I’ve been working hard with the organizing committee putting together the 2010 ITA Workshop, which promises to be a blast. With that and job applications I’m probably going to eschew blogging the workshop this year, but I’ll try to post some highlights. If nothing else, it will get me back to blogging again.
Tag Archives: networks
Allerton 2009 : quick takes
I was at the Allerton conference last week for a quick visit home — I presented a paper I wrote with Can Aysal and Alex Dimakis on analyzing broadcast-based consensus algorithms when channels vary over time. The basic intuition is that if you can get some long-range connections “enough of the time,” then you’ll get a noticeable speed up in reaching a consensus value, but with high connectivity the variance of the consensus value from the true average increases. It was a fun chance to try out some new figures that I made in OmniGraffle.
The plenary was given by Abbas El Gamal on a set of new lecture notes on network information theory that he has been developing with Young-Han Kim. He went through the organization of the material and tried to show how much of the treatment could be developed using robust typicality (see Orlitsky-Roche) and a few basic packing and covering lemmas. This in turn simplifies many of the proofs structurally and can give a unified view. Since I’ve gotten an inside peek at the notes, I can say they’re pretty good and clear, but definitely dense going at times. They are one way to answer the question of “well, what do we teach after Cover and Thomas.” They’re self-contained and compact .
What struck me is that these are really notes on network information theory and not on advanced information theory, which is the special topics class I took at Berkeley. It might be nice to have some of the “advanced but non-network” material in a little set of notes. Maybe the format of Körner’s Fourier Analysis book would work : it could cover things like strong converses, delay issues, universality, wringing lemmas, AVCs, and so on. Almost like a wiki of little technical details and so on that could serve as a reference, rather than a class. The market’s pretty small though…
I felt a bit zombified during much of the conference, so I didn’t take particularly detailed notes, but here were a few talks that I found interesting.
- Implementing Utility-Optimal CSMA (Lee, Jinsung (KAIST), Lee, Junhee (KAIST), Yi, Yung (KAIST), Chong, Song (KAIST), Proutiere, Alexandre (Microsoft Research), Chiang, Mung (Princeton University)) — There are lots of different models and algorithms for distributed scheduling in interference-limited networks. Many of these protocols involve message passing and the overhead from the messages may become heavy. This paper looked at how to use the implicit feedback from CSMA. They analyze a simple two-link system with two parameters (access and hold) and then use what I though was a “effective queue size” scheduling method. Some of the analysis was pretty tricky, using stochastic approximation tools. There were also extensive simulation results from a real deployment.
- LP Decoding Meets LP Decoding: A Connection between Channel Coding and Compressed Sensing (Dimakis, Alexandros G. (USC), Vontobel, Pascal O. (Hewlett-Packard Laboratories)) — This paper proved some connections between Linear Programming (LP) decoding of LDPC codes and goodness of compressed sensing matrices. A simple example : if a parity check matrix is good for LP decoding then it is also good for compressed sensing. In particular, if it can correct k errors it can detect k-sparse signals, and if it can correct a specific error pattern
it can detect all signals whose support is the same as
- The Compound Capacity of Polar Codes (Hassani, Hamed (EPFL), Korada, Satish Babu (EPFL), Urbanke, Ruediger (EPFL)) — Rudi gave an overview of polar codes from two different perspectives and then showed that in general polar codes do not achieve the compound channel capacity, but it’s not clear if the problem is with the code or with the decoding algorithm (so that’s still an open question).
- Source and Channel Simulation Using Arbitrary Randomness (Altug, Yucel (Cornell University), Wagner, Aaron (Cornell University)) — The basic source simulation problem is to simulate an arbitrary source
with an iid process (say equiprobable coin flips)
. Using the information spectrum method, non-matching necessary and sufficient conditions can be found for when this can be done. These are in terms of sup-entropy rates and so on. Essentially though, it’s a theory built on the limits or support of the spectra of the two processes
and
. If the entropy spectrum in
- Channels That Die (Varshney, Lav R. (MIT), Mitter, Sanjoy K. (MIT), Goyal, Vivek K (MIT)) — This paper looked at a channel which has two states, alive (a) and dead (d), and at some random time during transmission, the channel will switch from alive to dead. For example, it might switch according to a Markov chain. Once dead, it stays dead. If you want to transmit over this channel in a Shannon-reliable sense you’re out of luck, but what you can do is try to maximize the expected number of bits you get through before the channel dies. I think they call this the “volume.” So you try to send a few bits at a time (say
are the number of bits in each chunk). How do you size the chunks to maximize the volume? This can be solved with dynamic programming. There are still several open questions left, but the whole construction relies on using “optimal codes of finite blocklength” which also needs to be solved. Lav has some interesting ideas along these lines that he told me about when I was in Boston two weeks ago…
- The Feedback Capacity Region of El Gamal-Costa Deterministic Interference Channel (Suh, Changho (UC Berkeley), Tse, David (UC Berkeley)) — This paper found a single letter expression for the capacity region, which looks like the Han-Kobayashi achievable region minus the two weird
constraints. Achievability uses Han-Kobayashi in a block-Markov encoding with backward decoding, and the converse uses the El Gamal-Costa argument with some additional Markov properties. For the “bit-level” deterministic channel model, there is an interpretation of the feedback as filling a “hole” in the interference graph.
- Upper Bounds to Error Probability with Feedback (Nakiboglu, Baris (MIT), Zheng, Lizhong (MIT)) — This is a follow-on to their ISIT paper, which uses a kind of “tilted posterior matching” (a phrase which means a lot to people who really know feedback and error exponents in and out) in the feedback scheme. Essentially there’s a tradeoff between getting close to decoding quickly and minimizing the error probability, and so if you change the tilting parameter in Baris’ scheme you can do a little better. He analyzes a two phase scheme (more phases would seem to be onerous).
- Infinite-Message Distributed Source Coding for Two-Terminal Interactive Computing (Ma, Nan (Boston University), Ishwar, Prakash (Boston University)) — This looked at the interactive function computation problem, in which Alice has
, Bob has
and they want to compute some functions
and
. The pairs
are iid and jointly distributed according to some distribution
. As an example,
could be correlated bits and
and
could be the AND function. In previous work the authors characterized the the rate region (allowing vanishing probability of error) for
rounds of communication, and here they look at the case when there are infinitely many back-and-forth messages. The key insight is to characterize the sum-rate needed as a function of
and look at that surface’s analytic properties. In particular, they show it’s the minimum element of a class
of functions which have some convexity properties. There is a preprint on ArXiV.
Infocom 2009 : capacity of wireless networks
A Theory of QoS for Wireless
I-Hong Hou (University of Illinois at Urbana-Champaign, US); Vivek Borkar (Tata Institute of Fundamental Research, IN); P. R. Kumar (University of Illinois at Urbana-Champaign, US)
This paper claimed to propose a tractable and relevant framework for analyzing the quality of service in a network. In particular, the model should capture deadlines, delivery ratios, and channel reliability while providing guarantees for admission control and scheduling. The model presented was rather simple: there are 


