Inverted World [Christopher Priest]. A science-fiction novel, but of a piece with a writer like M. John Harrison — there’s a kind of disconnect and a focus on the conceptual world building rather than the nitty-gritty you get with Iain M. Banks. To avoid spoilers, I’ll just say it’s set in a city which moves through the world, always trying to be at a place called optimum. The city is on rails — it constantly builds fresh tracks ahead of it and winches itself forward a tenth of a mile per day. The city is run by a guild system of track layers, traction experts, bridge builders, surveyors, and the like. The protagonist, Helward Mann, takes an oath and joins a guild as an apprentice. The book follows his progress as he learns, and we learn, more about the strange world through which the city moves. Recommended if you like heady, somewhat retro, post-apocalyptic conceptual fiction.
Luka and the Fire of Life [Salman Rushdie]. A re-read for me, this didn’t hold up as well the second time around. I much prefer Haroun and the Sea of Stories, which I can read over and over again.
Boxers and Saints [Gene Luen Yang]. A great two-part graphic novel about the Boxer Rebellion in China. Chances are you don’t know much about this history. You won’t necessarily get a history lesson from this book, but you will want to learn more about it.
The Adventures of Augie March [Saul Bellow]. After leaving Chicago I have decided to read more books set in Chicago so that I can miss it more. I had read this book before but it was a rushed job. This time I let myself longer a bit more over Bellow’s language. It’s epic and scope and gave me a view of Chicago and the Great Depression that I hadn’t had before. Indeed, given our current economic woes, it was an interesting comparison to see the similarities (the rich are still pretty rich, and if you can get employed by them, you may do ok) and the dissimilarities.
The Idea Factory: Bell Labs and the Great Age of American Innovation [John Gertner]. A history of Bell Labs and a must-read for researchers who work on anything related to computing, communications, or applied physics and chemistry. It’s not all rah-rah, and while Gertner takes the “profiles of the personalities” approaches to writing about the place, I am sure there will be things in there that would surprise even the die-hard Shannonistas who may read this blog…
 where each codeword is a superposition of
where each codeword is a superposition of  columns, one each from groups of size
columns, one each from groups of size  . Thus encoding is
. Thus encoding is  where
where  is a sparse vector. I saw a talk by Barron and Joseph from a previous ISIT about this, but the framework extends to rate distortion (achieving the rate distortion function), and channel coding. The main point is to lower the complexity of the code at the expense of the gap to optimal rate — encoding and decoding are polynomial time but the rate gap for rate-distortion goes to zero as
is a sparse vector. I saw a talk by Barron and Joseph from a previous ISIT about this, but the framework extends to rate distortion (achieving the rate distortion function), and channel coding. The main point is to lower the complexity of the code at the expense of the gap to optimal rate — encoding and decoding are polynomial time but the rate gap for rate-distortion goes to zero as 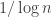 . Ramji gave a really nice and clear talk on this — I hope he puts the slides up!
. Ramji gave a really nice and clear talk on this — I hope he puts the slides up!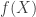 on
on  , we can define
, we can define  . The entropy is the expectation of this random variable, and the varentropy is the variance. Their main result is a upper bound on the varentropu of log concave distributions
. The entropy is the expectation of this random variable, and the varentropy is the variance. Their main result is a upper bound on the varentropu of log concave distributions 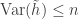 . This bound doesn’t depend on the distribution and is sharp if
. This bound doesn’t depend on the distribution and is sharp if  is a product of exponentials. They then use this to prove a universal bound on the deviation of
is a product of exponentials. They then use this to prove a universal bound on the deviation of  from its expectation, which gives a AEP that doesn’t really assume anything about the joint distribution of the variables except for log-concavity. There was more in the talk, but I eagerly await the paper.
