Cosma has posted a short proof of an ergodic theorem, which makes for some light weekend reading…
Category Archives: Uncategorized
A nice formula for the volume of an L_p ball
I recently came across this paper:
Volumes of Generalized Unit Balls
Xianfu Wang
Mathematics Magazine, Vol. 78, No. 5 (Dec., 2005), pp. 390-395
which has nice formula for a “generalized unit ball” in 

These balls can look pretty crazy (as some pictures in the paper show).
The main result is that for 

The formula for the volume of the 
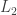
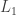

The proof given in the note is by induction, and a remark at the end points to several other proofs based on Laplace transforms.
Joel Stein on Edison, NJ : poor taste (needs more curry?)
Joel Stein has an truly atrocious piece in Time magazine, which opens with
I am very much in favor of immigration everywhere in the U.S. except Edison, N.J.
I can see how Stein is sort of trying to be funny, but the whole piece has a stink (like uncooked hing) about it that got Anna up in arms and Mimosa writing:
But really, what bothers me about this piece, why it didn’t strike me as satire, is that it seems to assume that there really is a dominant narrative out there, i.e. that “white” culture is where it’s at. Assimilation is not an option, it’s a requirement for these rude new aliens – but of course, that assimilation is on the dominant narratives terms.
Klein’s response:
Didn’t meant to insult Indians with my column this week. Also stupidly assumed their emails would follow that Gandhi non-violence thing.
Perhaps he thought the emails would also be curry flavo(u)red?
On that note, here is a quote from Amitava Kumar’s Passport Photos, which I am enjoying right now:
If the word ‘curry’ doesn’t have a stable referent or a fixed origin, how can its changing use by postcolonials be seen as a sign of resistance?
unfair labor practices and the UC postdoc union
The University of California (UC) postdocs are trying to form a union to (among other things) get a uniform contract, workplace protections, etc. The UC administration has (true to form) stalled on giving information for negotiations. Congressman George Miller sent a rather strongly worded letter to Yudof after a congressional hearing was was held in Berkeley. More recently the union filed an unfair labor practices charge with the California Public Employment Relations Board.
Beryl Benderly has been covering this story for Science Magazine – links to some of her posts are above.
Found art
As I went for a walk this morning I passed the Bank of America on University – usually a pretty deserted stretch but today brightly colored by the contents of an upended Monopoly set, bright yellow Community Chest cards and 10 dollar bills scattered on the sidewalk. In front of the doors, face up, a salmon “Get out of jail free.” A homeless man reaches down for the top hat.
UC Libraries vs. the Nature Publishing Group
Earlier this month, a letter was circulated to the UC Faculty regarding the Nature Publishing Group (NPG)’s proposal to increase the licensing fees for online access by 400%, which is pretty dramatic given a) the high cost of the subscription in the first place and b) the fact that library budgets are going down. There was a suggestion of a boycott.
NPG felt like they had been misrepresented, and issued a press statement saying “you guys are a bunch of whiners, our stuff is the best, and 7% price hikes per year is totally reasonable.” Furthermore, they said “you guys have been getting a crazy good deal for way too long anyhow and its time you paid your fair share.” I suppose behaving like complete jerks is an ok way to react when you are trying to sell somebody something, especially something that is made up of stuff written by your potential buyers. I wonder what their profit margins are like.
The University of California responded, pointing out that 7% increases, compounded, starts getting out of hand pretty fast. “Plainly put, UC Faculty do not
think that their libraries should have to pay exorbitant and unreasonable fees to get access to their own work.”
Looks like PLoS better start rolling out some new titles!
More info can be found at the OSC website, which oddly doesn’t say what OSC stands for.
ISIT 2010 : talks about adversaries
My thesis work was about a particular adversarial model from Shannon theory (the arbitrarily varying channel), but I am more broadly interested in how adversarial assumptions can be used to capture uncertainty in modeling or add an element of robustness to designs. I’m not wedded to the AVC, so I like going to see other works which try to address these issues. Among the talks I saw at ISIT, these three captured different aspects of these models.
POLYTOPE CODES AGAINST ADVERSARIES IN NETWORKS
(Oliver Kosut; Cornell University, Lang Tong; Cornell University, David Tse; University of California at Berkeley)
This talk used as an example the “cockroach network,” named thusly because it “does not look like a butterfly.” That line got a lot of laughs. In this model a subset of nodes in the network are controlled by an adversary, who can introduce errors. They show that by using a certain structured code called a polytope code, together with some checking and filtering by internal nodes, the adversaries can be detected/avoided. For some networks (planar) they can show that their code achieves the cut-set bound. The key to the codes working is making any adversarial action result in certain tuples of random variables becoming atypical and hence detectable.
JAMMING GAMES FOR POWER CONTROLLED MEDIUM ACCESS WITH DYNAMIC TRAFFIC
(Yalin Sagduyu; Intelligent Automation Inc./University of Maryland, Randall Berry; Northwestern University, Anthony Ephremides; University of Maryland)
This uses adversarial modeling (in the form of game theory) to model how users in a multiaccess setting contend for resources in the presence of jammers. In the AVC context, La and Anantharam proved some early results on these models. Here the extension was that the jammer(s) do not know whether or not the transmitter will be sending anything in a given slot (hence dynamic traffic). In the case with a single transmitter and a single jammer, the model is that the transmitter has to minimize its energy subject to an average rate constraint (packets are coming in at a certain rate to the transmitter and have to passed along). The jammer has a power constraint and wants the transmitter to maximize its energy. It turns out the that if the jammer doesn’t know the queue state of the transmitter, then it has to be on all the time. They have more complicated extensions to multi-transmitter scenarios.
ON THE DETERMINISTIC CODE CAPACITY REGION OF AN ARBITRARILY VARYING MULTIPLE-ACCESS CHANNEL UNDER LIST DECODING
(Sirin Nitinawarat; University of Maryland)
Sirin talked in the session I was in. For point-to-point AVCs under average error, there is a finite list size 




