Since I am getting increasingly delayed by post-ISIT and pre-SPCOM business, I am going to have to keep the rest of blogging about ISIT a little short. This post will mention some talks, and I’ll keep the other stuff for a (final) post.
Efficient Tracking of Large Classes of Experts
András György, Tamas Linder, Gabor Lugosi
This paper was on expanding the reference class against one is competing in a “prediction with experts” problem. Instead of doing well against the best expert chosen in hindsight, you compete against the best meta-expert which can switch between the existing experts. This leads to a transition diagram that is kind of complicated, but they propose a unifying approach which traces along branches — the key is that every transition path can be well approximated, so the space of possibilities one is tracking will not blow up tremendously.
Information-Theoretically Optimal Compressed Sensing via Spatial Coupling and Approximate Message Passing
David Donoho, Adel Javanmard, Andrea Montanari
What a trendy title! Basically this problem looks at the compressed sensing problem when the sensing matrix is banded (this is what spatially coupled means), and solves it using Bayesian approximate message passing to do progressive decoding and elimination. The optimality is in the sense of matching with the Renyi dimension of the signal class for the data. I alas did not take notes for the next talk, which also seemed related: Hybrid Generalized Approximate Message Passing with Applications to Structured Sparsity (Sundeep Rangan, Alyson Fletcher, Vivek Goyal, Philip Schniter)
Quantized Stochastic Belief Propagation: Efficient Message-Passing for Continuous State Spaces
Nima Noorshams, Martin Wainwright
This problem was on BP when the state space is continuous — instead of passing the whole belief distribution, nodes pass along samples from the distribution and the receiving node does a kind of interpolation/estimate of the density. They show that this process converges on trees. This is related to a problem I’ve been thinking about for decentralized inference, but with a different approach.
Synchrony Amplification
Ueli Maurer, Björn Tackmann
This was a cool talk on a framework for thinking about synchrony in clocks — the model is pretty formal, and it’s something I never really think about but it seemed like a fun way to think about these problems. Basically they want to formalize how you can take a given clock (a sequence of ticks) and convert it into another clock. The goal is to not throw out too many ticks (which equals slowdown), while achieving synchrony.
Non-coherent Network Coding: An Arbitrarily Varying Channel Approach
Mahdi Jafari Siavoshani, Shenghao Yang, Raymond Yeung
Of course I have to go to a talk with AVC in the title. This looks at the same operator channel for network coding but then they assume the network matrix may be arbitrarily varying (with known rank). In this model they can define all the usual AVC concepts and they get similar sorts of results that you see for AVCs, like dichotomies between deterministic coding with average error and randomized coding.
Alternating Markov Chains for Distribution Estimation in the Presence of Errors
Farzad Farnoud, Narayana Prasad Santhanam, Olgica Milenkovic
This talk was on the repetition channel and getting the redundancy of alternating patterns. They show upper and lower bounds. The idea is you start out with a word like abccd and it goes through a repetition channel to get aaabbcccdddd for example, and then you look instead at abcd by merging repeated letters.
On Optimal Two Sample Homogeneity Tests for Finite Alphabets
Jayakrishnan Unnikrishnan
A two-sample test means you have two strings 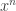

Hypothesis testing via a comparator
Yury Polyanskiy
This was on a model where two nodes get to observe 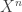


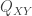
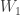

The Supermarket Game
Jiaming Xu, Bruce Hajek
This was on queuing. Customers come in and sample the loads of 
