I think I lack the willpower to write up more notes on talks, and there are other things I’d like to blog about, but here are one or two sentences on some other talks that I found interesting… I also enjoyed the energy session on Friday and the talks by Sundeep and Galen on compressed sensing, but time has gotten the better of me. Next time, folks.
Channel Intrinsic Randomness
Matthieu Bloch
This was on extracting random bits from the output of noisy channel. These bits should be independent of the input to the channel. Matthieu uses the enigmatic information spectrum method to get his results — thanks to the plenary lecture I was able to understand it a bit better than I might have otherwise.
Assisted Common Information
Vinod Prabhakaran and Manoj Prabhakaran
I was very interested in this talk because I have been thinking of a related problem. Two terminals observe correlated sources 

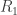
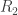
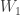
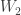
Patterns and Exchangeability
N. P. Santhanam and M. Madiman
This work grew out of the AIM workshop on permanents. De Finetti’s theorem says an exchangeable process can be built up as a mixture of iid processes. Kingman showed that something called an exchangeable partition process is built up from something he called “paintbox processes.” One thing that we discovered at the workshop was that the pattern process of an iid process is the same as a paintbox process (and vice-versa). The paper then goes through many connections between these processes, certain limits of graphs, and connections to universal compression.
Universal Hypothesis Testing in the Learning-Limited Regime
Benjamin G. Kelly, Thitidej Tularak, Aaron B. Wagner, and Pramod Viswanath
This was a really great talk. The problem here is that for each 
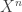
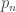
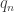

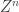



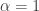
Feature Extraction for Universal Hypothesis Testing via Rank-Constrained Optimization
Dayu Huang and Sean Meyn
This talk was of interest to me because I have been looking at hypothesis testing problems in connection with election auditing. In universal testing you know a lot about the distribution for one hypothesis, but much less about the other hypothesis. The Hoeffding test is a threshold test on the KL-divergence between the empirical distribution and the known hypothesis. This test is asymptotically optimal but has a high variance when the data is in high dimension. Thus for smaller sample sizes, a so-called mismatched divergence test may be better. In this paper they look at how to tradeoff the variance and the error exponent of the test.
![[0,A]](https://s0.wp.com/latex.php?latex=%5B0%2CA%5D&bg=ffffff&fg=333333&s=0&c=20201002) in which
in which  bits arrive at a random time at the encoder. The bits have to be transmitted to the receiver with delay less than
bits arrive at a random time at the encoder. The bits have to be transmitted to the receiver with delay less than  . The decoder hears noise when the encoder is silent, and furthermore doesn’t know when the encoder starts transmitting. They both know
. The decoder hears noise when the encoder is silent, and furthermore doesn’t know when the encoder starts transmitting. They both know  , however. They do a capacity per-unit-cost analysis for this system and give capacity results in various cases, such as whether or not there is is a 0-cost symbol, whether or not the delay is subexponential in the number of bits to be sent, and so on.
, however. They do a capacity per-unit-cost analysis for this system and give capacity results in various cases, such as whether or not there is is a 0-cost symbol, whether or not the delay is subexponential in the number of bits to be sent, and so on. you get a central limit theorem (CLT). What if you normalize by
you get a central limit theorem (CLT). What if you normalize by 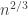 for example? It turns out you get something like
for example? It turns out you get something like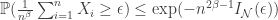
 is the rate function for the Gaussian you get out of the CLT. This is useful for error exponent analysis because it lets you get a handle on how fast you can get the error to decay if your sequence of codes has rate tending to capacity. They use these techniques to show that for a sequence of codes with gaps
is the rate function for the Gaussian you get out of the CLT. This is useful for error exponent analysis because it lets you get a handle on how fast you can get the error to decay if your sequence of codes has rate tending to capacity. They use these techniques to show that for a sequence of codes with gaps 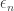 to capacity the error decays like
to capacity the error decays like  , where
, where  is the dispersion of the channel.
is the dispersion of the channel. codewords with error
codewords with error  and energy
and energy  . These give matching scalings up to the first three terms as
. These give matching scalings up to the first three terms as 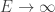 . The first term is
. The first term is 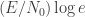 . Interestingly, with feedback, they show that the first term is
. Interestingly, with feedback, they show that the first term is  times the term without feedback, which makes sense since as the error goes to 0 the rates should coincide. They also have a surprising result showing that with energy
times the term without feedback, which makes sense since as the error goes to 0 the rates should coincide. They also have a surprising result showing that with energy  you can send
you can send  messages with 0 error.
messages with 0 error.