I’m grouping posts about ISIT vaguely by topic. Progress may be slow since I am trying to give my wrists a bit of a break from typing.
On the optimality of a construction of a secure network codes
Raymond W. Yeung and Ning Cai
This paper was one of a number of recent papers to address the issue of security in network coding. That is, if you have a network that is doing (linear) network coding but some of the internal edges are compromised by being wiretapped, what can you do? In their model, the eavesdropper can eavesdrop r links in the network, so it can see r linear combinations of the encoded packets. They proposed a construction earlier which works in the following situation: there are n disjoint paths from the source to destination, and at most r disjoint paths from the source to the wiretapped edges. There is also shares randomness between the encoder and decoder of r log q bits, where q is the field size for network coding. The point of this paper is that the construction is optimal in the following sense — (n – r) log q bits is the most information that can be conveyed while revealing nothing to the eavesdropper (in terms of equivocation), and the amount of common randomness shared between the sender and receiver is optimal. The proofs follow from Han’s inequality (or inequalities) from his 1978 paper.
Security for Wiretap Networks via Rank-Metric Codes
Danilo Silva and Frank R. Kschischang
This paper also looked at the problem of securing a network that is using network coding from eavesdroppers on the links. The idea here, as in last year’s paper by Rouayheb and Soljanin, is to take a linear transform prior to running the network code such that an eavesdropper with access to r links learns nothing but the final destination can recover the packets. The idea is to use a coset code in which we think of the source information as the syndrome from multiplying the encoded packets by a parity check matrix. That is, to encode source data S, choose an X such that H X = S, where H is the parity check matrix for some maximum-distance separable (MDS) code. In earlier constructions, there were a number of drawbacks. For example, the encoding for security had to be designed jointly with the network code or the field size of the network code had to be increased. What we would want ideally is a box that sits between the source and the network running linear network coding that introduces security while not altering the network code in any way, and in particular is independent of the network code. This architectural separation is clearly appealing. The idea in this paper is to use rank-metric codes with the Maximum Rank-Distance (MRD) property, which is analogous to MDS. By considering a collection of packets as elements of an extension field they can get around some the limitations in previous work to find an outer code that provides security against wiretappers and that works with any network code for multicast. This description is a little vague, but I recommend looking at the paper, which is nicely written, I think.
Adversarial Models and Resilient Schemes for Network Coding
Leah Nutman and Michael Langberg
This looked at a different problem than the previous two works and is about error correction against adversarial jamming in a network coding context. Suppose a jammer controls z links in the network. Then if C is the min-cut of the network (the capacity with no jamming), then the capacity is C – 2 z in many cases and for weaker adversaries it is C – z. In this paper they propose a few new variants of the adversary model for which the capacity is C – z. In particular, one model is that the jammer is computationally limited (so that factoring is hard). Under public and private key settings by using standard cryptographic protocols to verify packets, such as generating pseudorandom bits, hashes, and so on. A nice feature is that the size of the key only depends on the min cut of the graph and not on the block/packet length for the network code, which is a nice side benefit.
On the Anonymity of Chaum Mixes
Parv Venkitasubramaniam and Venkat Anantharam
Anonymity in the context of networks and routers relies on hiding the association of packets to users, or of the attribution of flows to different users. You don’t want to let some eavesdropper know where your packets are going. One strategy that has been proposed is a mix, which is an element the buffers up packets and then sends them out in a different order to scramble the flows and provide some anonymity. Chaum proposed a mix for n inputs which waits for one packet from each of the n users and then sends them out in a batch, randomly ordered. But what if there are latency constraints for the users? How does a mix trade off latency and anonymity? This paper defines a measure of anonymity and provides upper and lower bounds on the anonymity of mixes. The lower bound comes from a specific strategy, and the upper bound from relaxing some causality constraints (the mix can look ahead) and applying a recursion to tighten the bound.
Communication Requirements for Generating Correlated Random Variables
Paul Cuff
Suppose that you have a game in which the optimal mixed strategy for one player requires correlated actions from two agents, A and B. That is, in order for the player to implement its optimal strategy, it must have decentralized agents performing correlated actions. How much information is needed to set up these correlated actions? This paper dealt with the following problem: suppose terminal A has 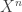


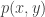

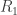

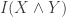


The difference between total variation and joint typicality requirements is the following.
There is a weak and strong way to interpret the statement:
“A has X^n and terminal B wants to generate Y^n such that (X^n, Y^n) look jointly iid with distribution p(x,y)”
The weak interpretation just requires that (X^n, Y^n) be jointly (strong) typical. That is, only requires that that the ‘per-letter’ joint distribution of X^n and Y^n look like p(x,y). If you take this interpretation, R1= I(X^Y) is the number you need, even w/o common randomness. To see this, what you need is essentially a (lossy) reconstruction Y^n for source seq X^n, since lossy source codes basically simulate joint distributions. But…
if you do the above, the output SEQUENCE Y^n will not ‘look’ like its been produced by a `source’ (because) there are only 2^{nI(X^Y}} reconstruction sequences in the source code. The total variational distance criterion basically requires that Y^n (and (X^n,Y^n) as well) are as if they have been produced by a source. So we need additional bits to produce all the required 2^{nH(Y)} sequences so that everything looks as if produced from a source. Common randomness can eliminate the need for additional bits
I think its a subtle, but interesting difference.