Varshneys’ got a brand new blog.
(to be sung to the James Brown tune of the similar name)
Varshneys’ got a brand new blog.
(to be sung to the James Brown tune of the similar name)
Well, if not decipher, at least claim that there is something to read. A recent paper claims that Pictish inscriptions are a form of written language:
Lo and behold, the Shannon entropy of Pictish inscriptions turned out to be what one would expect from a written language, and not from other symbolic representations such as heraldry.
The full paper has more details. From reading the popular account I thought it was just a simple hypothesis test using the empirical entropy as a test statistic and “heraldry” as the null hypothesis, but it is a little more complicated than that.
After identifying the set of symbols in Pictish inscriptions, the question is how related adjacent symbols are to each other. That is, can the symbols be read sequentially? What they do is renormalize Shannon’s 
where 

Another feature which the authors think is important is the number of digrams which are repeated in the text. If 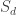
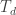
where the tradeoff factor 
They then propose a two-step decision process. First they compare 

In this paper “entropy” is being used here as some statistic with discriminatory value. It is not clear a priori that human writing systems should display empirical entropies with certain values, but since it works well on other known corpora, it seems like reasonable evidence. I think the authors are relatively careful about this, which is nice, since popular news might make one think that purported alien transmissions could easily fall to a similar analysis. Maybe that’s how Jeff Goldblum mnanaged to get his Mac to reprogram the alien ship in Independence Day…
Update: I forgot to link to a few related things. The statistics in this paper are a little more convincing than the work on the Indus script (see Cosma’s lengthy analysis. In particular, they do a little better job of justifying their statistic as discriminating in known corpora. Pictish would seem to be woefully undersampled, so it is important to justify the statistic as discriminatory for small data sets.
Via Lifehacker, I came across this short description of how credit card numbers are coded, and how the last digit is a parity check. It’s a cute example of “real world” error-detection that pretty much anyone could understand. Cute extra-credit problem: how many valid credit card numbers are there out there? (This reminds me of a USAMTS problem from ages past).
The 2010 ITA Workshop is over, and now that I have almost caught up on sleep, I can give a short report. I think this year was the largest workshop so far, with over 300 speakers.
One of the additions this year was a poster session to give those students who didn’t get a chance to speak at the “Graduation Day” talks on Wednesday an opportunity to present their research. The posters went up on Monday and many stayed up most of the week. I am usually dubious of poster sessions for more theoretical topics; from past experience I have had a hard time conveying anything useful in the poster and they are poorly attended. However, this poster session seemed to be a rousing success, and I hope they continue to do it in future years.
The theme this year was “networks,” broadly construed, and although I didn’t end up going to a lot of the “pure” networking sessions, the variety of topics was nice to see, from learning in networks to network models. Jon Kleinberg gave a great plenary lecture on cascading phenomena. I particularly enjoyed Mor Harchol-Balter’s tutorial on job scheduling in server farms. I learned to re-adjust my intuition for what good scheduling policies might be. The tutorials should be online sometime and I’ll post links when that happens.
The “Senseless Decompression” session organized by Rudi Urbanke and Ubli Mitra should also be online sometime. Apparently 20+ schools contributed short videos on the theme of 
Perhaps later I’ll touch on specific talks that I went to, but this time around I didn’t take too many notes, probably because I was a little exhausted from the organizing. I may post a more technical thing on the talk I gave about my recent work on privacy-preserving machine learning, but that will have to wait a bit in the queue. Mor’s tutorial suggests I should use Shortest Remaining Processing Time (SRPT) to make sure things don’t wait too long, and I have some low-hanging tasks that I can dispatch first.
I’ve been working hard with the organizing committee putting together the 2010 ITA Workshop, which promises to be a blast. With that and job applications I’m probably going to eschew blogging the workshop this year, but I’ll try to post some highlights. If nothing else, it will get me back to blogging again.
Ehsan Ardestanizadeh posed a little problem in Young-Han Kim‘s group meeting before break and Paolo Minero presented a cute solution which I thought might be of interest. It’s related to ideas my advisor, Michael Gastpar worked on in his thesis.
Suppose I have a Gaussian variable 

