
Playa Norte on Isla Mujeres
I was lucky enough to get invited to present at the Communications Theory Workshop (CTW) in Cancun last month. Since the conference started on a Monday I took the weekend before to do a little sightseeing, hang out on the beach (see above), and visit Chichen Itza, which was pretty amazing. CTW is a small conference — single track, 2.5 days, and plenty of time for panels, discussions, etc. I had a great time there, and it was really nice to meet new people who were working on interesting problems that I hadn’t even heard about.
The first day was focused on wireless data services, the explosion thereof, and the lack of capacity to support it all. Add more relays, femtocells, interference management and alignment, putting more antennas for MIMO gains. Reinaldo Valenzuela was pretty pessimistic — according to him we are pretty much at the point where service providers are losing money by providing data over wireless. He seemed to think the only way out now is to change pricing models or really try to exploit network MIMO.
The second day was on cognitive radio, where the picture also seemed a bit pessimistic. Michael Marcus kind of laid into academics for not participating in the FCC comment process. The criticism is valid — if we care about cognitive radio and its potentials and so on, we should try to persuade the regulators to do smart things and not piecemeal things. As things stand now, it’s unclear how much additional capacity is available in the TV bands, given the current requirements for operating there. The sensing requirements nigh unreasonable, and if you do detect a primary you have to stay silent for 30 minutes. That makes it kind of hard to run a commercial service.
Another thing I learned during that day was that wireless microphones in the US operate in the TV bands, and are grandfathered in to the existing rules for cognitive radio. This means you have to detect if you will interfere with a wireless mic, which seems quite tough. Steve Shellhammer talked about a contest Qualcomm ran to build a detector for this problem. In addition, a large fraction of wireless microphone users are not licensed and hence their use is illegal, but nobody’s enforcing that.
The second half of the day was on emerging topics, followed by a panel called “Is Communication Theory Dead?” I think the pessimism and despair of the first two days needed to be let out a little, and there was a pretty spirited discussion of whether communication theorists were answering the right questions or not. It was like group therapy or something. Luckily there was the banquet after the panel so people could forget their woes…
The last day of the workshop was the session I spoke in, which were 5 talks on wireless networks, but from vastly different perspectives. Tara Javidi talked about routing, Daniela Tuninetti about information theory and cognitive interference channels, Elza Erkip about game theory models for the interference channel, and Anna Scaglione about cooperative information flooding. For my part, I talked about (very) recent work I have done with Tara on distributed consensus with quantized messages. We have some nice first-order results but I’m still hammering away at better bounds on the convergence rate.
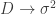
 called the symmetrizability of the channel such that for list-decoding with list sizes
called the symmetrizability of the channel such that for list-decoding with list sizes  the capacity is 0 and for larger list sizes the capacity is the randomized coding capacity of the AVC. This work extended this to the multiaccess setting, which is a particularly tricky beast since the capacity region itself is nonconvex. He showed that there is a
the capacity is 0 and for larger list sizes the capacity is the randomized coding capacity of the AVC. This work extended this to the multiaccess setting, which is a particularly tricky beast since the capacity region itself is nonconvex. He showed that there is a  such that the capacity region has empty interior if the list size is
such that the capacity region has empty interior if the list size is  and that for list sizes
and that for list sizes  you get back the randomized coding capacity. What is open is whether the list sizes for the two users can be different, so that this gap could be closed, but that problem seems pretty hard to tackle.