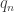

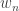
Computing the Capacity Region of a Wireless Network
Ramakrishna Gummadi (University of Illinois at Urbana-Champaign, US); Kyomin Jung (Massachusetts Institute of Technology, US); Devavrat Shah (Massachusetts Institute of Technology, US); Ramavarapu Sreenivas (University of Illinois at Urbana-Champaign, US)
This looked at wireless networks under the protocol model of Gupta and Kumar and asks the following question : if I give you a vector of rates 
The Multicast Capacity Region of Large Wireless Networks
Urs Niesen (Massachusetts Institute of Technology, US); Piyush Gupta (Bell Labs, Alcatel-Lucent, US); Devavrat Shah (Massachusetts Institute of Technology, US)
The network model is ![[0, \sqrt{n}]^2](https://s0.wp.com/latex.php?latex=%5B0%2C+%5Csqrt%7Bn%7D%5D%5E2&bg=ffffff&fg=333333&s=0&c=20201002)

Infocom 2009 : routing
Scalable Routing Via Greedy Embedding
Cedric Westphal (Docomo Labs USA, US); Guanhong Pei (Virginia Tech, US)
In a network, a greedy routing strategy that sends packets to the neighbor closest to the destination may require routing tables of size 
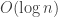


Greedy Routing with Bounded Stretch
Roland Flury (ETH Zurich, Switzerland); Sriram Pemmaraju (The University of Iowa, US); Roger Wattenhofer (ETH Zurich, Switzerland)
This was another talk about greedy routing. If the network has holes in it (imagine a lake) then greedy routing can get stuck because there is no greedy step to take. So there are lots of algorithms out there for recovering when you are stuck. It would be far nicer to get a coordinate system for the graph such that greedy routing always works (in some sense), but so that the stretch is not too bad. This talk proposed a scheme which had three ingredients: spanning trees, separators, and isometric greedy embeddings. Basically the idea (from what I saw in the talk) is to use the existence of separators in the graph to build a tree cover of the graph and then do routing along the best tree in the cover. This guarantees the bounded stretch, and the number of trees needed is not too large, so the labels are not too large either. I think it was a rather nice paper, and between the previous one and this one I was introduced to a new problem I had not thought about before.
Routing Over Multi-hop Wireless Networks with Non-ergodic Mobility
Chris Milling (The University of Texas at Austin, US); Sundar Subramanian (Qualcomm Flarion Technologies, US); Sanjay Shakkottai (The University of Texas at Austin, US); Randall Berry (Northwestern University, US)
In this paper they had a network with some static nodes and some mobile nodes who move in prescribed areas but with no real “model” on their motion. They move arbitrarily according to some arbitrary continuous paths. Some static nodes need to route packets to the mobile nodes. How should they do this? A scheme is proposed in which the static node sends out probe packets to iteratively quarter the network and corral the mobile node. If the mobile crosses a boundary then a node close to the boundary will deliver the packet. An upperbound on the throughput can be shown by considering the mobiles to be at fixed locations (chosen to be the worst possible). This is essentially the worst case, since the rates achieved by their scheme are within a polylog factor of the upper bound. This suggests that the lack of knowledge of the user’s mobility patterns hurts very little in the scaling sense.
Infocom 2009 : delay issues
Effective Delay Control for Online Network Coding
Joao Barros (University of Porto, PT); Rui Costa (Universidade do Porto / Instituto de Telecomunicações, PT); Daniele Munaretto (DoCoMo Euro-Labs, DE); Joerg Widmer (DoCoMo Euro-Labs, DE)
This talk tries to merge ARQ with network coding. The key idea is that a packet is “seen” if it only depends on XORs with future packets. The delay analysis is based then on analyzing the chains of dependent packets induced by erasures. This paper looks at the problem of multicast. Here the issue is managing the delays to multiple receivers and assessing which receiver is the “leader” and how the leader switches over time. For random erasures (different for each receiver) this means we are doing a biased random walk whose location shows who the leader is. A coding strategy is trying to control this random walk, and a strategy is proposed to maintain a “leader” by sending the XOR of the last unseen packet of all users when the leader loses a packet.