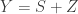


and the MSE is ![\mathbb{E}[ (S - \hat{S})^2 ] = 1/2](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+%28S+-+%5Chat%7BS%7D%29%5E2+%5D+%3D+1%2F2&bg=ffffff&fg=333333&s=0&c=20201002)




The answer is no, and comes via an “information theoretic” argument. Consider the vector version of the problem where you have 
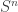

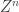
This is just the problem of joint source-channel coding of a Gaussian source over an AWGN channel with quadratic distortion and encoding function
and the capacity of the channel is 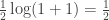

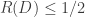
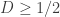

Now if there was a scheme for the single-letter case which got MSE less than 1/2, we could concatenate it to get a vector scheme with distortion less than 1/2. But since
Kamalika pointed me to this paper by Bin Yu in a Festschrift for Lucien Le Cam. People who read this blog who took information theory are undoubtedly familiar with Fano’s inequality, and those who are more on the CS theory side may have heard of Assouad (but not for this lemma). This paper describes the relationship between several lower bounds on hypothesis testing and parameter estimation.
Suppose we have a parametric family of distributions 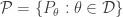
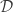
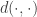
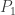
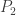
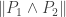
Let 
Le Cam’s Lemma. Let 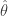

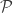
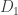
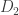

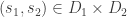
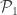


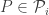
This lemma gives a lower bound on the error of parameter estimates in terms of the total variational distance between the distributions associated to different parameter sets. It’s a bit different than the bounds we usually think of like Stein’s Lemma, and also a bit different than bounds like the Cramer-Rao bound.
Le Cam’s lemma can be used to prove Assouad’s lemma, which is a statement about a more structured set of distributions indexed by the 


Assouad’s Lemma. Let 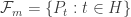
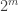



and that if
Then
The min comes about because it is the weakest over all neighbors (that is, over all j) of 
Yu then shows how to prove Fano’s inequality from Assouad’s inequality. In information theory we see Fano’s Lemma as a statement about random variables and then it gets used in converse arguments for coding theorems to bound the entropy of the message set. Note that a decoder is really trying to do a multi-way hypothesis test, so we can think about the result in terms of hypothesis testing instead. This version can also be found in the Wikipedia article on Fano’s inequality.
Fano’s Lemma. Let 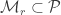