you get back the randomized coding capacity. What is open is whether the list sizes for the two users can be different, so that this gap could be closed, but that problem seems pretty hard to tackle. based on
based on 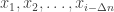 , where
, where  is the blocklength and
is the blocklength and  is the delay parameter. Suppose everything is binary and the adversary gets to flip a total of
is the delay parameter. Suppose everything is binary and the adversary gets to flip a total of 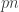 bits of the codeword but has to see it causally with delay
bits of the codeword but has to see it causally with delay 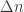 . If
. If 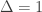 the adversary sees nothing and the average-error capacity is
the adversary sees nothing and the average-error capacity is  bits. If
bits. If 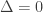 the adversary can do a lot worse and the capacity is
the adversary can do a lot worse and the capacity is  bits. What we show is that for any
bits. What we show is that for any  we go back to
we go back to  i.i.d. individuals with characteristics distributed according to
i.i.d. individuals with characteristics distributed according to 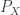 and features
and features  conditioned on the individuals according to
conditioned on the individuals according to  . The identification problem is this: given a noisy feature vector
. The identification problem is this: given a noisy feature vector  generated from a particular individual
generated from a particular individual  retrieve the index of the user corresponding to
retrieve the index of the user corresponding to  , so they are trading off identification and distortion. The solution is to code
, so they are trading off identification and distortion. The solution is to code  of
of  features and the
features and the  . So, as they put in the paper, “the primary contribution is demonstrating the equivalence between the database privacy problem and a source coding problem with additional privacy constraints.” The notion of utility is captured by a distortion measure: the encoder maps each database to a string of bits
. So, as they put in the paper, “the primary contribution is demonstrating the equivalence between the database privacy problem and a source coding problem with additional privacy constraints.” The notion of utility is captured by a distortion measure: the encoder maps each database to a string of bits  . A user with side information
. A user with side information 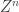 can attempt to reconstruct the database using the a lossy source code decoder. The notion of privacy by an equivocation constraint:
can attempt to reconstruct the database using the a lossy source code decoder. The notion of privacy by an equivocation constraint:
![[0,A]](https://s0.wp.com/latex.php?latex=%5B0%2CA%5D&bg=ffffff&fg=333333&s=0&c=20201002) in which
in which  bits arrive at a random time at the encoder. The bits have to be transmitted to the receiver with delay less than
bits arrive at a random time at the encoder. The bits have to be transmitted to the receiver with delay less than  . The decoder hears noise when the encoder is silent, and furthermore doesn’t know when the encoder starts transmitting. They both know
. The decoder hears noise when the encoder is silent, and furthermore doesn’t know when the encoder starts transmitting. They both know  , however. They do a capacity per-unit-cost analysis for this system and give capacity results in various cases, such as whether or not there is is a 0-cost symbol, whether or not the delay is subexponential in the number of bits to be sent, and so on.
, however. They do a capacity per-unit-cost analysis for this system and give capacity results in various cases, such as whether or not there is is a 0-cost symbol, whether or not the delay is subexponential in the number of bits to be sent, and so on. you get a central limit theorem (CLT). What if you normalize by
you get a central limit theorem (CLT). What if you normalize by 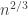 for example? It turns out you get something like
for example? It turns out you get something like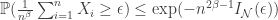
 is the rate function for the Gaussian you get out of the CLT. This is useful for error exponent analysis because it lets you get a handle on how fast you can get the error to decay if your sequence of codes has rate tending to capacity. They use these techniques to show that for a sequence of codes with gaps
is the rate function for the Gaussian you get out of the CLT. This is useful for error exponent analysis because it lets you get a handle on how fast you can get the error to decay if your sequence of codes has rate tending to capacity. They use these techniques to show that for a sequence of codes with gaps 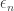 to capacity the error decays like
to capacity the error decays like  , where
, where  is the dispersion of the channel.
is the dispersion of the channel. and energy
and energy  . These give matching scalings up to the first three terms as
. These give matching scalings up to the first three terms as 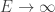 . The first term is
. The first term is 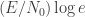 . Interestingly, with feedback, they show that the first term is
. Interestingly, with feedback, they show that the first term is  times the term without feedback, which makes sense since as the error goes to 0 the rates should coincide. They also have a surprising result showing that with energy
times the term without feedback, which makes sense since as the error goes to 0 the rates should coincide. They also have a surprising result showing that with energy  you can send
you can send  messages with 0 error.
messages with 0 error.
 is a dominating measure, and a related geometric quantity, the Lorenz diagram. This is a set of all points in
is a dominating measure, and a related geometric quantity, the Lorenz diagram. This is a set of all points in 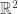 which are equal to
which are equal to  for some unit measure function
for some unit measure function  on [0,1]. It turns out that subset relationships of Lorenz diagrams are the same as majorization relationships between the measures. This is related to something called
on [0,1]. It turns out that subset relationships of Lorenz diagrams are the same as majorization relationships between the measures. This is related to something called 
 is an estimator for some parameter
is an estimator for some parameter  . We want universal (over
. We want universal (over  . This gives a generalization of Fano’s inequality:
. This gives a generalization of Fano’s inequality: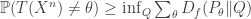
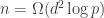 samples, where
samples, where  is the number of variables, and
is the number of variables, and  .
.
