This is the second part in my blogging about some of the talks I saw at ITA 2008, and also a way for me to test a tag so that readers who don’t care about information theory won’t have a huge post hogging up their aggregator window (livejournal, I’m looking at you). Again, I may have misunderstood something in the talks, so if you see something that doesn’t sound right, let me know.
The compound Gaussian interference channel
A. Raja, V. Prabhakaran, and P. Viswanath, UIUC
This paper looked at the Gaussian compound interference channel, defined by the following two equations:

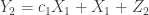
Recent work of Etkin, Tse, and Wang has provided a “within one bit” characterization of the capacity region of regular interference channels with known 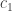
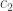
Information theoretic operating regimes of large ad hoc wireless networks
Ayfer Ozgur, Ramesh Johari, David Tse, UC Berkeley, and Olivier Leveque
Shannon’s famous AWGN capacity formula (that includes bandwidth) identifies two key operating regimes for the point-to-point systems. In the bandwidth limited regime, where SNR is high, capacity scales linearly with the bandwidth. In the power limited regime, where SNR is low, the capacity scales linearly with SNR. The question posed (and answered in some sense) in this talk is “is there an equivalent notion for large wireless networks?” They take a network of nodes on a grid with random source-destination pairs, distance-based path loss, and random phase. There are two parameters: 



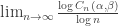
This is a scaling-law sense of capacity. They then identify four regimes in terms of
Secrecy when the relay is the eavesdropper
Xiang He and Aylin Yener, Penn State
This talk looked at the wiretap problem with an eavesdropper co-located with a relay, or alternatively, designing protocols in which you don’t want the relay to decode your message. So decode-and-forward is right out, but compress-and-forward (CF) is still ok. Can a relay still help even if it’s not trusted? Some partial results have been found by Oohama for a certain degradedness condition that I’m not clear on at the moment, but in the the talk they looked at CF schemes that can achieve the secrecy rate point on the rate-equivocation tradeoff curve. That is, the relay learns nothing about the message, but the destination can decode. Prof. Yener discussed two examples of relay channels with orthogonal components. If the there are orthogonal links from the source to the destination and relay, as in El Gamal-Zahedi, then the relay cannot be used to increase data rates while preserving secrecy, whereas if there are orthogonal links from the source and relay to the destination, as in Liang-Veeravalli, then it does help.
Coding and common knowledge
Yossef Steinberg, Technion
This talk was about a different kind of rate distortion problem. The setup is like the Wyner-Ziv problem, but the encoder should also know be able to create the reconstruction 
![R_{ck}(D) = \min [ I(\hat{X} \wedge X) - I(\hat{X} \wedge Y) ]](https://s0.wp.com/latex.php?latex=R_%7Bck%7D%28D%29+%3D+%5Cmin+%5B+I%28%5Chat%7BX%7D+%5Cwedge+X%29+-+I%28%5Chat%7BX%7D+%5Cwedge+Y%29+%5D&bg=ffffff&fg=333333&s=0&c=20201002)
This reduces to a scheme like the following: “the encoder quantizes 

