This post was written using Luca’s LATEX2WP tool.
The topic of this (late) post is “wringing” techniques, which are a way of converting a statement like “ and
and  are close” into a statement about per-letter probabilities. Such a statement looks like “we can find some indices and values at those indices such that if we condition on those values, the marginals of
are close” into a statement about per-letter probabilities. Such a statement looks like “we can find some indices and values at those indices such that if we condition on those values, the marginals of  and
and  are close.” I’m going to skip straight to the simpler of the two “Wringing Lemmas” in this paper and sketch its proof. Then I’ll go back and state the first one (without proof). There are some small typos in the original which I will try to correct here.
are close.” I’m going to skip straight to the simpler of the two “Wringing Lemmas” in this paper and sketch its proof. Then I’ll go back and state the first one (without proof). There are some small typos in the original which I will try to correct here.
Lemma 1 Let and be probability distributions on 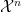 such that for a positive constant
such that for a positive constant  ,
,

then for any 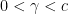 and
and  there exist
there exist  , where
, where

such that for some  ,
,

for all  and all
and all  . Furthermore,
. Furthermore,
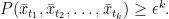
The proof works pretty mechanically. Fix a  and
and  . Suppose that the conclusion doesn’t hold for
. Suppose that the conclusion doesn’t hold for  . Then there is a
. Then there is a 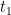 and
and  such that
such that

where the first bound is from the assumption and the second because the conclusion doesn’t hold. Then we have  . Now dividing (1) by
. Now dividing (1) by  and using the lower bound on we get for all
and using the lower bound on we get for all  ,
,

Now, either the conclusion is true or we use (2) in place of (1) to find a 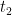 and a
and a  such that
such that

We can keep going in this way until we get  in the denominator. This yields the condition on
in the denominator. This yields the condition on  .
.
Rather than describe how to apply this to our coding problem, I want to contrast this rather simple statement to the other wringing lemma in the paper, which is a generalization of the lemma developed by Dueck. This one is more “information theoretic” in the sense that it says if the block mutual information is small, then we can find positions to condition on such that the per-letter mutual informations are small too.
Lemma 2 Let 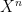 and
and  be
be  -tuples of random variables from discrete finite alphabets
-tuples of random variables from discrete finite alphabets 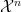 and
and 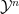 and assume that
and assume that

Then for any 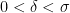 and there exist , where
and there exist , where
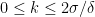
such that for some  ,
,
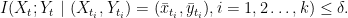
for all . Furthermore,

This lemma proved in basically the same way as the previous lemma, but it’s a bit messier. Dueck’s original version was the similar but gave a bound on the conditional mutual information, rather than this bound where we condition on particular values. This way of taking a small mutual information and getting small per-letter mutual informations can be useful outside of this particular problem, I imagine.
Next time I’ll show how to apply the first lemma to our codebooks in the converse for the MAC.

 and
and  on
on  for individual variables
for individual variables  such that the single letter marginals of
such that the single letter marginals of 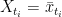 .
. and suppose
and suppose  and let
and let  be a code for the MAC with maximal error probability
be a code for the MAC with maximal error probability  . Then for an
. Then for an 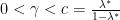 and
and  there exist
there exist  for
for  and fixed values
and fixed values  such that the subcode formed by
such that the subcode formed by 

 and
and  and all
and all  ,
, 
 and
and 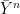 are distributed according to the
are distributed according to the  and (a) not lose too much rate for each user and (b) the joint distribution of the subcode is almost a product distribution. Remember, the Fano distribution is just the uniform distribution on the codewords of the subcode induced by
and (a) not lose too much rate for each user and (b) the joint distribution of the subcode is almost a product distribution. Remember, the Fano distribution is just the uniform distribution on the codewords of the subcode induced by  .
.
 code for the MAC and then we
code for the MAC and then we 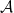 defined before. This code satisfies rate bounds which look almost like what we want — they have sums of mutual informations like
defined before. This code satisfies rate bounds which look almost like what we want — they have sums of mutual informations like  except that
except that  are distributed uniformly on
are distributed uniformly on  where the inputs are almost independent, so then we can use the continuity of mutual information and entropy to get upper bounds with sums of
where the inputs are almost independent, so then we can use the continuity of mutual information and entropy to get upper bounds with sums of  where the inputs are finally independent.
where the inputs are finally independent. B-processes
B-processes 