from its expectation, which gives a AEP that doesn’t really assume anything about the joint distribution of the variables except for log-concavity. There was more in the talk, but I eagerly await the paper. ‘s are “indestructible” — they cannot be inserted or deleted. This asymmetric model leads to new asymptotic bounds on the capacity. I don’t really work on this channel model so I can’t get the finer points of the results, but once nice takeaway was that asymptotically, each indestructible
‘s are “indestructible” — they cannot be inserted or deleted. This asymmetric model leads to new asymptotic bounds on the capacity. I don’t really work on this channel model so I can’t get the finer points of the results, but once nice takeaway was that asymptotically, each indestructible  a deletion more.
a deletion more.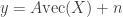 where
where  is a low-rank matrix and
is a low-rank matrix and  is noise. The previous state of the art is by
is noise. The previous state of the art is by ![\min_{X_i} \sum_{i} \alpha_i \mathrm{rank}[X_i] \ \ \ \ \ \ \ Y = \sum_{i} A_i(X_i)](https://s0.wp.com/latex.php?latex=%5Cmin_%7BX_i%7D+%5Csum_%7Bi%7D+%5Calpha_i+%5Cmathrm%7Brank%7D%5BX_i%5D+%5C+%5C+%5C+%5C+%5C+%5C+%5C+Y+%3D+%5Csum_%7Bi%7D+A_i%28X_i%29&bg=ffffff&fg=333333&s=0&c=20201002)
 are some operators. He made the case that convex relaxations of many of these problems, while analytically beautiful, have restrictions which are not satisfied in practice, and indeed they often have poor performance. His approach is via Empirical Bayes, but this leads to non-convex problems. What he can show is that the algorithm he proposes is competitive with any method that tries to separate the error from the “low-rank” constraint, and that the new optimization is “smoother.” I’m sure more details are in his various papers, for those who are interested.
are some operators. He made the case that convex relaxations of many of these problems, while analytically beautiful, have restrictions which are not satisfied in practice, and indeed they often have poor performance. His approach is via Empirical Bayes, but this leads to non-convex problems. What he can show is that the algorithm he proposes is competitive with any method that tries to separate the error from the “low-rank” constraint, and that the new optimization is “smoother.” I’m sure more details are in his various papers, for those who are interested.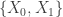 , Yvonne has
, Yvonne has 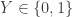 and Zelda wants
and Zelda wants 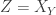 , but nobody should be able to infer each other’s values.
, but nobody should be able to infer each other’s values. 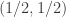 to something like
to something like  within time
within time  . At this level I more or less understood what was going on, but since my physics background is pretty poor, I think I missed out on how the physical intuition/constraints impact what control strategies you can choose.
. At this level I more or less understood what was going on, but since my physics background is pretty poor, I think I missed out on how the physical intuition/constraints impact what control strategies you can choose.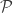 and you don’t know which distribution
and you don’t know which distribution  will generate your data. Based on the data sample you want to do something: estimate some property of the distribution, compress the sample to a size close to its entropy, etc. A class can be weakly or strongly compressible, or insurable (which means being able to estimate quantiles), and so on. These problems turn out to be a bit different from each other depending on some topological features of the class. One interesting thing to consider for the machine learners out there this stopping time that you need in some analyses. As you are going along, observing the data and doing your task (estimation, compression, etc) can you tell from the data that you are doing well? This has major implications for whether or not an online algorithm can even work the way we want it to, and is something Prasad calls “data-driven compressible.”
will generate your data. Based on the data sample you want to do something: estimate some property of the distribution, compress the sample to a size close to its entropy, etc. A class can be weakly or strongly compressible, or insurable (which means being able to estimate quantiles), and so on. These problems turn out to be a bit different from each other depending on some topological features of the class. One interesting thing to consider for the machine learners out there this stopping time that you need in some analyses. As you are going along, observing the data and doing your task (estimation, compression, etc) can you tell from the data that you are doing well? This has major implications for whether or not an online algorithm can even work the way we want it to, and is something Prasad calls “data-driven compressible.” where
where  is the Shannon capacity of the DMC. In the broadcast setting we run into the problem that the errors for the two receivers are entangled. However, their message sets are disjoint. The way out is to look at the average error for each (averaged over the other user’s message). The main result is that the rates only depend on the conditional marginals, and they have a strong converse.
