I’ve posted my submission (and by extension, the Rutgers ECE submission) for the ITAVision 2015 competition: Lossless.
Tag Archives: information theory
Feature Engineering for Review Times
The most popular topic of conversation among information theory afficionados is probably the long review times for the IEEE Transactions on Information Theory. Everyone has a story of a very delayed review — either for their own paper or for a friend of theirs. The Information Theory Society Board of Governors and Editor-in-Chief have presented charts of “sub-to-pub” times and other statistics and are working hard on ways to improve the speed of reviews without impairing their quality. These are all laudable. But it occurs to me that there is room for social engineering on the input side of things as well. That is, if we treat the process as a black box, with inputs (papers) and outputs (decisions), what would a machine-learning approach to predicting decision time do?
Perhaps the most important (and overlooked in some cases) aspects of learning a predictor from real data is figuring out what features to measure about each of the inputs. Off the top of my head, things which may be predictive include:
- length
- number of citations
- number of equations
- number of theorems/lemmas/etc.
- number of previous IT papers by the authors
- h-index of authors
- membership status of the authors (student members to Fellows)
- associate editor handling the paper — although for obvious reasons we may not want to include this
I am sure I am missing a bunch of relevant measurable quantities here, but you get the picture.
I would bet that paper length is a strong predictor of review time, not because it takes a longer time to read a longer paper, but because the activation energy of actually picking up the paper to review it is a nonlinear function of the length.
Doing a regression analysis might yield some interesting suggestions on how to pick coauthors and paper length to minimize the review time. This could also help make the system go faster, no? Should we request these sort of statistics from the EiC?
Fenchel duality, entropy, and the log partition function
[Update: As Max points out in the comments, this is really a specialized version of the Donsker-Varadhan formula, also mentioned by Mokshay in a comment here. I think the difficulty with concepts like these is that they are true for deeper reasons than the ones given when you learn them — this is a special case that requires undergraduate probability and calculus, basically.]
One of my collaborators said to me recently that it’s well known that the “negative entropy is the Fenchel dual of the log-partition function.” Now I know what these words meant, but it somehow was not a fact that I had learned elsewhere, and furthermore, a sentence like that is frustratingly terse. If you already know what it means, then it’s a nice shorthand, but for those trying to figure it out, it’s impenetrable jargon. I tried running it past a few people here who are generally knowledgeable but are not graphical model experts, and they too were unfamiliar with it. While this is just a simple thing about conjugate duality, I think it doesn’t really show up in information theory classes unless the instructor talks a bit more about exponential family distributions, maximum entropy distributions, and other related concepts. Bert Huang has a post on Jensen’s inequality as a justification.
We have a distribution in the exponential family:

As a side note, I often find that the exponential family is not often covered in systems EE courses. Given how important it is in statistics, I think it should be a bit more of a central concept — I’m definitely going to try and work it in to the detection and estimation course.
For the purposes of this post I’m going to assume 
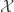
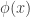



