For many of the talks I attended I didn’t take notes — partly this is because I didn’t feel expert enough to note things down correctly, and partly because I am
RÉNYI DIVERGENCE AND MAJORIZATION (Tim van Erven; Centrum Wiskunde & Informatica, Peter Harremoës; Copenhagen Business College)
Peter gave a talk on some properties of the Rényi entropy

where  is a dominating measure, and a related geometric quantity, the Lorenz diagram. This is a set of all points in
is a dominating measure, and a related geometric quantity, the Lorenz diagram. This is a set of all points in 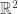 which are equal to
which are equal to  for some unit measure function
for some unit measure function  on [0,1]. It turns out that subset relationships of Lorenz diagrams are the same as majorization relationships between the measures. This is related to something called Markov ordering from a recent paper by Gorban, Gorban, and Judge. This was one of those nice talks which pointed me towards some results and tools that are new to me but that I could not fully understand during the talk.
on [0,1]. It turns out that subset relationships of Lorenz diagrams are the same as majorization relationships between the measures. This is related to something called Markov ordering from a recent paper by Gorban, Gorban, and Judge. This was one of those nice talks which pointed me towards some results and tools that are new to me but that I could not fully understand during the talk.
MINIMAX LOWER BOUNDS VIA F-DIVERGENCES (Adityanand Guntuboyina; Yale University)
This talk was on minimax lower bounds on parameter estimation which can be calculated in terms of generalized divergences, which are of the form

Suppose  is an estimator for some parameter
is an estimator for some parameter  . We want universal (over ) lower bounds on
. We want universal (over ) lower bounds on  . This gives a generalization of Fano’s inequality:
. This gives a generalization of Fano’s inequality:
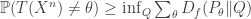
This has a very geometric feel to it but I had a bit of a hard time following all of the material since I didn’t know the related literature very well (much of it was given in relation to Yang and Barron’s 1999 paper).
MUTUAL INFORMATION SADDLE POINTS IN CHANNELS OF EXPONENTIAL FAMILY TYPE (Todd Coleman; University of Illinois, Maxim Raginsky; Duke University)
In some cases where we have a class of channels and a class of channel inputs, there is a saddle point. The main example is that Gaussian noise is the worst for a given power constraint and Gaussian inputs are the best. Another example is the “bits through queues” This paper gave a more general class of channels of “exponential family type” and gave a more general condition under which you get a saddle point for the mutual information. The channel models are related to Gibbs variational principle, and the arguments had a kind of “free energy” interpretation. Ah, statistical physics rears its head again.
INFORMATION-THEORETIC BOUNDS ON MODEL SELECTION FOR GAUSSIAN MARKOV RANDOM FIELDS (Wei Wang, Martin J. Wainwright, Kannan Ramchandran; University of California, Berkeley)
This was on two problems: inferring edges in a graphical model from iid samples from that model, and inverse covariance estimation. They are similar, but not quite the same. The goal was to prove necessary conditions for doing this; these necessary conditions match the corresponding achievable rates from polytime algorithms. The main result was that you need 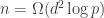 samples, where
samples, where  is the number of variables, and
is the number of variables, and  is the max degree in the graphical model. The proof approach was through modeling graph selection as channel coding in which the channel outputs samples from a graphical model chosen by the encoder. If the decoder can identify the model then the problem is solvable. This is analogous to the talk Sriram Vishwanath gave today on matrix completion.
is the max degree in the graphical model. The proof approach was through modeling graph selection as channel coding in which the channel outputs samples from a graphical model chosen by the encoder. If the decoder can identify the model then the problem is solvable. This is analogous to the talk Sriram Vishwanath gave today on matrix completion.
 .
.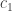 (without allowing backtracking) of this graph, consisting of edges
(without allowing backtracking) of this graph, consisting of edges  , define a monomial
, define a monomial 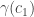 that is the product of terms
that is the product of terms  for all the edges of the cycle.
for all the edges of the cycle. .
. nodes in a network and each has a value in a finite field. They pass linear combinations of their symbols around. The goal for every node to learn all the information, or equivalently to gather a full-rank set of equations. Nodes can communicate according to a graph structure — they presented upper and lower bounds of
nodes in a network and each has a value in a finite field. They pass linear combinations of their symbols around. The goal for every node to learn all the information, or equivalently to gather a full-rank set of equations. Nodes can communicate according to a graph structure — they presented upper and lower bounds of  where
where 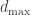 is the maximum degree in the graph. They also showed the barbell graph is very very slow.
is the maximum degree in the graph. They also showed the barbell graph is very very slow. .
.