I’m still catching up on my backlog of reading everything, but I’ve decided to set some time aside to take a look at a few papers from ArXiV.
- Lecture Notes on Free Probability by Vladislav Kargin, which is 100 pages of notes from a course at Stanford. Pretty self-explanatory, except for the part where I don’t really know free probability. Maybe reading these will help.
- Capturing the Drunk Robber on a Graph by Natasha Komarov and Peter Winkler. This is on a simple pursuit-evasion game in which the robber (evader) is moving according to a random walk. On a graph with
vertices:
the drunk will be caught with probability one, even by a cop who oscillates on an edge, or moves about randomly; indeed, by any cop who isn’t actively trying to lose. The only issue is: how long does it take? The lazy cop will win in expected time at most
(plus lower-order terms), since that is the maximum possible expected hitting time for a random walk on an n-vertex graph [2]; the same bound applies to the random cop [4]. It is easy to see that the greedy cop who merely moves toward the drunk at every step can achieve
; in fact, we will show that the greedy cop cannot in general do better. Our smart cop, however, gets her man in expected time
.
How do you make a smarter cop? In this model the cop can tell where the robber is but has to get there by walking along the graph. Strategies which try to constantly “retarget” are wasteful, so they propose a strategy wherein the cop periodically retargets to eventually meet the robber. I feel like there is a prediction/learning algorithm or idea embedded in here as well.
- Normalized online learning by Stephane Ross, Paul Mineiro, John Langford. Normalization and data pre-processing is the source of many errors and frustrations in machine learning practice. When features are not normalized with respect to each other, procedures like gradient descent can behave poorly. This paper looks at dealing with data normalization in the algorithm itself, making it “unit free” in a sense. It’s the same kind of weights-update rule that we see in online learning but with a few lines changed. They do an adversarial analysis of the algorithm where the adversary gets to scale the features before the learning algorithm gets the data point. In particular, the adversary gets to choose the covariance of the data.
- On the Optimality of Treating Interference as Noise, by Chunhua Geng, Navid Naderializadeh, A. Salman Avestimehr, and Syed A. Jafar. Suppose I have a
-user interference channel with gains
between transmitter
and receiver
. Then if
then treating interference as noise is optimal in terms of generalized degrees of freedom. I don’t really work on this kind of thing, but it’s so appealing from a sense of symmetry. - Online Learning under Delayed Feedback, byPooria Joulani, András György, Csaba Szepesvári. This paper is on forecasting algorithms which receive the feedback (e.g. the error) with a delay. Since I’ve been interested in communication with delayed feedback, this seems like a natural learning analogue. They provide ways of modifying existing algorithms to work with delayed feedback — one such method is to run a bunch of predictors in parallel and update them as the feedback is returned. They also propose methods which use partial monitoring and an approach to UCB for bandit problems in the delayed feedback setting.
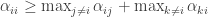
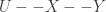 which I had found interesting:
which I had found interesting: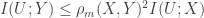 .
. , but by another quantity:
, but by another quantity:
 is given by the following definition.
is given by the following definition. and
and  be random variables with joint distribution
be random variables with joint distribution  . We define
. We define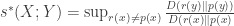 ,
, denotes the
denotes the  -marginal distribution of
-marginal distribution of  and the supremum on the right hand side is over all probability distributions
and the supremum on the right hand side is over all probability distributions 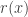 that are different from the probability distribution
that are different from the probability distribution  . If either
. If either  to be 0.
to be 0.
 have joint distribution
have joint distribution  (I know I am changing notation here but it’s easier to explain). The key to showing their result is through deriving variational characterizations of
(I know I am changing notation here but it’s easier to explain). The key to showing their result is through deriving variational characterizations of 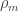 and
and 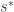 in terms of the function
in terms of the function
 , and
, and 
 ? If either
? If either 
 . However,
. However, 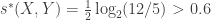 and there exists a sequence of variables
and there exists a sequence of variables  satisfying the Markov chain such that
satisfying the Markov chain such that  such that the ratio approaches
such that the ratio approaches  be
be 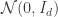 in
in 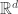 . The convex hull
. The convex hull  of these points is called a Gaussian polytope. This is a random polytope of course, and we can ask various things about their shape : what is the distribution of the number of vertices, or the number of
of these points is called a Gaussian polytope. This is a random polytope of course, and we can ask various things about their shape : what is the distribution of the number of vertices, or the number of  -faces? Let
-faces? Let  be the number of
be the number of  ) is given by
) is given by![\mathbb{E}[ f_k(P_n)] = \frac{2^d}{\sqrt{d}} \binom{d}{k+1} \beta_{k,d-1}(\pi \ln n)^{(d-1)/2} (1 + o(1))](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+f_k%28P_n%29%5D+%3D+%5Cfrac%7B2%5Ed%7D%7B%5Csqrt%7Bd%7D%7D+%5Cbinom%7Bd%7D%7Bk%2B1%7D+%5Cbeta_%7Bk%2Cd-1%7D%28%5Cpi+%5Cln+n%29%5E%7B%28d-1%29%2F2%7D+%281+%2B+o%281%29%29&bg=ffffff&fg=333333&s=0&c=20201002) ,
,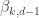 is the internal angle of a regular
is the internal angle of a regular  -simplex at one of its
-simplex at one of its  such that
such that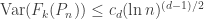
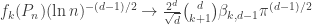
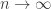 . That is, appropriately normalized, the number of faces converges to a constant.
. That is, appropriately normalized, the number of faces converges to a constant.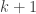 points to define a
points to define a  fraction of them will form a real
fraction of them will form a real  , regardless of
, regardless of  -divergences, which are given by
-divergences, which are given by
 — you have to take the limit as
— you have to take the limit as 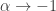 . Within this family of divergences we have the relation
. Within this family of divergences we have the relation  . Consider a pair of random variables
. Consider a pair of random variables 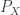 and
and 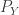 . If we take
. If we take  and
and  then the mutual information is
then the mutual information is  . But we can also take
. But we can also take
 , there is a convex probability distribution
, there is a convex probability distribution  on the real line with a finite entropy, such that
on the real line with a finite entropy, such that  , where
, where 