For many of the talks I attended I didn’t take notes — partly this is because I didn’t feel expert enough to note things down correctly, and partly because I am
RÉNYI DIVERGENCE AND MAJORIZATION (Tim van Erven; Centrum Wiskunde & Informatica, Peter Harremoës; Copenhagen Business College)
Peter gave a talk on some properties of the Rényi entropy

where 
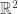


MINIMAX LOWER BOUNDS VIA F-DIVERGENCES (Adityanand Guntuboyina; Yale University)
This talk was on minimax lower bounds on parameter estimation which can be calculated in terms of generalized

Suppose 


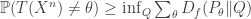
This has a very geometric feel to it but I had a bit of a hard time following all of the material since I didn’t know the related literature very well (much of it was given in relation to Yang and Barron’s 1999 paper).
MUTUAL INFORMATION SADDLE POINTS IN CHANNELS OF EXPONENTIAL FAMILY TYPE (Todd Coleman; University of Illinois, Maxim Raginsky; Duke University)
In some cases where we have a class of channels and a class of channel inputs, there is a saddle point. The main example is that Gaussian noise is the worst for a given power constraint and Gaussian inputs are the best. Another example is the “bits through queues” This paper gave a more general class of channels of “exponential family type” and gave a more general condition under which you get a saddle point for the mutual information. The channel models are related to Gibbs variational principle, and the arguments had a kind of “free energy” interpretation. Ah, statistical physics rears its head again.
INFORMATION-THEORETIC BOUNDS ON MODEL SELECTION FOR GAUSSIAN MARKOV RANDOM FIELDS (Wei Wang, Martin J. Wainwright, Kannan Ramchandran; University of California, Berkeley)
This was on two problems: inferring edges in a graphical model from iid samples from that model, and inverse covariance estimation. They are similar, but not quite the same. The goal was to prove necessary conditions for doing this; these necessary conditions match the corresponding achievable rates from polytime algorithms. The main result was that you need 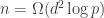



Wow, they all look very interesting! Do you know where the papers may be found online?
The proceeding should be on IEEEXplore sometime, but some authors have uploaded papers to ArXiV. Links can be found via the technical program.