I just submitted my CAREER proposal on Monday, and now that the endless revision process is over, I wanted to write a post about what I learned about proposal writing. But that seems like hubris, since I have no idea if the thing will get funded, so what do I know? Besides, everything I learned was from the valuable feedback I got from those who very kindly read my previous drafts. So instead of writing about How To Sell Your Idea, I figured I would write about some cute LaTeX hacks that I came across, most of them via the very useful TeX-LaTeX Stack Exchange.
If anyone else has some useful hacks, feel free to leave them in the comments!
Saving Space
One of the big problems in NSF proposal writing is that there’s a hard limit on the number of pages (not the number of words), so if you’re at the edge, there’s a lot of “oops, two lines over” hacking to be done towards the end.
\usepackage{times}\usepackage{mathptmx}timespackage is deprecated (see comments).\usepackage{titlesec}. This package lets you control the spacing around your titles and subtitles like this:
\titlespacing\section{0pt}{10pt plus 2pt minus 2pt}{2pt plus 2pt minus 2pt}
\titlespacing\subsection{0pt}{8pt plus 2pt minus 2pt}{2pt plus 2pt minus 2pt}
See this post for more details, but basically it’s
\titlespacing{command}{left spacing}{before spacing}{after spacing}. This is handy because there’s a lot of empty space around titles/subtitles and it’s an easy way to trim a few lines while making sure things don’t get too cramped/ugly.\usepackage{enumitem}: This package lets you control the spacing around yourenumeratelists. The package has a lot of options but one that may be handy is\setlist{nosep}which removes the space around the list items. This actually makes things a little ugly, I think, but bulleted lists are helpful to the reviewer and they also take a little more space, so this lets you control the tradeoff. Another thing that is handy to control is the left margin:\setlist[itemize,1]{leftmargin=20pt}.\usepackage{savetrees}: Prasad says it’s great, but I didn’t really use it. YMMV.
Customizations
- Sometimes it’s handy to have a new theorem environment for Specific Aims or Open Problems or what-have-you. The problem is (as usual) that the theorem environment by itself puts in extra space and isn’t particularly customizable. So one option is to define a new theorem style:
\newtheoremstyle{mystyle}% name
{5pt}%Space above
{5pt}%Space below
{\itshape}% Body font
{5pt}%Indent amount
{\bfseries}% Theorem head font
{:}%Punctuation after theorem head
{4pt}%Space after theorem head 2
{}%Theorem head spec (can be left empty, meaning ‘normal’)\theoremstyle{mystyle}
\newtheorem{specaim}{Specific Aim}
- Another handy hack is to make a different citation command to use for your own work that will then appear in a different color than normal citations if you use
\usepackage[colorlinks]{hyperref}. I learned how to do this by asking a question on the stack exchange.
\makeatletter
\newcommand*{\citeme}{%
\begingroup
\hypersetup{citecolor=red}%
\@ifnextchar[\citeme@opt\citeme@
}
\def\citeme@opt[#1]#2{%
\cite[{#1}]{#2}%
\endgroup
}
\newcommand*{\citeme@}[1]{%
\cite{#1}%
\endgroup
}
\makeatother
- The
hyperrefpackage also creates internal links to equations and Figures (if you label them) and so on, but the link is usually just the number of the label, so you have to click on “1” instead of “Figure 1” being the link. One way to improve this is to make a custom reference command:
\newcommand{\fref}[2]{\hyperref[#2]{#1 \ref*{#2}}}
So now you can write
\fref{Figure}{fig:myfig}to get “Figure 1” to be clickable. - You can also customize the colors for hyperlinks:
\hypersetup{
colorlinks,
citecolor=blue,
linkcolor=magenta,
urlcolor=MidnightBlue}
- Depending on your SRO, they may ask you to deactivate URLs in the references section. I had to ask to figure this out, but basically putting
\let\url\nolinkurlbefore the bibliography seemed to work…
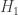 versus a composite hypothesis
versus a composite hypothesis  where under
where under  different distributions. There are therefore
different distributions. There are therefore  . This is a sort of generalized Neyman-Pearson setup. They look at the vector of log-likelihood ratios and show that a threshold test is nearly optimal. At the time, I understood the idea of the proof, but I think it’s one of things where you need to really read the paper.
. This is a sort of generalized Neyman-Pearson setup. They look at the vector of log-likelihood ratios and show that a threshold test is nearly optimal. At the time, I understood the idea of the proof, but I think it’s one of things where you need to really read the paper.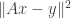 over
over  given
given  . A sketch would be to solve
. A sketch would be to solve 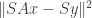 where
where  is a random projection. One question is how to choose
is a random projection. One question is how to choose  . They show that choosing
. They show that choosing 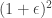 times the value of the original program as long as the the number of rows of
times the value of the original program as long as the the number of rows of  , where
, where 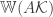 is the Gaussian width of the tangent cone of the contraint set at the optimum value. For more details look at their
is the Gaussian width of the tangent cone of the contraint set at the optimum value. For more details look at their  from phaseless measurements of the form
from phaseless measurements of the form 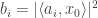 where
where  are complex spherically symmetric Gaussian vectors. Recovery from such measurements is nonconvex and tricky, but an alternating minimizing algorithm can reach a local optimum, and if you start it in a “good” initial position, it will find a global optimum. The contribution of this paper is provide such a smart initialization. The idea is to “pair” the measurements to create new measurements
are complex spherically symmetric Gaussian vectors. Recovery from such measurements is nonconvex and tricky, but an alternating minimizing algorithm can reach a local optimum, and if you start it in a “good” initial position, it will find a global optimum. The contribution of this paper is provide such a smart initialization. The idea is to “pair” the measurements to create new measurements  . This leads to a new problem (with half as many measurements) which is still hard, so they find a convex relaxation of that. I had thought briefly about such sensing setups a long time ago (and by thought, I mean puzzled over it at a coffeshop once), so it was interesting to see what was known about the problem.
. This leads to a new problem (with half as many measurements) which is still hard, so they find a convex relaxation of that. I had thought briefly about such sensing setups a long time ago (and by thought, I mean puzzled over it at a coffeshop once), so it was interesting to see what was known about the problem. samples from an unknown distribution
samples from an unknown distribution  and a set of distributions
and a set of distributions  to compare against. You want to find the distribution that is closest in
to compare against. You want to find the distribution that is closest in  . One way to do this is via Scheffe tournament tht compares all pairs of distributions — this runs in time
. One way to do this is via Scheffe tournament tht compares all pairs of distributions — this runs in time  time. They show a method that runs in
time. They show a method that runs in  time by studying the structure of the comparators used in the sorting method. The motivation is that running comparisons can be expensive (especially if they involve human decisions) so we want to minimize the number of comparisons. The paper is significantly different than the talk, but I think it would definitely be interesting to those interested in discrete algorithms. The density estimation problem is really just a motivator — the sorting problem is far more general.
time by studying the structure of the comparators used in the sorting method. The motivation is that running comparisons can be expensive (especially if they involve human decisions) so we want to minimize the number of comparisons. The paper is significantly different than the talk, but I think it would definitely be interesting to those interested in discrete algorithms. The density estimation problem is really just a motivator — the sorting problem is far more general.

