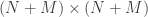This was my first time going to Infocom, and I had a good time, despite being a bit out of my element. The crowd is a mix of electrical engineers and computer scientists, of theorists, experimentalists, and industry researchers. Although I often would go to a talk thinking I knew what it would be about, I often found that it was rather different than what I expected. At first this was a little alienating, but in the end I found it refreshing to be introduced to a host of new ideas and problems. Unfortunately, the lack of familiarity may translate into some misunderstandings in these posts; as usual, clarifying comments are welcome!
Below are the papers I couldn’t categorize into other areas.
Dynamic Power Allocation Under Arbitrary Varying Channels – An Online Approach
Niv Buchbinder (Technion University, IL); Liane Lewin-Eytan (Technion, IL); Ishai Menache (Massachusetts Institute of Technology, US); Joseph (Seffi) Naor (Technion, IL); Ariel Orda (Technion, IL)
The model is that of an online power allocation problem wherein the gain of a fading channel 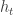 varies over time in an unpredictable manner. At each time we can choose a power
varies over time in an unpredictable manner. At each time we can choose a power  for the transmitter based on the past values
for the transmitter based on the past values  and we will get a reward
and we will get a reward  . Subject to a total power constraint, what is the optimal allocation policy, in terms of competitive optimality vs. an algorithm that knew in advance? They show lower bounds for any algorithm of
. Subject to a total power constraint, what is the optimal allocation policy, in terms of competitive optimality vs. an algorithm that knew in advance? They show lower bounds for any algorithm of  for the competitive ratio and an achievable strategy by quantizing the possible fading values and executing an online allocations strategy for the discrete problem. Of course I went to this talk because it claimed to be about arbitrarily varying channels, but what was a little unconvincing to me was the abstraction — you have to choose not only a transmit power, but also a coding rate, so it’s unclear that in reality you will get
for the competitive ratio and an achievable strategy by quantizing the possible fading values and executing an online allocations strategy for the discrete problem. Of course I went to this talk because it claimed to be about arbitrarily varying channels, but what was a little unconvincing to me was the abstraction — you have to choose not only a transmit power, but also a coding rate, so it’s unclear that in reality you will get 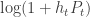 utility each time. There may be a way to justify this kind of modeling using some rateless code constructions, which seems like an interesting problem to think about. UPDATE: I looked at the paper and saw that they are considering a block fading channel so you get that utility for a block of channel uses, and that the channel gain for the given slot is revealed to the transmitter, so you don’t need to be fancy with the underlying communication scheme.
utility each time. There may be a way to justify this kind of modeling using some rateless code constructions, which seems like an interesting problem to think about. UPDATE: I looked at the paper and saw that they are considering a block fading channel so you get that utility for a block of channel uses, and that the channel gain for the given slot is revealed to the transmitter, so you don’t need to be fancy with the underlying communication scheme.
Lightweight Coloring and Desynchronization for Networks
Arik Motskin (Stanford University, US); Tim Roughgarden (Stanford University, US); Primoz Skraba (Stanford University, US); Leonidas Guibas (Stanford University, US)
This paper was on duty-cyling nodes in a sensor network to preserve power and avoid interference. In particular, we would like to color the  nodes of the network so that no two neighbors are awake at the same time (thereby improving coverage efficiency and lowering interference to a centralized receiver). This can be mapped to problem of allocating intervals on a circle of circumference
nodes of the network so that no two neighbors are awake at the same time (thereby improving coverage efficiency and lowering interference to a centralized receiver). This can be mapped to problem of allocating intervals on a circle of circumference  (the cycle time) such that two neighbors in the graph do not get overlapping intervals. Nodes with low degree should get longer intervals. The constraint in this assignment problem is that the solution must be decentralized and require minimal internal state and external inputs. They show an algorithm which uses one bit of local state to use
(the cycle time) such that two neighbors in the graph do not get overlapping intervals. Nodes with low degree should get longer intervals. The constraint in this assignment problem is that the solution must be decentralized and require minimal internal state and external inputs. They show an algorithm which uses one bit of local state to use  colors in
colors in 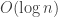 time, and an algorithm with one bit of local state and one bit of external side information to color the graph with
time, and an algorithm with one bit of local state and one bit of external side information to color the graph with  colors in
colors in  rounds.
rounds.
Using Three States for Binary Consensus on Complete Graphs
Etienne Perron (EPFL, Switzerland); Dinkar Vasudevan (EPFL, Switzerland); Milan Vojnovic (Microsoft Research, UK)
This paper looked at a binary consensus problem that was seemed on the face of it quite different from the consensus algorithms that I work on. They consider a complete graph where every node has a an initial value that is either 0 or 1. The goal is to compute the majority vote in all the nodes in a distributed manner while requiring only a small state in each of the nodes. This is related to a standard voter model, in which nodes sample their neighbor and switch their vote if it is different. If we have 3 states, (0, e, 1), where e is “undecided” then we can make a rule where a node samples its neighbor and moves one step in direction reported by the neighbor. Different variants of the algorithm are also analyzed, and the error rate analysis seemed a bit hairy, involving ODEs and so on. What I was wondering at the end is the relationship of this algorithm to standard gossip with one bit quantization of messages.