CODING AGAINST DELAYED ADVERSARIES
(Bikash Kumar Dey; Indian Institute of Technology, Bombay, Sidharth Jaggi; Chinese University of Hong Kong, Michael Langberg; Open University of Israel, Anand Sarwate; University of California, San Diego)
I guess I’ll be shameless and blog about my own paper — we looked at an adversarial setting where the adversary gets to see the transmitted symbols after a delay. We assumed that the delay grew linearly with the blocklength, so that the transmitter gets to act at time 
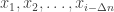

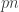
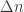
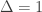

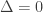


Explicit constructions of Expanders and LDPC codes
After seeing Nisim’s ISIT talk on LP Decoding of Regular LDPC Codes in Memoryless Channels, I remembered one issue that has been puzzling me for a while: if there are any explicit constructions of LDPC codes that have a provable nonzero threshold (for block-error probability, hence excluding density evolution arguments) i.e. correct a constant fraction of bit-flipping errors (other channels would be harder)– under any efficient decoder.
The question seems trivial: As is well-known, a random  regular graph will be a very high quality expander (for very small sets) and therefore a (very small) constant fraction of bit-flipping errors can be corrected by Sipser & Spielman‘s bit flipping algorithm.
regular graph will be a very high quality expander (for very small sets) and therefore a (very small) constant fraction of bit-flipping errors can be corrected by Sipser & Spielman‘s bit flipping algorithm.
regular graph will be a very high quality expander (for very small sets) and therefore a (very small) constant fraction of bit-flipping errors can be corrected by Sipser & Spielman‘s bit flipping algorithm.Also the work by Feldman et al. LP decoding corrects a constant fraction of errors establishes correction of an adversarial set of bit-flipping errors for expander graphs under LP decoding.
But here is the catch: sure, a random graph is a good expander with high probability, but how do we check if a given graph is a good expander?
The key of course is my definition of explicit construction: I mean an algorithm that terminates in polynomial time and gives me a code that certifiably works (and I think this is relevant to practice, since at the end of the day I have to use one fixed code). The only efficient way that I know to check expansion involves spectral methods ( This is from Modern Coding theory by Richardson & Urbanke) : If we have a regular bipartite graph with variable nodes and  check nodes, if we take
check nodes, if we take  to be the incidence matrix of the bipartite graph (the parity check matrix of the code), we can form
to be the incidence matrix of the bipartite graph (the parity check matrix of the code), we can form 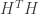 and look at its eigenvalues
and look at its eigenvalues
regular bipartite graph with variable nodes and check nodes, if we take to be the incidence matrix of the bipartite graph (the parity check matrix of the code), we can form and look at its eigenvalues and Tanner’s spectral bound on expansion is that expansion
and Tanner’s spectral bound on expansion is that expansion  is greater than
is greater than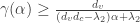 for any size of expanding sets $\alpha$. Unfortunately this bound cannot certify expansion for any
for any size of expanding sets $\alpha$. Unfortunately this bound cannot certify expansion for any  , which is exactly the point where it starts being useful for coding theory. Perhaps there are stronger spectral bounds that could establish more expansion, the book Spectral Graph Theory by Fan Chung Graham contains a lot of material on that point but I have not seen any such applications to coding.
, which is exactly the point where it starts being useful for coding theory. Perhaps there are stronger spectral bounds that could establish more expansion, the book Spectral Graph Theory by Fan Chung Graham contains a lot of material on that point but I have not seen any such applications to coding.So ok, lets say we do not know how to construct (or certify) that LDPCs have high expansion, how about other graph properties that will guarantee a correctable fraction of errors in polynomial time? This started when I was working with Costas on LP decoding for LDPC codes and we were always (incorrectly) assuming that random regular bipartite graphs will have  girth with high probability. When we actually tried to find a proof for this, for example looking at the Modern Coding theory book we find that usual proofs establish a significantly weaker statement: in a random regular graph, if you start from a variable and start expanding the tree, you will not loop around after a constant number of steps with
girth with high probability. When we actually tried to find a proof for this, for example looking at the Modern Coding theory book we find that usual proofs establish a significantly weaker statement: in a random regular graph, if you start from a variable and start expanding the tree, you will not loop around after a constant number of steps with  probability. This is what is refered to as ‘locally-tree like’. I do not know of any stronger statements but I think it can be easily shown that for any fixed cycle length, the expected number of cycles of that length is constant for regular random graphs.
