I didn’t do such a great job of taking notes this time, but I went to a number of talks today. Maybe Max will blog too.
The day kicked off with a plenary lecture by Frank Kschischang, who talked about the framework, pioneered by himself and Ralf Koetter, on viewing network coding as communicating subspaces from the encoder to the decoder. The corresponding codes are constructed over subspaces (elements of the Grassman manifold of a vector space over a finite field) and you can start building a coding theory for network coding based on that. It was a nice and clear way to start the day.
High-Rate Superposition Codes with Iteratively Optimal Estimates
Andrew Barron, Sanghee Cho
Andrew Barron talked about a new decoding algorithm for a channel coding scheme he and Anthony Joseph proposed two years ago. The information bits are mapped into a sparse coefficient vector 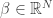


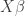
Minimization of Entropy Functionals Revisited
Imre Csiszár, Frantisek Matúš
This talk was on the minimization of certain functionals of the form 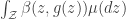
![\beta : \mathcal{Z} \times \mathbb{R} \to (-\infty,\infty]](https://s0.wp.com/latex.php?latex=%5Cbeta+%3A+%5Cmathcal%7BZ%7D+%5Ctimes+%5Cmathbb%7BR%7D+%5Cto+%28-%5Cinfty%2C%5Cinfty%5D&bg=ffffff&fg=333333&s=0&c=20201002)

The sufficiency principle for decentralized data reduction
Ge Xu, Biao Chen
This talk (by Ge Xu) was on the notion of sufficient statistics in networked inference problems. Under certain conditions, local sufficiency conditions can be translated into global sufficiency conditions. I wasn’t familiar enough with the related work in this area, but the structural problems of sufficiency look interesting and possibly of relevance to machine learning in distributed settings.
Finding the Capacity of a Quantized Binary-Input DMC
Brian Kurkoski, Hideki Yagi
Brian talked about the problem of taking a binary-input channel with 

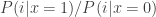
The day ended with a lovely tribute to Tom Cover featuring reminiscences by his colleagues and students. It was really inspiring, much like the 2008 Coverfest at Stanford. As my friend Galen put it, “I’m glad I went — I came out inspired to do better research.” Bob Gallager issued a challenge bring a little more of Cover’s attitude to our own work, so we could make ourselves into a “distributed Tom.” It would be wonderful, he said, and I agree.