and
Then
Here 


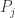

The rest of the paper is definitely worth reading, but to me it was nice to see that Fano’s inequality is interesting beyond coding theory, and is in fact just one of several kinds of lower bound for estimation error.
I was at the Allerton conference last week for a quick visit home — I presented a paper I wrote with Can Aysal and Alex Dimakis on analyzing broadcast-based consensus algorithms when channels vary over time. The basic intuition is that if you can get some long-range connections “enough of the time,” then you’ll get a noticeable speed up in reaching a consensus value, but with high connectivity the variance of the consensus value from the true average increases. It was a fun chance to try out some new figures that I made in OmniGraffle.
The plenary was given by Abbas El Gamal on a set of new lecture notes on network information theory that he has been developing with Young-Han Kim. He went through the organization of the material and tried to show how much of the treatment could be developed using robust typicality (see Orlitsky-Roche) and a few basic packing and covering lemmas. This in turn simplifies many of the proofs structurally and can give a unified view. Since I’ve gotten an inside peek at the notes, I can say they’re pretty good and clear, but definitely dense going at times. They are one way to answer the question of “well, what do we teach after Cover and Thomas.” They’re self-contained and compact .
What struck me is that these are really notes on network information theory and not on advanced information theory, which is the special topics class I took at Berkeley. It might be nice to have some of the “advanced but non-network” material in a little set of notes. Maybe the format of Körner’s Fourier Analysis book would work : it could cover things like strong converses, delay issues, universality, wringing lemmas, AVCs, and so on. Almost like a wiki of little technical details and so on that could serve as a reference, rather than a class. The market’s pretty small though…
I felt a bit zombified during much of the conference, so I didn’t take particularly detailed notes, but here were a few talks that I found interesting.
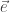 it can detect all signals whose support is the same as . There were many other extensions of this results as well, to other performance metrics, and also the Gaussian setting.
it can detect all signals whose support is the same as . There were many other extensions of this results as well, to other performance metrics, and also the Gaussian setting. with an iid process (say equiprobable coin flips)
with an iid process (say equiprobable coin flips)  . Using the information spectrum method, non-matching necessary and sufficient conditions can be found for when this can be done. These are in terms of sup-entropy rates and so on. Essentially though, it’s a theory built on the limits or support of the spectra of the two processes
. Using the information spectrum method, non-matching necessary and sufficient conditions can be found for when this can be done. These are in terms of sup-entropy rates and so on. Essentially though, it’s a theory built on the limits or support of the spectra of the two processes  and . If the entropy spectrum in dominates that of then you’re in gravy. This paper proposed a more refined notion of dominance which looks a bit like majorization of some sort. I think they showed that was sufficient, but maybe it’s also necessary too. Things got a bit rushed towards the end.
and . If the entropy spectrum in dominates that of then you’re in gravy. This paper proposed a more refined notion of dominance which looks a bit like majorization of some sort. I think they showed that was sufficient, but maybe it’s also necessary too. Things got a bit rushed towards the end. are the number of bits in each chunk). How do you size the chunks to maximize the volume? This can be solved with dynamic programming. There are still several open questions left, but the whole construction relies on using “optimal codes of finite blocklength” which also needs to be solved. Lav has some interesting ideas along these lines that he told me about when I was in Boston two weeks ago…
are the number of bits in each chunk). How do you size the chunks to maximize the volume? This can be solved with dynamic programming. There are still several open questions left, but the whole construction relies on using “optimal codes of finite blocklength” which also needs to be solved. Lav has some interesting ideas along these lines that he told me about when I was in Boston two weeks ago…  constraints. Achievability uses Han-Kobayashi in a block-Markov encoding with backward decoding, and the converse uses the El Gamal-Costa argument with some additional Markov properties. For the “bit-level” deterministic channel model, there is an interpretation of the feedback as filling a “hole” in the interference graph.
constraints. Achievability uses Han-Kobayashi in a block-Markov encoding with backward decoding, and the converse uses the El Gamal-Costa argument with some additional Markov properties. For the “bit-level” deterministic channel model, there is an interpretation of the feedback as filling a “hole” in the interference graph.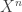 , Bob has
, Bob has  and they want to compute some functions
and they want to compute some functions  and
and  . The pairs
. The pairs 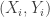 are iid and jointly distributed according to some distribution
are iid and jointly distributed according to some distribution  . As an example,
. As an example, 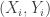 could be correlated bits and
could be correlated bits and 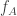 and
and 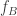 could be the AND function. In previous work the authors characterized the the rate region (allowing vanishing probability of error) for
could be the AND function. In previous work the authors characterized the the rate region (allowing vanishing probability of error) for  rounds of communication, and here they look at the case when there are infinitely many back-and-forth messages. The key insight is to characterize the sum-rate needed as a function of — that is, to look at the function
rounds of communication, and here they look at the case when there are infinitely many back-and-forth messages. The key insight is to characterize the sum-rate needed as a function of — that is, to look at the function 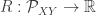 and look at that surface’s analytic properties. In particular, they show it’s the minimum element of a class
and look at that surface’s analytic properties. In particular, they show it’s the minimum element of a class  of functions which have some convexity properties. There is a preprint on ArXiV.
of functions which have some convexity properties. There is a preprint on ArXiV.From The Information Theory of Emotions of Musical Chords, posted on ArXiV today:
My basic hypothesis is as follows. While perceiving a separate musical chord, the value of a relative
objective function L that is directly related to the main proportion of pitches of its constituent
sounds is generated in the mind of the subject. The idea of an increasing value of the objective
function ( L>1 ) accompanied by positive utilitarian emotions corresponds to a major chord, while
the idea of a decreasing value of the objective function ( L<1 ) accompanied by negative utilitarian
emotions corresponds to a minor chord.
I naturally thought of The Mathematics of Love:
The Gelfand-Pinsker Channel: Strong Converse and Upper Bound for the Reliability Function
Himanshu Tyagi, Prakash Narayan
Strong Converse for Gel’fand-Pinsker Channel
Pierre Moulin
Both of these papers proved the strong converse for the Gel’fand-Pinsker channel, e.g. the discrete memoryless channel with iid state sequence 
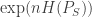
Combinatorial Data Reduction Algorithm and Its Applications to Biometric Verification
Vladimir B. Balakirsky, Anahit R. Ghazaryan, A. J. Han Vinck
The goal of this paper was to compute short fingerprints 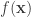
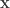
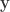
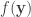


