I’m an Associate Editor for the new IEEE Transactions on Signal and Information Processing Over Networks, and we are accepting submissions now. The Editor-In-Chief is Petar M. Djurić.
The new IEEE Transactions on Signal and Information Processing over Networks publishes high-quality papers that extend the classical notions of processing of signals defined over vector spaces (e.g. time and space) to processing of signals and information (data) defined over networks, potentially dynamically varying. In signal processing over networks, the topology of the network may define structural relationships in the data, or may constrain processing of the data.
To submit a paper, go to Manuscript Central.
Topics of interest include, but are not limited to the following:
Adaptation, Detection, Estimation, and Learning
- Distributed detection and estimation
- Distributed adaptation over networks
- Distributed learning over networks
- Distributed target tracking
- Bayesian learning; Bayesian signal processing
- Sequential learning over networks
- Decision making over networks
- Distributed dictionary learning
- Distributed game theoretic strategies
- Distributed information processing
- Graphical and kernel methods
- Consensus over network systems
- Optimization over network systems
Communications, Networking, and Sensing
- Distributed monitoring and sensing
- Signal processing for distributed communications and networking
- Signal processing for cooperative networking
- Signal processing for network security
- Optimal network signal processing and resource allocation
Modeling and Analysis
- Performance and bounds of methods
- Robustness and vulnerability
- Network modeling and identification
- Simulations of networked information processing systems
- Social learning
- Bio-inspired network signal processing
- Epidemics and diffusion in populations
Imaging and Media Applications
- Image and video processing over networks
- Media cloud computing and communication
- Multimedia streaming and transport
- Social media computing and networking
- Signal processing for cyber-physicalsystems
- Wireless/mobile multimedia
Data Analysis
- Processing, analysis, and visualization of big data
- Signal and information processing for crowd computing
- Signal and information processing for the Internet of Things
- Emergence of behavior
Emerging topics and applications
- Emerging topics
- Applications in life sciences, ecology, energy, social networks, economic networks, finance, social sciences, smart grids, wireless health, robotics, transportation, and other areas of science and engineering
 where each codeword is a superposition of
where each codeword is a superposition of  columns, one each from groups of size
columns, one each from groups of size  . Thus encoding is
. Thus encoding is  where
where  is a sparse vector. I saw a talk by Barron and Joseph from a previous ISIT about this, but the framework extends to rate distortion (achieving the rate distortion function), and channel coding. The main point is to lower the complexity of the code at the expense of the gap to optimal rate — encoding and decoding are polynomial time but the rate gap for rate-distortion goes to zero as
is a sparse vector. I saw a talk by Barron and Joseph from a previous ISIT about this, but the framework extends to rate distortion (achieving the rate distortion function), and channel coding. The main point is to lower the complexity of the code at the expense of the gap to optimal rate — encoding and decoding are polynomial time but the rate gap for rate-distortion goes to zero as 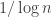 . Ramji gave a really nice and clear talk on this — I hope he puts the slides up!
. Ramji gave a really nice and clear talk on this — I hope he puts the slides up!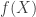 on
on  , we can define
, we can define  . The entropy is the expectation of this random variable, and the varentropy is the variance. Their main result is a upper bound on the varentropu of log concave distributions
. The entropy is the expectation of this random variable, and the varentropy is the variance. Their main result is a upper bound on the varentropu of log concave distributions 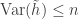 . This bound doesn’t depend on the distribution and is sharp if
. This bound doesn’t depend on the distribution and is sharp if  is a product of exponentials. They then use this to prove a universal bound on the deviation of
is a product of exponentials. They then use this to prove a universal bound on the deviation of  from its expectation, which gives a AEP that doesn’t really assume anything about the joint distribution of the variables except for log-concavity. There was more in the talk, but I eagerly await the paper.