Where the partition function is

The entropy of the distribution is easy to calculate:
![H(p) = \mathbb{E}[ - \log p(x; \theta) ] = A(\theta) - \langle \theta, \mathbb{E}[\phi(x)] \rangle](https://s0.wp.com/latex.php?latex=H%28p%29+%3D+%5Cmathbb%7BE%7D%5B+-+%5Clog+p%28x%3B+%5Ctheta%29+%5D+%3D+A%28%5Ctheta%29+-+%5Clangle+%5Ctheta%2C+%5Cmathbb%7BE%7D%5B%5Cphi%28x%29%5D+%5Crangle&bg=ffffff&fg=333333&s=0&c=20201002)
The Fenchel dual of a function 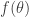
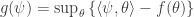
So what’s the Fenchel dual of the log partition function? We have to take the gradient:
![\nabla_{\theta} \left( \langle \psi, \theta \rangle - A(\theta) \right) = \psi - \frac{1}{Z(\theta)} \sum_{x} \exp( \langle \theta, \phi(x) \rangle ) \phi(x) = \psi - \mathbb{E}[ \phi(x) ]](https://s0.wp.com/latex.php?latex=%5Cnabla_%7B%5Ctheta%7D+%5Cleft%28+%5Clangle+%5Cpsi%2C+%5Ctheta+%5Crangle+-+A%28%5Ctheta%29+%5Cright%29+%3D+%5Cpsi+-+%5Cfrac%7B1%7D%7BZ%28%5Ctheta%29%7D+%5Csum_%7Bx%7D+%5Cexp%28+%5Clangle+%5Ctheta%2C+%5Cphi%28x%29+%5Crangle+%29+%5Cphi%28x%29+%3D+%5Cpsi+-+%5Cmathbb%7BE%7D%5B+%5Cphi%28x%29+%5D&bg=ffffff&fg=333333&s=0&c=20201002)
So now setting this equal to zero, we see that at the optimum 
![\langle \psi, \theta^* \rangle = \langle \mathbb{E}[ \phi(x) ], \theta^* \rangle](https://s0.wp.com/latex.php?latex=%5Clangle+%5Cpsi%2C+%5Ctheta%5E%2A+%5Crangle+%3D+%5Clangle+%5Cmathbb%7BE%7D%5B+%5Cphi%28x%29+%5D%2C+%5Ctheta%5E%2A+%5Crangle&bg=ffffff&fg=333333&s=0&c=20201002)
And the dual function is:
![g(\psi) = \langle \mathbb{E}[ \phi(x) ], \theta^* \rangle - A(\theta^*) = - H(p)](https://s0.wp.com/latex.php?latex=g%28%5Cpsi%29+%3D+%5Clangle+%5Cmathbb%7BE%7D%5B+%5Cphi%28x%29+%5D%2C+%5Ctheta%5E%2A+%5Crangle+-+A%28%5Ctheta%5E%2A%29+%3D+-+H%28p%29&bg=ffffff&fg=333333&s=0&c=20201002)
The standard approach seems to go the other direction by computing the dual of the negative entropy, but that seems more confusing to me (perhaps inspiring Bert’s post above). Since the log partition function and negative entropy are both convex, it seems easier to exploit the duality to prove it in one direction only.
Allerton 2014: hypercontracting interference channels while noisily feeding back what you detected on the graph
Before the expiration window passes, here are few more short takes from Allerton… for some talks I couldn’t take notes because I didn’t get a seat or I missed half the talk shuttling between sessions.
The Gaussian Channel with Noisy Feedback: Near-Capacity Performance Via Simple Interaction
Assaf Ben-Yishai, Ofer Shayevitz
This was a really nice talk by Ofer on trying to get practical codes for AWGN channels with noisy feedback by using the intuition given by the Schalkwijk-Kailath scheme plus some tricks from using the mod operation. This is reminiscent of lattices (which may be an interesting future direction). The SK scheme has a problem with noise accumulation, which they deal with using these mode operations, and can get to errors around 10^(-6) with around 19 rounds, or blocklength 19 at reasonable SNRs. Blocklength is misleading here since there is feedback every symbol. The other catch is that the feedback link must have much higher SNR than the forward link, but this is true in applications such as sensing, where the receiver may be plugged into the wall, but the transmitter may be on a swallowable medical monitoring device.
Point-To-Point Codes for Interference Channels: A Journey Toward High Performance at Low Complexity
Young-Han Kim
Continuing with my UCSD bias, I also wanted to mention Young-Han’s talk, which was on using COTS (commercial, off-the-shelf) coding schemes on the interference channel (in particular, the 2 user IC). He talked about rate splitting approaches and block Markov schemes. Much of this work is with Lele Wang, who may be graduating soon…
Signal Detection on Graphs
Venkatesh Saligrama
This was a hypothesis testing problem where the observations come from nodes on graph. Under the null, they are Gaussian noise, and under the other hypothesis, there is a connected subgraph with an elevated mean. How should we do detection in this scenario? This is a compound hypothesis testing problem because there are (too) many possible connected subgraphs to consider. He gets around this by looking at a convex program parameterized by a measure of the size/shape of the connected component. This is where my notes get messy though, so you might want to look at the paper if it sounds interesting to you…
Hypercontractivity in Hamming Space
Yury Polyanskiy
I’ve hypercontractivity before, and Yury talked about his paper on ArXiV, which is about functions on the binary hypercube. This talk felt more like a tour of results on hypercontractivity and less like a “here is my new result” talk, which I actually appreciated because I felt it tied together ideas well and made me realize how strange the hypercontractivity parameter of an operator is.
Allerton 2014: privately charging your information odometer while realizing your group has pretenders
Here are a few papers that I saw at Allerton — more to come later.
Group Testing with Unreliable Elements
Arya Mazumdar, Soheil Mohajer
This was a generalization of the group testing problem: items are either positive or null, and can be tested in groups such that if any element of the group is positive, the whole group will test positive. The item states can be thought of as a binary column vector 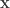







