I took it a bit easy today at the conference and managed to spend some time talking to collaborators about work, so perhaps I wasn’t as 100% all in to the talks and posters. In general I find that it’s hard to understand for many posters what the motivating problem is — it’s not clear from the poster, and it’s not always clear from the explanation. Here were a few papers which I thought were interesting:
W. Koolen, D. Adamskiy, M. Warmuth
Putting Bayes to sleep
Some signals look sort of jump Markov — the distribution of the data changes over time so that there are segments which have distribution A, then later it switches to B, then perhaps back to A, and so on. A prediction procedure which “mixes past posteriors” works well in this setting but it was not clear why. This paper provides a Bayesian interpretation for the predictor as mixing in a “sleeping experts” setting.
J. Duchi, M. Jordan, M. Wainwright, A. Wibisono
Finite Sample Convergence Rates of Zero-Order Stochastic Optimization Methods
This paper looked at stochastic gradient descent when function evaluations are cheap but gradient evaluations are expensive. The idea is to compute an unbiased approximation to the gradient by evaluating the function at the  and
and  and then do the discrete approximate to the gradient. Some of the attendees claimed this is similar to an approach proposed by Nesterov, but the distinction was unclear to me.
and then do the discrete approximate to the gradient. Some of the attendees claimed this is similar to an approach proposed by Nesterov, but the distinction was unclear to me.
J. Lloyd, D. Roy, P. Orbanz, Z. Ghahramani
Random function priors for exchangeable graphs and arrays
This paper looked at Bayesian modeling for structures like undirected graphs which may represent interactions, like protein-protein interactions. Infinite random graphs whose distributions are invariant under permutations of the vertex set can be associated to a structure called a graphon. Here they put a prior on graphons, namely a Gaussian process prior, and then try to do inference on real graphs to estimate the kernel function of the process, for example.
N. Le Roux, M. Schmidt, F. Bach
A Stochastic Gradient Method with an Exponential Convergence Rate for Finite Training Sets
This was a paper marked for oral presentation — the idea is that in gradient descent it is expensive to evaluate gradients if your objective function looks like  , where
, where  are your data points and
are your data points and  is huge. This is because you have to evaluate gradients. On the other hand, stochastic gradient descent can be slow because it picks a single
is huge. This is because you have to evaluate gradients. On the other hand, stochastic gradient descent can be slow because it picks a single  and does a gradient step at each iteration on
and does a gradient step at each iteration on  . Here what they do at step
. Here what they do at step  is pick a random point
is pick a random point  , evaluate its gradient, but then take a gradient step on all points. For points
, evaluate its gradient, but then take a gradient step on all points. For points  they just use the gradient from the last time was picked. Let
they just use the gradient from the last time was picked. Let 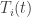 be the last time was picked before time , and
be the last time was picked before time , and  . Then they take a gradient step like
. Then they take a gradient step like  . This works surprisingly well.
. This works surprisingly well.
Stephane Mallat
Classification with Deep Invariant Scattering Networks
This was an invited talk — Mallat was trying to explain why deep networks seem to do learning well (it all seems a bit like black magic), but his explanation felt a bit heuristic to me in the end. The first main point he had is that wavelets are good at capturing geometric structure like translation and rotation, and appear to have favorable properties with respect to “distortions” in the signal. The notion of distortion is a little vague, but the idea is that if two signals (say images) are similar but one is slightly distorted, they should map to representations which are close to each other. The mathematics behind his analysis framework was group theoretic — he wants to estimate the group of actions which manipulate images. In a sense, this is a control-theory view of the problem (at least it seemed to me). The second point that I understood was that sparsity in representation has a big role to play in building efficient and layered representations. I think I’d have to see the talk again to understand it better, but in the end I wasn’t sure that I understood why deep networks are good, but I did understand some more interesting things about wavelet representations, which is cool.

![\{ \mathbf{x}_i : i \in [n] \}](https://s0.wp.com/latex.php?latex=%5C%7B+%5Cmathbf%7Bx%7D_i+%3A+i+%5Cin+%5Bn%5D+%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)
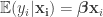
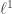
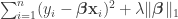

![\{(\mathbf{X}_i, Y_i) : i \in [n] \}](https://s0.wp.com/latex.php?latex=%5C%7B%28%5Cmathbf%7BX%7D_i%2C+Y_i%29+%3A+i+%5Cin+%5Bn%5D+%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)
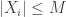