Two-Level Fingerprinting Codes
N. Prasanth Anthapadmanabhan, Alexander Barg
This looks at a variant of the fingerprinting problem, in which you a content creator makes several fingerprinted versions of an object (e.g. a piece of software) and then a group of pirates can take their versions and try to create a new object with a valid fingerprint. The marking assumption mean that the pirates can only alter the positions in their copies which are different. The goal is to build a code such that a verifier looking at an object produced by



![d(\hat{S}^n, S^n) = \frac{1}{n} \sum_{i=1}^{n} \mathbb{E}[ (S_i - \hat{S}_i)^2 ]](https://s0.wp.com/latex.php?latex=d%28%5Chat%7BS%7D%5En%2C+S%5En%29+%3D+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+%5Cmathbb%7BE%7D%5B+%28S_i+-+%5Chat%7BS%7D_i%29%5E2+%5D&bg=ffffff&fg=333333&s=0&c=20201002)
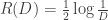

![\sup_{P \in \mathcal{P}} \mathbb{E}_P[ d(\hat{\theta}, \theta(P)) ] \ge \delta \cdot \sup_{P_i \in \mathop{\rm co}(\mathcal{P}_i)} \| P_1 \wedge P_2 \|](https://s0.wp.com/latex.php?latex=%5Csup_%7BP+%5Cin+%5Cmathcal%7BP%7D%7D+%5Cmathbb%7BE%7D_P%5B+d%28%5Chat%7B%5Ctheta%7D%2C+%5Ctheta%28P%29%29+%5D+%5Cge+%5Cdelta+%5Ccdot+%5Csup_%7BP_i+%5Cin+%5Cmathop%7B%5Crm+co%7D%28%5Cmathcal%7BP%7D_i%29%7D+%5C%7C+P_1+%5Cwedge+P_2+%5C%7C&bg=ffffff&fg=333333&s=0&c=20201002)



![\max_{P_t \in \mathcal{F}_m} \mathbb{E}_{t}[ d(\hat{\theta},\theta(P_t))] \ge m \cdot \frac{\alpha_m}{2} \min\{ \|P_t \wedge P_{t'} \| : t \sim_j t', j \le m\}](https://s0.wp.com/latex.php?latex=%5Cmax_%7BP_t+%5Cin+%5Cmathcal%7BF%7D_m%7D+%5Cmathbb%7BE%7D_%7Bt%7D%5B+d%28%5Chat%7B%5Ctheta%7D%2C%5Ctheta%28P_t%29%29%5D+%5Cge+m+%5Ccdot+%5Cfrac%7B%5Calpha_m%7D%7B2%7D+%5Cmin%5C%7B+%5C%7CP_t+%5Cwedge+P_%7Bt%27%7D+%5C%7C+%3A+t+%5Csim_j+t%27%2C+j+%5Cle+m%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)
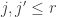
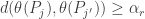

![\max_j \mathbb{E}_j[ d(\hat{\theta},\theta(P_j)) ] \ge \frac{\alpha_r}{2}\left( 1 - \frac{\beta_r + \log 2}{\log r} \right)](https://s0.wp.com/latex.php?latex=%5Cmax_j+%5Cmathbb%7BE%7D_j%5B+d%28%5Chat%7B%5Ctheta%7D%2C%5Ctheta%28P_j%29%29+%5D+%5Cge+%5Cfrac%7B%5Calpha_r%7D%7B2%7D%5Cleft%28+1+-+%5Cfrac%7B%5Cbeta_r+%2B+%5Clog+2%7D%7B%5Clog+r%7D+%5Cright%29&bg=ffffff&fg=333333&s=0&c=20201002)