The Minimal Realization Problems for Hidden Markov Models
Qingqing Huang, Munther Dahleh, Rong Ge, Sham Kakade
The realization problem for an HMM is this: given the exact joint probability distribution on length 
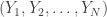
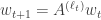
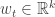
We think of 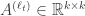

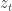
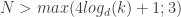


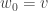

Differentially Private Distributed Protocol for Electric Vehicle Charging
Shuo Han, Ufuk Topcu, George Pappas
This paper was about a central aggregator trying to get multiple electric vehicle users to report their charging needs. The central allocator has a utility maximization problem over the rates of charging:
They focus on the case where the charge demands 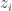

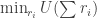
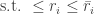

An Interactive Information Odometer and Applications
Mark Braverman and Omri Weinstein
This was a communication complexity talk about trying to maintain an estimate of the information complexity of a protocol 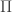




Previous work has shown that the (normalized) communication complexity of computing 




Research Linkage
I’ve been a bit bogged down upon getting back from traveling, but here are a few interesting technical tidbits that came through.
Aaron Roth and Cynthia Dwork’s Foundation and Trends monograph on differential privacy is now available.
Speaking of differential privacy, Shiva Kasiviswanathan and Adam Smith have a paper in the Journal of Privacy and Confidentiality on Bayesian interpretations of differential privacy risk.
Deborah Mayo has a post up on whether p-values are error probabilities.
Raymond Yeung is offering a Coursera course on information theory (via the IT Society).
A CS Theory take on Fano’s inequality from Suresh over at the GeomBlog.
SPCOM 2014: some more talks (and a plenary)
I did catch Greg Wornell’s plenary at SPCOM, which was called When Bits Absolutely, Positively, Have to be There as Soon as Possible, a riff on this FedEx commercial, which is older than I am. The talk was on link-aware PHY-layer design– basically looking at how ARQ enables incremental redundancy, and how to do a sort of layered superposition + incremental redundancy scheme in the sequential setting as well as a “multi-path” setting where blocks can arrive out of order. This was really digging into the signal issues in a way that a lot of non-communication engineering information theorists may get squeamish about. The nice thing is that I think the engineering problem is approachable without knowing a lot of heavy-duty math, but still requires some careful analysis.
Communication and Compression Via Sparse Linear Regression
Ramji Venkataramanan
This was on building codewords and codebooks out of a lower-complexity code dictionary 




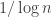
An Optimal Varentropy Bound for Log-Concave Distributions
Mokshay Madiman; Liyao Wang
Mokshay’s talk was also really clear and excellent. For a distribution 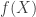


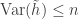

Event-triggered Sampling and Reconstruction of Sparse Real-valued Trigonometric Polynomials
Neeraj Sharma; Thippur V. Sreenivas
This was on non-uniform sampling where the sampler tries to detect level crossings of the analog signal and samples at that point — the rate may not be uniform enough to use existing nonuniform sampling techniques. They come up with a method for reconstructing signals which are real-valued trigonometric polynomials with a few nonzero coefficients (e.g. sparse) and it seems to work pretty decently in experiments.
Removing Sampling Bias in Networked Stochastic Approximation
Vivek Borkar; Raaz Dwivedi
In networked stochastic approximation, the intermittent communication between nodes may mean that the system tracks a different ODE than the one we want. By modifying the method to account for “local clocks” on each edge, we can correct for this, but we end up with new conditions on the step size to make things work. I am pretty excited about this paper, but as usual, my notes were not quite up to getting the juicy bits. That’s what paper reading is for.
On Asymmetric Insertion and Deletion Errors
Ankur A. Kulkarni
The insertion/deletion channel model is notoriously hard. Ankur proposed a new model where 