The Capacity Allocation Paradox
Asaf Baron (Technion – Israel Institute of Technology, IL); Isaac Keslassy (Technion, IL); Ran Ginosar (Technion, IL)
This talk was about a simple example of a network in which adding capacity can make a stable network unstable. To me it seemed to be because of the particular model adopted for the network, namely that if a link of capacity 
Power-Aware Speed Scaling In Processor Sharing Systems
Adam Wierman (California Institute of Technology, US); Lachlan Andrew (Swinburne University of Technology, AU); Kevin Tang (Cornell University, US)
This talk was about assigning speeds to processing jobs in a queue — if you do a job faster it takes more power but reduces delay. There are different ways of assigning speeds, either a fixed speed for all jobs (static), a square-wave for speed vs. time (gated static), or some arbitrary curve (dynamic). The metric they choose to look at it a sort of regularized energy ![E[\mathrm{energy}] + \beta E[ \mathrm{delay} ]](https://s0.wp.com/latex.php?latex=E%5B%5Cmathrm%7Benergy%7D%5D+%2B+%5Cbeta+E%5B+%5Cmathrm%7Bdelay%7D+%5D&bg=ffffff&fg=333333&s=0&c=20201002)

Searching for Manet

Infocom 2009 : network statistics problems
Graph Sampling Techniques for Studying Unstructured Overlays
Amir Hassan Rasti Ekbatani (University of Oregon, US); Mojtaba Torkjazi (University of Oregon, US); Reza Rejaie (University of Oregon, US); Nick Duffield (AT&T Labs – Research, US); Walter Willinger (AT&T Labs – Research, US); Daniel Stutzbach (Stutzbach Enterprises LLC, US)
The question in this paper was how to collect network statistics (such as node degree) in peer-to-peer networks. Since peers join and leave, selecting a random peer is difficult because there are biases caused by high-degree peers and low-lifetime peers. One approach to correct for this is to use Markov chain Monte Carlo (MCMC) to sample from the nodes. This talk proposed respondent-driven sampling (RDS), a technique used to map social networks. The idea is to do a random walk on the network and gather statistics along the walk (not just at the end, as in MCMC). These measurements are biased, but then we can correct for the bias at the end (using something called the Hansen-Hurwitz estimator, which I don’t know much about). Experimental works showed a big improvement when vanilla MCMC and RDS were compared on hierarchical scale-free graphs.
A Framework for Efficient Class-based Sampling
Mohit Saxena (Purdue University, US); Ramana Rao Kompella (Purdue University, US)
This talk was about increasing the coverage of monitoring flows in networks. Currently routers sample flows uniformly, which catches the big “elephant” flows but not the low-volume “mouse” flows. In order to increase coverage, the authors propose dividing flows into classes and then sample the classes. So the architecture is to classify a packet first, then choose whether to sample it. The goal is to do a combination of sketching and hashing that shifts the complexity to slower memory, thereby saving costs. They use something called a composite Bloom filter to do this.
Estimating Hop Distance Between Arbitrary Host Pairs
Brian Eriksson (University of Wisconsin – Madison, US); Paul Barford (University of Wisconsin – Madison, US); Rob Nowak (University of Wisconsin, Madison, US)
Given a big network (like the internet) with 
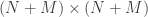
quote from the infocom panel on Clean Slate Architectures
“We get the same people and the the same dead horses and we all stand around them and beat them with sticks. And we call it Clean Slate design because we use a new stick each day.” – Joe Touch, Postel Center – Information Sciences Institute.
ISIT 2008 : networks, security, and randomness
I’m grouping posts about ISIT vaguely by topic. Progress may be slow since I am trying to give my wrists a bit of a break from typing.
ITA 2008 : Part the Second
This is the second part in my blogging about some of the talks I saw at ITA 2008, and also a way for me to test a tag so that readers who don’t care about information theory won’t have a huge post hogging up their aggregator window (livejournal, I’m looking at you). Again, I may have misunderstood something in the talks, so if you see something that doesn’t sound right, let me know.