is the Shannon capacity of the DMC. In the broadcast setting we run into the problem that the errors for the two receivers are entangled. However, their message sets are disjoint. The way out is to look at the average error for each (averaged over the other user’s message). The main result is that the rates only depend on the conditional marginals, and they have a strong converse. such that the probabilities are non-increasing. The redundancy for this class is infinite, alas, so they restrict the support to size
such that the probabilities are non-increasing. The redundancy for this class is infinite, alas, so they restrict the support to size  (where
(where 

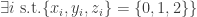
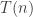 . More specifically, we want the rate of growth of this thing. That we have are upper and lower bounds:
. More specifically, we want the rate of growth of this thing. That we have are upper and lower bounds: .
.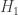 versus a composite hypothesis
versus a composite hypothesis  where under
where under  . This is a sort of generalized Neyman-Pearson setup. They look at the vector of log-likelihood ratios and show that a threshold test is nearly optimal. At the time, I understood the idea of the proof, but I think it’s one of things where you need to really read the paper.
. This is a sort of generalized Neyman-Pearson setup. They look at the vector of log-likelihood ratios and show that a threshold test is nearly optimal. At the time, I understood the idea of the proof, but I think it’s one of things where you need to really read the paper.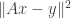 over
over  given
given  . A sketch would be to solve
. A sketch would be to solve 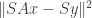 where
where  is a random projection. One question is how to choose
is a random projection. One question is how to choose  . They show that choosing
. They show that choosing 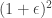 times the value of the original program as long as the the number of rows of
times the value of the original program as long as the the number of rows of  , where
, where 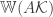 is the Gaussian width of the tangent cone of the contraint set at the optimum value. For more details look at their
is the Gaussian width of the tangent cone of the contraint set at the optimum value. For more details look at their  from phaseless measurements of the form
from phaseless measurements of the form 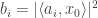 where
where  are complex spherically symmetric Gaussian vectors. Recovery from such measurements is nonconvex and tricky, but an alternating minimizing algorithm can reach a local optimum, and if you start it in a “good” initial position, it will find a global optimum. The contribution of this paper is provide such a smart initialization. The idea is to “pair” the measurements to create new measurements
are complex spherically symmetric Gaussian vectors. Recovery from such measurements is nonconvex and tricky, but an alternating minimizing algorithm can reach a local optimum, and if you start it in a “good” initial position, it will find a global optimum. The contribution of this paper is provide such a smart initialization. The idea is to “pair” the measurements to create new measurements  . This leads to a new problem (with half as many measurements) which is still hard, so they find a convex relaxation of that. I had thought briefly about such sensing setups a long time ago (and by thought, I mean puzzled over it at a coffeshop once), so it was interesting to see what was known about the problem.
. This leads to a new problem (with half as many measurements) which is still hard, so they find a convex relaxation of that. I had thought briefly about such sensing setups a long time ago (and by thought, I mean puzzled over it at a coffeshop once), so it was interesting to see what was known about the problem. samples from an unknown distribution
samples from an unknown distribution  and a set of distributions
and a set of distributions  to compare against. You want to find the distribution that is closest in
to compare against. You want to find the distribution that is closest in  . One way to do this is via Scheffe tournament tht compares all pairs of distributions — this runs in time
. One way to do this is via Scheffe tournament tht compares all pairs of distributions — this runs in time  time. They show a method that runs in
time. They show a method that runs in  time by studying the structure of the comparators used in the sorting method. The motivation is that running comparisons can be expensive (especially if they involve human decisions) so we want to minimize the number of comparisons. The paper is significantly different than the talk, but I think it would definitely be interesting to those interested in discrete algorithms. The density estimation problem is really just a motivator — the sorting problem is far more general.
time by studying the structure of the comparators used in the sorting method. The motivation is that running comparisons can be expensive (especially if they involve human decisions) so we want to minimize the number of comparisons. The paper is significantly different than the talk, but I think it would definitely be interesting to those interested in discrete algorithms. The density estimation problem is really just a motivator — the sorting problem is far more general.