A teaser for ITAVision 2015
As part of ITAVision 2015 we are soliciting individuals and groups to submit videos documenting their love of information theory and/or its applications. During ISIT we put together a little example with our volunteers (it sounded better in rehearsal than at the banquet, alas). The song was Entropy is Awesome based on this, obviously. If you want to sing along, here is the Karaoke version:
The lyrics (so far) are:
Entropy is awesome!
Entropy is sum minus p log p
Entropy is awesome!
When you work on I.T.Blockwise error vanishes as n gets bigger
Maximize I X Y
Polarize forever
Let’s party foreverI.I.D.
I get you, you get me
Communicating at capacityEntropy is awesome…
This iteration of the lyrics is due to a number of contributors — truly a group effort. If you want to help flesh out the rest of the song, please feel free to email me and we’ll get a group effort going.
More details on the contest will be forthcoming!
SPCOM 2014: some talks
Relevance Singular Vector Machine for Low-rank Matrix Sensing
Martin Sundin; Saikat Chatterjee; Magnus Jansson; Cristian Rojas
This talk was on designing Bayesian priors for sparse-PCA problems — the key is to find a prior which induces a low-rank structure on the matrix. The model was something like 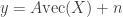
Non-Convex Sparse Estimation for Signal Processing
David Wipf
More Bayesian methods! Although David (who I met at ICML) was not trying to say that the priors are particularly “correct,” but rather that the penalty functions that they induce on the problems he is studying actually make sense. More of an algorithmist’s approach, you might say. He set up the problem a bit more generally, to minimize problems of the form
where 
![\min_{X_i} \sum_{i} \alpha_i \mathrm{rank}[X_i] \ \ \ \ \ \ \ Y = \sum_{i} A_i(X_i)](https://s0.wp.com/latex.php?latex=%5Cmin_%7BX_i%7D+%5Csum_%7Bi%7D+%5Calpha_i+%5Cmathrm%7Brank%7D%5BX_i%5D+%5C+%5C+%5C+%5C+%5C+%5C+%5C+Y+%3D+%5Csum_%7Bi%7D+A_i%28X_i%29&bg=ffffff&fg=333333&s=0&c=20201002)
PCA-HDR: A Robust PCA Based Solution to HDR Imaging
Adit Bhardwaj; Shanmuganathan Raman
My apologies for taking fewer notes on this one, but I don’t know much about HDR imaging, so this was mostly me learning about HDR image processing. There are several different ways of doing HDR, from multiple exposures to flash/no-flash, and so on. The idea is that artifacts introduced by the camera can be modeled using the robust PCA framework and that denoting in HDR imaging may be better using robust PCA. I think that looking at some of the approaches David mentioned may be good in this domain, since it seems unlikely to me that these images will satisfy the conditions necessary for convex relaxations to work…
On Communication Requirements for Secure Computation
Vinod M Prabhakaran
Vinod showed some information theoretic approaches to understanding how much communication is needed for secure computation protocols like remote oblivious transfer: Xavier has 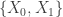
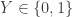
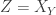
Artificial Noise Revisited: When Eve Has More Antennas Than Alice
Shuiyin Liu; Yi Hong; Emanuele Viterbo
In a MIMO wiretap setting, if the receiver has more antennas than the transmitter, then the transmitter can send noise in the nullspace of the channel matrix of the direct channel — as long as the eavesdropper has fewer antennas than the transmitter then secure transmission is possible. In this paper they show that positive secrecy capacity is possible even when the eavesdropper has more antennas, but as the number of eavesdropper antennas grows, the achievable rate goes to
SPCOM 2014: tutorials
I just attended SPCOM 2014 at the Indian Institute of Science in Bangalore — many thanks to the organizers for the invitation! SPCOM 2014 happens every two years and is a mix of invited and submitted papers (much like Allerton). This year they mixed the invited talks with the regular talks which I thought was a great idea — since invited papers were not for specific sessions, it makes a lot more sense to do it that way, plus it avoids a sort of “two-tier” system.
I arrived early enough to catch the tutorials on the first day. There was a 3 hour session in the morning and another on the in afternoon. For the morning I decided to expand my horizons by attending Manoj Gopalkrishnan‘s tutorial on the physics of computation. Manoj focused on the question of how much energy it takes to erase or copy a bit of information. He started with some historical context via von Neumann, Szilard, and Landauer to build a correspondence between familiar information theoretic concepts and their physical counterparts. So in this correspondence, relative entropy is the same as free energy. He then turned to look at what one might call “finite time” thermodynamics. Suppose that you have to apply a control that operates in finite time in order to change a bit. One way to look at this is through controlling the transition probabilities in a two-state Markov chain representing the value of the bit you want to fix. You want to drive the resting state (with stationary distribution 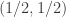


Prasad Santhanam gave the other tutorial, which was a bit more solid ground for me. This was not quite a tutorial on large-alphabet probability estimation, but more directly on universal compression and redundancy calculations. The basic setup is that you have a family of distributions 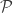

I’ll try to write another post or two about the talks I saw as well!
