CALL FOR PAPERS
IEEE Signal Processing Society
IEEE SIGNAL PROCESSING MAGAZINE
Special Issue on Signal Processing for Cyber-security and Privacy
Aims and Scope:
Information technology and electronic communications have been rapidly applied to many spheres of human activity, including commerce, medicine and social networking. This has led to the creation of massive electronic repositories for distributed information storage and processing, which enables access by a large number of authorized users. The need for timely access to electronic data makes it imperative to guarantee the security and privacy of this data. Traditionally, electronic data security has been ensured via cryptographic techniques, but these distributed data systems require security and privacy mechanisms at all levels of the system. Thus, providing precise guarantees on the security and privacy of electronic information requires leveraging a range of information processing techniques beyond traditional cryptography to ensure secure distributed storage and access mechanisms. The problems of information exchange, interaction, and access lend themselves to fundamental information processing abstractions and theoretical analysis. The tools of rate-distortion theory, distributed compression algorithms, distributed storage codes, machine learning for feature identification and suppression, and compressive sensing and sampling theory are fundamental and can be applied to precisely formulate and quantify the tradeoff between utility and privacy in a variety of domains. Thus, while rate-distortion theory and information-theoretic security can provide fundamental bounds on privacy and security leakage of distributed data systems, the information and signal processing techniques of compressive sensing, machine learning, and graphical models are the key ingredients necessary to achieve these performance limits in a variety of applications involving streaming data (smart grid, intelligent data collection), distributed data storage (cloud), and interactive data applications across a number of platforms. This special issue seeks to provide a venue for ongoing research in information and signal processing for security and privacy applications across a wide variety of domains, including communication media (e.g. ranging from wireless networks at the edge to optical backbones at the core of the Internet), to computer systems (e.g. ranging from traditional computer architectures to distributed systems, including cloud computing).
Topics of Interest include (but are not limited to):
- Signal processing for information-theoretic security
- Data mining and analysis for anomaly and intrusion detection
- Forensic analysis: device identification, recovery of lost/corrupted information
- Information processing in the encrypted domain
- Security in distributed storage systems
- Codes for security in distributed storage and cloud computing
- Location privacy and obfuscation of mobile device positioning
- Physical layer security methods: confidentiality and authentication
- Secure identity management
- Formalized models for adversaries and threats
- Techniques to achieve covert or stealthy communication
- Stochastic models for large data repositories and for streaming data in cyber-physical systems
Submission Process:
Articles submitted to this special issue must contain significant relevance to signal processing and its application to security and privacy. All submissions will be peer reviewed according to the IEEE and Signal Processing Society guidelines for both publications.Submitted articles should not have been published or under review elsewhere. Manuscripts should be submitted online using the Manuscript Central interface. Submissions to this special issue of the IEEE SIGNAL PROCESSING MAGAZINE should have significant tutorial value. Prospective authors should consult the Magazine site for guidelines and information on paper submission.
Important Dates: Expected publication date for this special issue is September 2013.
Guest Editors:
Lalitha Sankar, Lead GE, Arizona State University, USA, lalithasankar@asu.edu
Vincent H. Poor, Princeton University, USA, poor@princeton.edu
Mérouane Debbah, Supelec, Gif-sur-Yvette, France, merouane.debbah@supelec.fr
Kannan Ramchandran, University of California Berkeley, USA, kannanr@eecs.berkeley.edu
Wade Trappe, Rutgers University, USA, trappe@winlab.rutgers.edu
 and
and 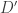 , we want to analyze the behavior of the random variable
, we want to analyze the behavior of the random variable  for measurable sets
for measurable sets  .
. 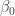 , then using Bayesian inference the posterior should concentrate around
, then using Bayesian inference the posterior should concentrate around  differential privacy on the utility functions of the users.
differential privacy on the utility functions of the users.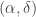 -differential privacy, but what this paper shows is that for the stricter
-differential privacy, but what this paper shows is that for the stricter  -differential privacy definition, statistical estimation is governed by the gross error sensitivity (GES) of the estimator.
-differential privacy definition, statistical estimation is governed by the gross error sensitivity (GES) of the estimator. , the feature
, the feature 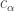 to compute and there is a total budget for the computation. The main approach is to minimize a linear combination of the loss and the cost iteratively, where each iteration consists of building a regression tree.
to compute and there is a total budget for the computation. The main approach is to minimize a linear combination of the loss and the cost iteratively, where each iteration consists of building a regression tree. nodes in a network has a change point
nodes in a network has a change point 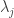 . Data is observed on vertices and edges and nodes have to pass messages on the graph. There’s a prior distribution on the change point times and after observing the data the nodes can use message passing to do some belief propagation to estimate the posterior distribution and define a stopping time. This turns out to be asymptotically optimal, in that the expected delay in detecting the change point is achieved.
. Data is observed on vertices and edges and nodes have to pass messages on the graph. There’s a prior distribution on the change point times and after observing the data the nodes can use message passing to do some belief propagation to estimate the posterior distribution and define a stopping time. This turns out to be asymptotically optimal, in that the expected delay in detecting the change point is achieved.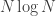 , where $N$ is the number of items (e.g. movies). It’s worse if the users are sparse — the scaling is with
, where $N$ is the number of items (e.g. movies). It’s worse if the users are sparse — the scaling is with  , which is also achievable in some settings. The analysis approach using Fano is analogous to the “information leakage” connections with differential privacy.
, which is also achievable in some settings. The analysis approach using Fano is analogous to the “information leakage” connections with differential privacy.