One of the things I’m always asked when giving a talk on differential privacy is “how should we interpret 
Tag Archives: statistics
Information Theoretic Estimators Toolbox
Zoltán Szabó of the Gatsby Unit forwarded me a link to his Information Theoretical Estimators Toolbox, which has MATLAB-friendly estimators for standard information-theoretic quantities. It might be of interest to readers of the blog.
Linkage
My cousin Supriya has started a blog, wading through soup, on green parenting and desi things. Her recent post, Pretty in Pink: Can Boys Wear Pink? made it to HuffPo.
Larry Wasserman is quitting blogging.
Maybe I should get a real chef knife.
If you have a stomach for horrible things, here are some images from the Nauru immigration center, where hundreds of (mostly Iranian) asylum-seekers are kept by the Australian government (via mefi).
At Rutgers, I am going to be in a union. Recent grad student union actions have come under fire from peeved faculty at UChicago (a place with horrendous institutional politics if I have ever seen one). Corey Robin breaks it down.
dismissing research communities is counterproductive
I recently saw that Andrew Gelman hasn’t really heard of compressed sensing. As someone in the signal processing/machine learning/information theory crowd, it’s a little flabbergasting, but I think it highlights two things that aren’t really appreciated by the systems EE/algorithms crowd: 1) statistics is a pretty big field, and 2) the gulf between much statistical practice and what is being done in SP/ML research is pretty wide.
The other aspect of this is a comment from one of his readers:
Meh. They proved L1 approximates L0 when design matrix is basically full rank. Now all sparsity stuff is sometimes called ‘compressed sensing’. Most of it seems to be linear interpolation, rebranded.
I find such dismissals disheartening — there is a temptation to say that every time another community picks up some models/tools from your community that they are reinventing the wheel. As a short-hand, it can be useful to say “oh yeah, this compressed sensing stuff is like the old sparsity stuff.” However, as a dismissal it’s just being parochial — you have to actually engage with the use of those models/tools. Gelman says it can lead to “better understanding one’s assumptions and goals,” but I think it’s more important to “understand what others’ goals.”
I could characterize rate-distortion theory as just calculating some large deviations rate functions. Dembo and Zeitouni list RD as an application of the LDP, but I don’t think they mean “meh, it’s rebranded LDP.” For compressed sensing, the goal is to do the inference in a computationally and statistically efficient way. One key ingredient is optimization. If you just dismiss all of compressed sensing as “rebranded sparsity” you’re missing the point entirely.
estimating probability metrics from samples
I took a look at this interesting paper by Sriperumbudur et al., On the empirical estimation of integral probability metrics (Electronic Journal of Statistics Vol. 6 (2012) pp.1550–1599). The goal of the paper is to estimate a distance or divergence between two distributions 