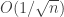


 .
. and
and  is there a term we know that
is there a term we know that  where
where  and
and 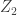 are isotropic Gaussian vectors with the same differential entropy as
are isotropic Gaussian vectors with the same differential entropy as 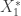 and
and  with spherically symmetric decreasing densities and show that the differential entropy of their sum lies between the two terms in the regular EPI.
with spherically symmetric decreasing densities and show that the differential entropy of their sum lies between the two terms in the regular EPI. files,
files,  users and a size
users and a size  cache at each user, how should they cache files so as to best allow a broadcaster to share the bandwidth to them? More simply, suppose there are three people who may want to watch one of three different TV shows, and they can buffer the content of one TV show. Since a priori you don’t know which show they want to watch, the idea might be to buffer/cache the first 3rd of each show at each user. They show that this is highly suboptimal. Because the content provider can XOR parts of the content to each user, the caching strategy should not be the same at each user, and the real benefit is the global cache size.
cache at each user, how should they cache files so as to best allow a broadcaster to share the bandwidth to them? More simply, suppose there are three people who may want to watch one of three different TV shows, and they can buffer the content of one TV show. Since a priori you don’t know which show they want to watch, the idea might be to buffer/cache the first 3rd of each show at each user. They show that this is highly suboptimal. Because the content provider can XOR parts of the content to each user, the caching strategy should not be the same at each user, and the real benefit is the global cache size. . At each time, a random node broadcasts its value to its neighbors in the graph and they each update their value with the weighted average of their current value and the received value. Eventually, this process converges almost surely and all nodes
. At each time, a random node broadcasts its value to its neighbors in the graph and they each update their value with the weighted average of their current value and the received value. Eventually, this process converges almost surely and all nodes 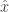 . However, in general
. However, in general  , where
, where 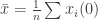 , but
, but ![\mathbb{E}[\hat{x}] = \bar{x}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Chat%7Bx%7D%5D+%3D+%5Cbar%7Bx%7D&bg=ffffff&fg=333333&s=0&c=20201002) . So this process achieves consensus but only computes the average in expectation.
. So this process achieves consensus but only computes the average in expectation. to track the effect of the broadcast. These have been studied before, but in this paper they set the initial values
to track the effect of the broadcast. These have been studied before, but in this paper they set the initial values 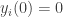 and perform updates as follows : if node
and perform updates as follows : if node  broadcasts at time
broadcasts at time 

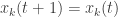

 . Each time it receives a broadcast it accumulates an offset in
. Each time it receives a broadcast it accumulates an offset in 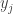 . The actual value estimate at the nodes is weighted average of the current and received value plus some of the local offset.
. The actual value estimate at the nodes is weighted average of the current and received value plus some of the local offset. and
and  and per-node matrices
and per-node matrices  . Let
. Let

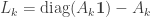

![W_k \left[ \begin{array}{cc} I - L_k & \epsilon D_k \\ L_k & S_k - \epsilon D_k \end{array} \right]](https://s0.wp.com/latex.php?latex=W_k+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+I+-+L_k+%26+%5Cepsilon+D_k+%5C%5C+L_k+%26+S_k+-+%5Cepsilon+D_k+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![\left[ \begin{array}{c} \mathbf{x}(t+1) \\ \mathbf{y}(t+1) \end{array} \right]^T = W(t) \left[ \begin{array}{c} \mathbf{x}(t) \\ \mathbf{y}(t) \end{array} \right]^T](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cmathbf%7Bx%7D%28t%2B1%29+%5C%5C+%5Cmathbf%7By%7D%28t%2B1%29+%5Cend%7Barray%7D+%5Cright%5D%5ET+%3D+W%28t%29+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cmathbf%7Bx%7D%28t%29+%5C%5C+%5Cmathbf%7By%7D%28t%29+%5Cend%7Barray%7D+%5Cright%5D%5ET&bg=ffffff&fg=333333&s=0&c=20201002)
 if node
if node  small enough, then
small enough, then ![\lim_{t \to \infty} \mathbb{E}[ \mathbf{x}(t) | \mathbf{x}(0) ] = \hat{x} \mathbf{1}](https://s0.wp.com/latex.php?latex=%5Clim_%7Bt+%5Cto+%5Cinfty%7D+%5Cmathbb%7BE%7D%5B+%5Cmathbf%7Bx%7D%28t%29+%7C+%5Cmathbf%7Bx%7D%280%29+%5D+%3D+%5Chat%7Bx%7D+%5Cmathbf%7B1%7D&bg=ffffff&fg=333333&s=0&c=20201002) and
and  under more conditions.
under more conditions. seems to buy a lot in terms of controlling bad sample paths for the process.
seems to buy a lot in terms of controlling bad sample paths for the process.