration may not be the only “good” one. In fact, there may be many almost-maxima, and sampling will let you produce a list of those. One way to do this is via Markov-chain Monte Carlo (MCMC), but the problem with all MCMC methods is you have to know how long to run the chain.
The MAP perturbation approach is different — it adds a random function  to the potential function and solves the resulting MAP problem:
to the potential function and solves the resulting MAP problem:
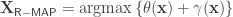
The random function 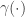 associates a random variable to each . The simplest approach to designing a perturbation function is to associate an independent and identically distributed (i.i.d.) random variable for each . We can find the distribution of the randomized MAP predictor when each a Gumbel random variable with zero mean, variance
associates a random variable to each . The simplest approach to designing a perturbation function is to associate an independent and identically distributed (i.i.d.) random variable for each . We can find the distribution of the randomized MAP predictor when each a Gumbel random variable with zero mean, variance 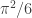 , and cumulative distribution function
, and cumulative distribution function
 ,
,
where  is the Euler-Mascheroni constant.
is the Euler-Mascheroni constant.
So what’s the distribution of the output of the randomized predictor 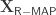 ? It turns out that the distribution is exactly that of the Gibbs distribution we want to sample from:
? It turns out that the distribution is exactly that of the Gibbs distribution we want to sample from:

and the expected value of the maximal value is the log of the partition function:
![\mathbb{E}_{\gamma}\left[ \max_{\mathbf{x}} \left\{ \theta(\mathbf{x}) + \gamma(\mathbf{x}) \right\} \right] = \log Z](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7B%5Cgamma%7D%5Cleft%5B+%5Cmax_%7B%5Cmathbf%7Bx%7D%7D+%5Cleft%5C%7B+%5Ctheta%28%5Cmathbf%7Bx%7D%29+%2B+%5Cgamma%28%5Cmathbf%7Bx%7D%29+%5Cright%5C%7D+%5Cright%5D+%3D+%5Clog+Z&bg=ffffff&fg=333333&s=0&c=20201002)
This follows from properties of the Gumbel distribution.
Great – we’re done. We can just generate the  random variables, shove the perturbed potential function into our black-box MAP solver, and voilà: samples from the Gibbs distribution. Except that there’s a little problem here – we have to generate Gumbel variables, one for each , so we’re still a bit sunk.
random variables, shove the perturbed potential function into our black-box MAP solver, and voilà: samples from the Gibbs distribution. Except that there’s a little problem here – we have to generate Gumbel variables, one for each , so we’re still a bit sunk.
The trick is to come up with lower-complexity perturbation (something that Tamir and Tommi have been working on for a bit, among others), but I will leave that for another post…
