I’d like to point out Alex Dimakis’s great post from last week on how to give a great ISIT talk (or any talk, really) and to put in a few bits more about a replicable process for writing talks that might help out students trying to write their first (or second, or third…) talk. As with any form of writing or communication, an unclear talk is usually the product of unclear thought on the part of the presenter. There’s no shortage of advice out there on how to give talks, but I figured I’d write down a process that I use to help streamline the process.
Before I get into the list, I have to issue a disclaimer : it’s not that I think I am super-great at giving talks. I am pretty good at critiquing talks to death, however. It must be the theater critic in me. What I have done is write down a process that has worked for me…
- Who is your audience? This is the place to start. If you are giving a talk at a conference, you may have a sense of what the interests of the audience are, but that is only part of it. Do you want your talk to be accessible to only faculty in your sub-area? (Hint : NO). Graduate students? If so, how much background should they have? Most of your talk should be accessible to a certain group — identify that group and target the bulk of the material to them. If you are giving a job talk it’s a different group from a conference or a specialized workshop.
- What do you want them to know? You have to be able to summarize what you want to say in one sentence. It’s not going to encapsulate everything, but it should be what you want your target audience to learn from your talk. Write this down and think about it. It’s not easy to summarize your work in a sound bite.
- Outlining the talk. Make an outline of the talk that contains one sentence per slide. Each slide should have a single main point that you can write down before adding any content to the slide. Read the sentences in order. It should be a story — does the story flow well? Does it make sense? Do you really need a table of contents slide for a 20 minute talk?
- Filling it in. For each sentence, think about how best to explain that point. Pictures are great, loads of equations are not. How can you, in a minute or two, make that point while talking, and what do you need visually to help emphasize that point? This is like storyboarding for a film.
- Balancing the content. Now that you have a plan for each slide, check to see that it’s balanced. Too many slides with text will fatigue people. Too many slides with just pictures may lead to confusion.
- Fill it in. Fill in the text and make the figures. This will take time, but since you have the sentence on each slide and the plan you should be able to think clearly through what you need to put down on each slide.
- Practice. Practice giving the talk once, out loud (not just in your head). You will find mistakes on the slides. Fix those mistakes. Practice again to find more mistakes. You might discover that the story doesn’t flow as well as you thought so you have to go back and retweak things. But always keep in mind the story.
- Presentation = Invitation. People say a talk is an invitation to read your paper, but that is not really true, I think. Chances are that more than half the audience will not read your paper anyway, but you still need to teach them something. Of the remaining half, most may skim your paper in the proceedings; you have to make that process easier for them. For the hardcore few who will really spend time reading your paper (because they are reviewing it), you want them to be excited by that prospect.
- Planning for contingencies. People get derailed about things like having backup slides with all the details of the proofs. Making backup slides, which are seen 1% of the time, takes away time from making the main presentation, which is seen 100% of the time. Focus on making the main presentation good.
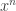 and
and  and you want to know if they are from the same distribution. He looked at the weak convergence of the asymptotically optimal test to get bounds on the false alarm probability.
and you want to know if they are from the same distribution. He looked at the weak convergence of the asymptotically optimal test to get bounds on the false alarm probability.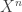 and
and  drawn i.i.d. from either
drawn i.i.d. from either  or
or 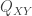 and they separately compress their observations into messages
and they separately compress their observations into messages 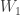 and
and  . What’s the best exponent?
. What’s the best exponent? queues and then pick one to join. Their strategies may differ, so there is a game between the customers and this can affect the distribution of queue sizes. As a flavor of the weird stuff that can happen, suppose all customers but one only sample one queue and join that queue. Then the remaining customer will experience less delay if they sample two and join the shorter one. However, if all but one sample two and join the shorter one, then it’s better for her to sample just one. At least, that’s how I understood it. I’m not really a queueing guy.
queues and then pick one to join. Their strategies may differ, so there is a game between the customers and this can affect the distribution of queue sizes. As a flavor of the weird stuff that can happen, suppose all customers but one only sample one queue and join that queue. Then the remaining customer will experience less delay if they sample two and join the shorter one. However, if all but one sample two and join the shorter one, then it’s better for her to sample just one. At least, that’s how I understood it. I’m not really a queueing guy. …”
…”