probability. This is what is refered to as ‘locally-tree like’. I do not know of any stronger statements but I think it can be easily shown that for any fixed cycle length, the expected number of cycles of that length is constant for regular random graphs.
girth with high probability. When we actually tried to find a proof for this, for example looking at the Modern Coding theory book we find that usual proofs establish a significantly weaker statement: in a random regular graph, if you start from a variable and start expanding the tree, you will not loop around after a constant number of steps with probability. This is what is refered to as ‘locally-tree like’. I do not know of any stronger statements but I think it can be easily shown that for any fixed cycle length, the expected number of cycles of that length is constant for regular random graphs.The breakthrough paper by Arora, Daskalakis and Steurer, ‘Message-Passing Algorithms and Improved LP Decoding‘ establishes that regular LDPCs with girth will correct a constant fraction of random bit-flipping errors whp under LP decoding. But how do we find regular LDPCs with girth ?
girth will correct a constant fraction of random bit-flipping errors whp under LP decoding. But how do we find regular LDPCs with girth ?After searching a little I found the recent work of Bayati et al.
Generating Random Graphs with Large Girth and Generating random Tanner-graphs with large girth that talk about the related problem of generating a graph with high girth uniformly from all such graphs (and with a given degree distribution) but as far as I understood these constructions cannot guarantee a diameter scaling like (but only any constant diameter). This is of course the relevant practical question but the scaling issue remains.
(but only any constant diameter). This is of course the relevant practical question but the scaling issue remains.The only construction that I know is the one found in the appendix of Gallager’s thesis that contains a deterministic algorithm that constructs regular Tanner graphs with girth.
regular Tanner graphs with girth.The same question is relevant for compressed sensing when we ask for sparsity in the measurement matrix: All the constructions that I know for sparse measurement matrices (that require the optimal number of measurements under Basis pursuit, e.g. see the survey of Gilbert and Indyk: Sparse Recovery using Sparse Matrices) are constructed from high  bipartite expander graphs. But given a fixed measurement matrix how do we certify that it is good and should be implemented in a system?
bipartite expander graphs. But given a fixed measurement matrix how do we certify that it is good and should be implemented in a system?
bipartite expander graphs. But given a fixed measurement matrix how do we certify that it is good and should be implemented in a system?Of course one can use Message passing algorithms for compressed sensing (by Donoho, Maleki and Montanari) and obtain sparse measurement matrices with very good thresholds but under a different decoding algorithm.
The close connection of compressed sensing (under LP – Basis pursuit decoding) and channel coding (under LP decoding) gives one path for certifiable measurement matrices that are sparse):
1. The Arora, Daskalakis & Steurer paper guarantees that (3,6) regular graphs with girth correct a (quite high– much higher than expansion arguments) constant fraction of errors under LP decoding.
girth correct a (quite high– much higher than expansion arguments) constant fraction of errors under LP decoding.2. Gallager’s thesis appendix contains deterministic constructions of such (3,6) regular sparse matrices.
3. Our connection result establishes that if a matrix corrects a constant fraction of bit flipping errors, the same matrix used as a compressed sensing measurement matrix will recover all sparse signals (of the same support as the bit-flipping errors).
Combining (1)+(2)+(3) we obtain that: for sensing a length signal with  measurements one recovers almost all sparse signals of size up to $0.05 n$ (whp over supports) and the
measurements one recovers almost all sparse signals of size up to $0.05 n$ (whp over supports) and the  measurement matrix has
measurement matrix has  non-zeros. (see our recent paper )
non-zeros. (see our recent paper )
signal with measurements one recovers almost all sparse signals of size up to $0.05 n$ (whp over supports) and the measurement matrix has non-zeros. (see our recent paper )Conclusion: The Appendix C in Gallager’s thesis contains the best sparse compressed sensing measurement matrices known (under basis pursuit).
Not bad for 1963!
ISIT 2010 : databases
I attended one talk on databases and unfortunately missed the second one, so the writeup I have is based on the paper…
IDENTIFICATION AND LOSSY RECONSTRUCTION IN NOISY DATABASES
(Ertem Tuncel; University of California, Riverside and Deniz Gunduz; Centre Tecnologic de Telecomunicacions de Catalunya)
This was the talk I did attend. The goal was to information-theoritize the notion of compressing databases. You get 





