I usually tag things from ArXiV that I want to skim later, so I figured I would post the ones I found interesting in the last month or so. Some of them may deserve their own post later. Jet lag is not letting me take the nap I need right now so I figured I’d post it before conking out.
Convergence Rates for Differentially Private Statistical Estimation
K. Chaudhuri and D. Hsu
ArXiV 1206.6395
This paper is about estimation under privacy constraints. In differential privacy there are a fair number of constraints with regards to the data being well behaved — typical assumptions include boundedness, for example. One way around this is to move to a relaxed notion of privacy known as 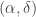

The Greedy Miser: Learning under Test-time Budgets
Z. Xu, K. Weinberger, and O. Chapelle
ArXiV 1206.6451
This paper is about incorporating the cost of extracting features in classification or regression. For a data point 
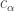
Sequential detection of multiple change points in networks: a graphical model approach
A.A. Amini and X. Nguyen
ArXiV 1207.1687
This looks at the change point detection problem in the network setting, where each of 
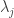
The Price of Privacy in Untrusted Recommendation Engines
S. Bannerjee, N. Hegde, and L. Massoulié
ArXiV 1207.3269
This studies the effect on recommendations engines of individuals masking their data due to privacy concerns. The technical issues are the the dimension is high and each user only has a small amount of data to control (e.g. the movies that they rented or have seen). The question is one of sample complexity — how many users do we need to cluster successfully. If users are not so sparse, they can achieve the Fano lower bound (order-wise) using a sketch and spectral techniques, but the dependence is like 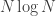

Surrogate Losses in Passive and Active Learning
S. Hanneke and L. Yang
ArXiV 1207.3772
This paper looks at how to use surrogate losses (which are computationally tractable) in active learning problems. “We take as our starting point that we have already committed to use a given surrogate loss, and we restrict our attention to just those scenarios in which this heuristic actually does work. We are then interested in how best to make use of the surrogate loss toward the goal of producing a classifier with relatively small error rate.” The central insight in their algorithm is that by taking into account the fact that the “real loss” is (say) the 0-1 loss, then for the purposes of active learning, one only really needs to get the sign right and not the magnitude. So the process will minimize the real loss but not necessarily the surrogate.
