Mike Rabbat pointed out his new preprint on ArXiv:
Broadcast Gossip Algorithms for Consensus on Strongly Connected Digraphs
Wu Shaochuan, Michael G. Rabbat
The basic starting point is the unidirectional Broadcast Gossip algorithm — we have 


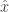

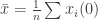
![\mathbb{E}[\hat{x}] = \bar{x}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Chat%7Bx%7D%5D+%3D+%5Cbar%7Bx%7D&bg=ffffff&fg=333333&s=0&c=20201002)
The reason broadcast gossip does’t compute the average is pretty clear — since the communication and updates are unidirectional, the average of the nodes’ values changes over time. One way around this is to use companion variables 
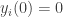





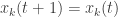

So what’s going on here? Each time a node transmits it resets its companion variable to 
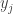
The parameters of the algorithm are matrices 




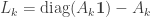

When node
![W_k \left[ \begin{array}{cc} I - L_k & \epsilon D_k \\ L_k & S_k - \epsilon D_k \end{array} \right]](https://s0.wp.com/latex.php?latex=W_k+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+I+-+L_k+%26+%5Cepsilon+D_k+%5C%5C+L_k+%26+S_k+-+%5Cepsilon+D_k+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
such that
![\left[ \begin{array}{c} \mathbf{x}(t+1) \\ \mathbf{y}(t+1) \end{array} \right]^T = W(t) \left[ \begin{array}{c} \mathbf{x}(t) \\ \mathbf{y}(t) \end{array} \right]^T](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cmathbf%7Bx%7D%28t%2B1%29+%5C%5C+%5Cmathbf%7By%7D%28t%2B1%29+%5Cend%7Barray%7D+%5Cright%5D%5ET+%3D+W%28t%29+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cmathbf%7Bx%7D%28t%29+%5C%5C+%5Cmathbf%7By%7D%28t%29+%5Cend%7Barray%7D+%5Cright%5D%5ET&bg=ffffff&fg=333333&s=0&c=20201002)
where 
The main results are:
- If we choose
small enough, then
and
under more conditions.
- A sufficient condition for the second moment of the error to go to 0.
- Rules on how to pick the parameters, especially
There are also some nice simulations. Broadcast gossip is nice because of its simplicity, and adding a little monitoring/control variable 
