More like an old paper… this (finally) a journal version of some older work that we did on analyzing Bayesian nonparametric estimators form an information-theoretic (redundancy) perspective.
Redundancy of Exchangeable Estimators
Narayana P. Santhanam, Anand D. Sarwate and Jae Oh WooExchangeable random partition processes are the basis for Bayesian approaches to statistical inference in large alphabet settings. On the other hand, the notion of the pattern of a sequence provides an information-theoretic framework for data compression in large alphabet scenarios. Because data compression and parameter estimation are intimately related, we study the redundancy of Bayes estimators coming from Poisson-Dirichlet priors (or “Chinese restaurant processes”) and the Pitman-Yor prior. This provides an understanding of these estimators in the setting of unknown discrete alphabets from the perspective of universal compression. In particular, we identify relations between alphabet sizes and sample sizes where the redundancy is small, thereby characterizing useful regimes for these estimators.
In the large alphabet setting, one thing we might be interested in is sequential prediction: I observe a sequence of butterfly species and want to predict whether the next butterfly I collect will be new or one that I have seen before. One simple way to do this prediction is to put a prior on the set of all distributions on infinite supports and do inference on that model given the data. This corresponds to the so-called Chinese Restaurant Process (CRP) approach to the problem. The information-theoretic view is that sequential prediction is equivalent to compression: the estimator is assigning a probability 
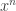


This sort of falls in with the “frequentist analysis of Bayesian procedures” thing which some people work on.