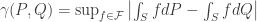
where 


Different choices of the function class give rise to different measures of difference used in so-called two-sample tests, such as the Kolmogorov-Smirnov test. The challenge in practically using these tests is that it’s hard to get bounds on how fast an estimator of 
The second section of the paper connects tests based on IPMs with the risk associated to classification rules for separating
Getting back to KL divergence and non-IPM measures, since total variation gives a lower bound on the KL divergence, they also provide lower bounds on the total variation distance in terms of other IPM metrics. This is important since the total variation distance can’t be estimated itself in a strongly consistent way. This could be useful for algorithms which need to estimate the total variation distance for continuous data. In general, estimating distances between multivariate continuous distributions can become a bit of a mess when you have to use real data — doing a plug-in estimate using, e.g. a kernel density estimator is not always the best way to go, and instead attacking the distance you want to measure directly could yield better results.
Yet more skims from ArXiV
I’m still catching up on my backlog of reading everything, but I’ve decided to set some time aside to take a look at a few papers from ArXiV.
- Lecture Notes on Free Probability by Vladislav Kargin, which is 100 pages of notes from a course at Stanford. Pretty self-explanatory, except for the part where I don’t really know free probability. Maybe reading these will help.
- Capturing the Drunk Robber on a Graph by Natasha Komarov and Peter Winkler. This is on a simple pursuit-evasion game in which the robber (evader) is moving according to a random walk. On a graph with
vertices:
the drunk will be caught with probability one, even by a cop who oscillates on an edge, or moves about randomly; indeed, by any cop who isn’t actively trying to lose. The only issue is: how long does it take? The lazy cop will win in expected time at most
(plus lower-order terms), since that is the maximum possible expected hitting time for a random walk on an n-vertex graph [2]; the same bound applies to the random cop [4]. It is easy to see that the greedy cop who merely moves toward the drunk at every step can achieve
; in fact, we will show that the greedy cop cannot in general do better. Our smart cop, however, gets her man in expected time
.
How do you make a smarter cop? In this model the cop can tell where the robber is but has to get there by walking along the graph. Strategies which try to constantly “retarget” are wasteful, so they propose a strategy wherein the cop periodically retargets to eventually meet the robber. I feel like there is a prediction/learning algorithm or idea embedded in here as well.
- Normalized online learning by Stephane Ross, Paul Mineiro, John Langford. Normalization and data pre-processing is the source of many errors and frustrations in machine learning practice. When features are not normalized with respect to each other, procedures like gradient descent can behave poorly. This paper looks at dealing with data normalization in the algorithm itself, making it “unit free” in a sense. It’s the same kind of weights-update rule that we see in online learning but with a few lines changed. They do an adversarial analysis of the algorithm where the adversary gets to scale the features before the learning algorithm gets the data point. In particular, the adversary gets to choose the covariance of the data.
- On the Optimality of Treating Interference as Noise, by Chunhua Geng, Navid Naderializadeh, A. Salman Avestimehr, and Syed A. Jafar. Suppose I have a
-user interference channel with gains
between transmitter
and receiver
. Then if
then treating interference as noise is optimal in terms of generalized degrees of freedom. I don’t really work on this kind of thing, but it’s so appealing from a sense of symmetry. - Online Learning under Delayed Feedback, byPooria Joulani, András György, Csaba Szepesvári. This paper is on forecasting algorithms which receive the feedback (e.g. the error) with a delay. Since I’ve been interested in communication with delayed feedback, this seems like a natural learning analogue. They provide ways of modifying existing algorithms to work with delayed feedback — one such method is to run a bunch of predictors in parallel and update them as the feedback is returned. They also propose methods which use partial monitoring and an approach to UCB for bandit problems in the delayed feedback setting.
Quote of the day : Herman Chernoff on Bayesians
I came across this sally in the Bayesian/frequentist wars:
In general, the religious Bayesian states that no good and only harm can come from randomized experiments. In principle, he is opposed even to random sampling in opinion polling. However, this principle puts him in untenable computational positions, and a pragmatic Bayesian will often ignore what seems useless design information if there are no obvious quirks in a randomly selected sample.
— Herman Chernoff, Sequential Analysis and Optimal Design, Philadelphia : SIAM, 1972
This doesn’t seem to capture the current state of things, but the upshot here is that Chernoff is calling shenanigans on the “philosophical consistency” of Bayesian statistics.
Sometimes I wonder if what is needed is a Kinsey scale for statistical practice… can one be Bayes-curious?
Persi Diaconis on coincidence
Persi Diaconis gave the second annual Billingsley Lecture at UChicago yesterday on the topic of coincidences and what a skeptical statistician/probabilist should say about them. He started out by talking about how Jung was fascinated by paradoxes (apparently there’s one about having fish come up all the time in conversation).
It was mostly a general-audience talk (with some asides about Poisson approximation), and the first part on the birthday problem and variants. Abstracted away, the question is given 
I was unaware of this body of Diaconis’s work, and it was nice to have a high-level talk to cap off the day.
More ArXiV skims
Assumptionless consistency of the Lasso
Sourav Chatterjee
The title says it all. Given 
![\{ \mathbf{x}_i : i \in [n] \}](https://s0.wp.com/latex.php?latex=%5C%7B+%5Cmathbf%7Bx%7D_i+%3A+i+%5Cin+%5Bn%5D+%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)
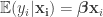
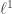
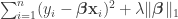
The paper analyzes the Lasso in the setting where the data are random, so there are 
![\{(\mathbf{X}_i, Y_i) : i \in [n] \}](https://s0.wp.com/latex.php?latex=%5C%7B%28%5Cmathbf%7BX%7D_i%2C+Y_i%29+%3A+i+%5Cin+%5Bn%5D+%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)
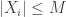





On Learnability, Complexity and Stability
Silvia Villa, Lorenzo Rosasco, Tomaso Poggio
This is a handy survey on the three topics in the title. It’s only 10 pages long, so it’s a nice fast read.
Adaptivity of averaged stochastic gradient descent to local strong convexity for logistic regression
Francis Bach
A central challenge in stochastic optimization is understanding when the convergence rate of the excess loss, which is usually 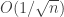

On Differentially Private Filtering for Event Streams
Jerome Le Ny
Jerome Le Ny has been putting differential privacy into signal processing and control contexts for the past year, and this is another paper in that line of work. This is important because we’re still trying to understand how time-series data can be handled in the differential privacy setting. This paper looks at “event streams” which are discrete-valued continuous-time signals (think of count processes), and the problem is to design a differentially private filtering system for such signals.
Gossips and Prejudices: Ergodic Randomized Dynamics in Social Networks
Paolo Frasca, Chiara Ravazzi, Roberto Tempo, Hideaki Ishii
This appears to be a gossip version of Acemoglu et al.’s work on “stubborn” agents in the consensus setting. They show similar qualitative behavior — opinions fluctuate but their average over time converges (the process is ergodic). This version of the paper has more of a tutorial feel to it, so the results are a bit easier to parse.
Linkage : science edition
Learning from transcriptomes can be cheaper for organisms which have never been sequenced.
A fancy Nature article on mobility privacy, in case you weren’t convinced by other studies on mobility privacy.
Bad statistics in neuroscience. Color me unsurprised.
I bet faked results happen a lot in pharmaceutical trials, given the money involved. Perhaps we should jail people for faking data as a disincentive?
The Atheist shoe company did a study to see if the USPS was discriminating against them.