A THEORY OF UTILITY AND PRIVACY OF DATA SOURCES
Lalitha Sankar; Princeton University, S. Raj Rajagopalan; HP Labs, H. Vincent Poor; Princeton University
This talk I missed, which is all the more sad because I work on this stuff. But I did get to see a version of it at ITA and also at the IPAM workshop on privacy (as a poster). This is again an attempt to information-theoretize the problem of data disclosure: given a database 



They then set about finding the best utility-privacy (= distortion-equivocation) tradeoff. This is a different model than differential privacy, and rests on a number of information-theoretic assumptions that may be relaxed in the future. For example, assuming individuals are i.i.d., that distributions are known, that the side information sequence is known, and so on would give pause to the differential privacy crowd. Much like the epsilon in differential privacy, the equivocation has a meaning but its syntactic effect is hard to parse. I guess this is why syntactic definitions of privacy like k-anonymity are popular — it’s easy to see what they mean “on the ground.”

Secrecy and Security in Distributed Storage
Secure Distributive Storage of Decentralized Source Data: Can Interaction Help?
Salim El Rouayheb, Vinod Prabhakaran and Kannan Ramchandran
Salim presented this work on creating a distributed storage system that also has secrecy. As far as I understood, the model is that there are 
In the model each storage node has a private key and these keys can be used to provide the desired secrecy. The nodes could use interactive protocols of exchanging keys etc, but the main result of the paper is that this does not reduce the required communication compared to a one-way dissemination scheme.
Security in Distributed Storage Systems by Communicating a Logarithmic Number of Bits
by Theodoros K. Dikaliotis, myself and Tracey Ho,
Ted presented our work on security (error correction) for distributed storage systems. We are looking into the problem of finding if a storage node in an 
The model is that we assume a trusted verifier that communicates to the nodes and uses the built in redundancy of the code to find where the errors are located. The first observation is in most distributed storage systems the same code is used multiple times to reduce the overhead from storing the coefficients of the code. Instead of sending all the packets, all the storage nodes can project onto the same vector 


This trick applies more generally: Assume you can prove some bad event that involves a linear function of an 
Then instead of using the random vector, you can use a pseudo-random vector 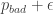

On Secure Distributed Data Storage Under Repair Dynamics
by Sameer Pawar, Salim El Rouayheb, Kannan Ramchandran
Sameer presented his work the repair problem under secrecy constraints. The problem is to construct a distributed storage system that stays secure when repairs are taking place. The model is that an eavesdropper can observe the data arriving at 
For distributed storage operating at the minimum bandwidth point (MBR) secrecy and repair can be separated without loss of optimality. The authors show that the combination of using an MDS code to achieve secrecy (by ‘mixing’ the data with random noise keys) and exact Minimum bandwidth regenerating codes that were recently invented in this paper by Rashmi et al. for repair, achieves the secrecy capacity.
Interestingly, the same separation is no longer optimal for other points of the storage-repair tradeoff and as far as I understood the secrecy capacity remains open.