from its expectation, which gives a AEP that doesn’t really assume anything about the joint distribution of the variables except for log-concavity. There was more in the talk, but I eagerly await the paper. ‘s are “indestructible” — they cannot be inserted or deleted. This asymmetric model leads to new asymptotic bounds on the capacity. I don’t really work on this channel model so I can’t get the finer points of the results, but once nice takeaway was that asymptotically, each indestructible
‘s are “indestructible” — they cannot be inserted or deleted. This asymmetric model leads to new asymptotic bounds on the capacity. I don’t really work on this channel model so I can’t get the finer points of the results, but once nice takeaway was that asymptotically, each indestructible  a deletion more.
a deletion more. versus a composite hypothesis
versus a composite hypothesis  where under
where under  different distributions. There are therefore
different distributions. There are therefore  . This is a sort of generalized Neyman-Pearson setup. They look at the vector of log-likelihood ratios and show that a threshold test is nearly optimal. At the time, I understood the idea of the proof, but I think it’s one of things where you need to really read the paper.
. This is a sort of generalized Neyman-Pearson setup. They look at the vector of log-likelihood ratios and show that a threshold test is nearly optimal. At the time, I understood the idea of the proof, but I think it’s one of things where you need to really read the paper.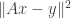 over
over  given
given  . A sketch would be to solve
. A sketch would be to solve 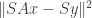 where
where  is a random projection. One question is how to choose
is a random projection. One question is how to choose  . They show that choosing
. They show that choosing 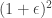 times the value of the original program as long as the the number of rows of
times the value of the original program as long as the the number of rows of  , where
, where 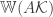 is the Gaussian width of the tangent cone of the contraint set at the optimum value. For more details look at their
is the Gaussian width of the tangent cone of the contraint set at the optimum value. For more details look at their  from phaseless measurements of the form
from phaseless measurements of the form 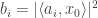 where
where  are complex spherically symmetric Gaussian vectors. Recovery from such measurements is nonconvex and tricky, but an alternating minimizing algorithm can reach a local optimum, and if you start it in a “good” initial position, it will find a global optimum. The contribution of this paper is provide such a smart initialization. The idea is to “pair” the measurements to create new measurements
are complex spherically symmetric Gaussian vectors. Recovery from such measurements is nonconvex and tricky, but an alternating minimizing algorithm can reach a local optimum, and if you start it in a “good” initial position, it will find a global optimum. The contribution of this paper is provide such a smart initialization. The idea is to “pair” the measurements to create new measurements  . This leads to a new problem (with half as many measurements) which is still hard, so they find a convex relaxation of that. I had thought briefly about such sensing setups a long time ago (and by thought, I mean puzzled over it at a coffeshop once), so it was interesting to see what was known about the problem.
. This leads to a new problem (with half as many measurements) which is still hard, so they find a convex relaxation of that. I had thought briefly about such sensing setups a long time ago (and by thought, I mean puzzled over it at a coffeshop once), so it was interesting to see what was known about the problem. samples from an unknown distribution
samples from an unknown distribution  and a set of distributions
and a set of distributions  to compare against. You want to find the distribution that is closest in
to compare against. You want to find the distribution that is closest in  . One way to do this is via Scheffe tournament tht compares all pairs of distributions — this runs in time
. One way to do this is via Scheffe tournament tht compares all pairs of distributions — this runs in time  time. They show a method that runs in
time. They show a method that runs in  time by studying the structure of the comparators used in the sorting method. The motivation is that running comparisons can be expensive (especially if they involve human decisions) so we want to minimize the number of comparisons. The paper is significantly different than the talk, but I think it would definitely be interesting to those interested in discrete algorithms. The density estimation problem is really just a motivator — the sorting problem is far more general.
time by studying the structure of the comparators used in the sorting method. The motivation is that running comparisons can be expensive (especially if they involve human decisions) so we want to minimize the number of comparisons. The paper is significantly different than the talk, but I think it would definitely be interesting to those interested in discrete algorithms. The density estimation problem is really just a motivator — the sorting problem is far more general.