Ehsan Ardestanizadeh posed a little problem in Young-Han Kim‘s group meeting before break and Paolo Minero presented a cute solution which I thought might be of interest. It’s related to ideas my advisor, Michael Gastpar worked on in his thesis.
Suppose I have a Gaussian variable  that is
that is  , so zero-mean and unit variance. If I observe
, so zero-mean and unit variance. If I observe 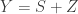 where
where  is also and independent of , the minimum mean-square error (MMSE) estimate of given
is also and independent of , the minimum mean-square error (MMSE) estimate of given  is just
is just

and the MSE is ![\mathbb{E}[ (S - \hat{S})^2 ] = 1/2](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+%28S+-+%5Chat%7BS%7D%29%5E2+%5D+%3D+1%2F2&bg=ffffff&fg=333333&s=0&c=20201002) . The question is this: can we somehow get an MSE of less than 1/2 by “encoding” ? Suppose now we can take any function
. The question is this: can we somehow get an MSE of less than 1/2 by “encoding” ? Suppose now we can take any function  and let
and let  , and
, and  but with the restriction that
but with the restriction that  . That is, the encoding cannot take any more power.
. That is, the encoding cannot take any more power.
The answer is no, and comes via an “information theoretic” argument. Consider the vector version of the problem where you have  iid unit variance Gaussians
iid unit variance Gaussians 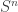 and you want to estimate from
and you want to estimate from  where
where 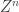 is iid unit variance Gaussian as well. The goal is to minimize the average per-letter distortion:
is iid unit variance Gaussian as well. The goal is to minimize the average per-letter distortion:
![d(\hat{S}^n, S^n) = \frac{1}{n} \sum_{i=1}^{n} \mathbb{E}[ (S_i - \hat{S}_i)^2 ]](https://s0.wp.com/latex.php?latex=d%28%5Chat%7BS%7D%5En%2C+S%5En%29+%3D+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+%5Cmathbb%7BE%7D%5B+%28S_i+-+%5Chat%7BS%7D_i%29%5E2+%5D&bg=ffffff&fg=333333&s=0&c=20201002)
This is just the problem of joint source-channel coding of a Gaussian source over an AWGN channel with quadratic distortion and encoding function must satisfy a unit power constraint. For this problem the rate distortion function is
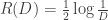
and the capacity of the channel is 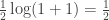 . Since separate source coding (compression) followed by channel coding (error control) is optimal, in order to get distortion
. Since separate source coding (compression) followed by channel coding (error control) is optimal, in order to get distortion  the rate
the rate 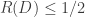 so
so 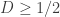 . Furthermore, this is achievable with no coding at all by just setting
. Furthermore, this is achievable with no coding at all by just setting  .
.
Now if there was a scheme for the single-letter case which got MSE less than 1/2, we could concatenate it to get a vector scheme with distortion less than 1/2. But since in the optimal code, we get a contradiction. Thus encoding does not help in the single-letter case either. If isn’t Gaussian the whole story changes though.

Yes, it’s interesting that encoding can help when S,Z are not Gaussian.
If S,Z are in {+1,-1} (equally likely), f(S)=S/2 gives MMSE error 0 (as opposed to 1/2 for Y=S+Z)
Well both non-Gaussian makes it easier, but for your binary source and Gaussian noise can encoding help in the single- shot case?
Another (personally biased) approach is consider single shot communication as a special case of casual coding. For example, Walrand and Variya considered the problem of optimally coding a first order Markov source over a DMC with noiseless feedback in Optimal Causal Coding-Decoding Problem, IT 1982. They show that if the channel is symmetric (in a particular sense that is different from the usual definition of symmetric channels in info theory), then no coding is optimal.
The single shot problem is a special case of Walrand and Varaiya in which the coding horizon is 1. However, I am not aware of extensions of Walrand and Varaiya’s results to continuous channels. Nonetheless, one would suspect that if an AWGN channel is symmetric according to any sensible definition of symmetric channel. Then, a Walrand and Varaiya like result would mean that no coding is optimal for transmitting any unit variance source over Gaussian channel with unit power constraint for causal communication.
There’s also an aspect of “Gaussian noise is the worst noise” which perhaps combined with those symmetry ideas would give a result for maybe a class of sources beyond Gaussian?