I just attended SPCOM 2014 at the Indian Institute of Science in Bangalore — many thanks to the organizers for the invitation! SPCOM 2014 happens every two years and is a mix of invited and submitted papers (much like Allerton). This year they mixed the invited talks with the regular talks which I thought was a great idea — since invited papers were not for specific sessions, it makes a lot more sense to do it that way, plus it avoids a sort of “two-tier” system.
I arrived early enough to catch the tutorials on the first day. There was a 3 hour session in the morning and another on the in afternoon. For the morning I decided to expand my horizons by attending Manoj Gopalkrishnan‘s tutorial on the physics of computation. Manoj focused on the question of how much energy it takes to erase or copy a bit of information. He started with some historical context via von Neumann, Szilard, and Landauer to build a correspondence between familiar information theoretic concepts and their physical counterparts. So in this correspondence, relative entropy is the same as free energy. He then turned to look at what one might call “finite time” thermodynamics. Suppose that you have to apply a control that operates in finite time in order to change a bit. One way to look at this is through controlling the transition probabilities in a two-state Markov chain representing the value of the bit you want to fix. You want to drive the resting state (with stationary distribution 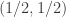


Prasad Santhanam gave the other tutorial, which was a bit more solid ground for me. This was not quite a tutorial on large-alphabet probability estimation, but more directly on universal compression and redundancy calculations. The basic setup is that you have a family of distributions 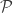

I’ll try to write another post or two about the talks I saw as well!
