Graph Sampling Techniques for Studying Unstructured Overlays
Amir Hassan Rasti Ekbatani (University of Oregon, US); Mojtaba Torkjazi (University of Oregon, US); Reza Rejaie (University of Oregon, US); Nick Duffield (AT&T Labs – Research, US); Walter Willinger (AT&T Labs – Research, US); Daniel Stutzbach (Stutzbach Enterprises LLC, US)
The question in this paper was how to collect network statistics (such as node degree) in peer-to-peer networks. Since peers join and leave, selecting a random peer is difficult because there are biases caused by high-degree peers and low-lifetime peers. One approach to correct for this is to use Markov chain Monte Carlo (MCMC) to sample from the nodes. This talk proposed respondent-driven sampling (RDS), a technique used to map social networks. The idea is to do a random walk on the network and gather statistics along the walk (not just at the end, as in MCMC). These measurements are biased, but then we can correct for the bias at the end (using something called the Hansen-Hurwitz estimator, which I don’t know much about). Experimental works showed a big improvement when vanilla MCMC and RDS were compared on hierarchical scale-free graphs.
A Framework for Efficient Class-based Sampling
Mohit Saxena (Purdue University, US); Ramana Rao Kompella (Purdue University, US)
This talk was about increasing the coverage of monitoring flows in networks. Currently routers sample flows uniformly, which catches the big “elephant” flows but not the low-volume “mouse” flows. In order to increase coverage, the authors propose dividing flows into classes and then sample the classes. So the architecture is to classify a packet first, then choose whether to sample it. The goal is to do a combination of sketching and hashing that shifts the complexity to slower memory, thereby saving costs. They use something called a composite Bloom filter to do this.
Estimating Hop Distance Between Arbitrary Host Pairs
Brian Eriksson (University of Wisconsin – Madison, US); Paul Barford (University of Wisconsin – Madison, US); Rob Nowak (University of Wisconsin, Madison, US)
Given a big network (like the internet) with 

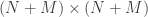

I have also noticed the following paper, seemed very interesting and provided a general theorem for convergence of the consensus algorithms:
On the Convergence of Non-Stationary Perturbed Consensus Algorithms by Tuncer C. Aysal (Cornell University) and Kenneth E. Barner (University of Delaware)
You should check it out :)
Yes, but unfortunately I couldn’t go to that talk since it was parallel to mine :-P