I figured I would blog about this week’s workshop at Banff in a more timely fashion. Due to the scheduling of flights out of Calgary, I will have to miss the last day of talks. The topics of people’s presentations varied rather widely, and many were not about the sort of Good-Turing estimator setup. Sometimes it was a bit hard to see how to see how the problems or approaches were related (not that they had to be directly), but given that the crowd had widely varying backgrounds, presenters had a hard time because the audience had to check in a new set of notation or approach for every talk. The advantage is that there were lots of questions — the disadvantage is that people insisted on “finishing” their presentations. By mid-week my brain was over-full, and a Wednesday afternoon hike up Sulphur Mountain was the perfect solution.

The view from Sulpur Mountain
My notes from the workshop are not chronological — due to travel schedules (including conflicts with FOCS), the order of topics did not necessarily take a particular “flow” from topic A to topic B, although talks with a common methodological approach were grouped together. The last day had talks on sparsity and goodness-of-fit testing (by Sanghavi, Saligrama, and Huang), but unfortunately I could not make those.
Distribution estimation
The presentations on Tuesday were on what might be called “foundational” aspects of the problem : given a sequences of random samples 
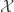


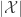


Prasad Santhanam talked about a prediction and compression view of the problem, which was the original motivation for the Good-Turing estimator : given the sequence of samples, how should we update our belief about what the next sample will be? En-Hui Yang talked more specifically about compression, and proposed an approach to learning structure in the source via context-free grammars. Krisha Viswanathan talked a bit more about the so-called pattern maximum likelihood estimator and what we know about it — for example, we think it’s unique but it may not be. It’s related to maximizing the permanent of a matrix parameterized by the probability distribution, which is known to be #P-complete in general, but not necessarily for this specific permanent. His talked segued nicely into Pascal Vontobel‘s talk about approximating these permanents using the “Bethe approximation.” I really ought to learn more physics.
A very different perspective was given that morning by Peter Orbanz, Sonia Petrone, and Jaeyong Lee, who discussed Bayesian nonparametric approaches to the the modeling problem. Peter and Sonia’s talks were on fundamentals — in particular, deriving the Poisson-Dirichlet and Pitman-Yor priors, the mathematical difficulties in doing Bayesian updating, and how these priors are related to different predictive distributions. Jaeyong Lee talked about a species sampling model in which species are drawn from a distribution with a discrete and continuous component. He showed that such models are only consistent in certain special cases. Species sampling was one of the original motivations for these problems (see my previous post).
Entropy estimation and property testing
Several of the speakers talked about estimation of properties of distributions, such as the entropy or support. Mesrob Ohanessian talked about consistent estimation in the “rare events regime” where we have a sequence of distributions 





Paul and Greg Valiant presented their recent work on estimating symmetric properties of distributions. If you have a bound 

The different perspective, known as property testing, was given by Tugkan Batu and Ronitt Rubenfeld. There you have an unknown distribution 

Markov stuff
There were two talks on what might be best described as stochastic processes. Serdar Yüksel talked about sequences of estimators converging from the perspective of control, and particular looked at estimators which looked like quantizers. It was a little over my head. Ramon Van Handel gave a talk on model selection for hidden Markov models in which the hidden states have an unknown number of possible values and you want to estimate them. This is quite hard and there are various penalized ML estimators (BIC penalty or MDL), but he claimed there are no correct proofs of the consistency of these estimators for large alphabets. This problem seems too hard, so he described two other problems in which the some of the same fundamental issues appear : the observations are not independent, the geometry of the likelihoods is weird, and there is no upper bound on the number of states.
Learning
There were a few talks on learning algorithms. Dean Foster talked about modeling text using HMMs but also trying to cluster words semantically using multi-view learning and canonical correlation analysis (CCA). Alexandr Andoni talked about a budgeted learning game which he called precision sampling. In that model, you want to estimate the sum of some numbers 
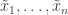




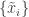
Networks and graphs
Finally, several of the speakers talked about problems on graphs and networks whose techniques or ideas could possibly prove useful for estimation. Sidharth Jaggi talked about network tomography. Al Hero talked about inferring correlation in graphical models via better thresholding. Michael Mahoney talked about how certain approximate optimization algorithms like PageRank can really be viewed as regularized optimizations with different regularization functions.
Finally, in one of my favorite presentations, Balazs Szegedy talked about inferring structures in very large graphs from sampling, using the Szemeredi Regularity Lemma and other tools. He covered arithmetic progressions and graphons and all sorts of cool stuff. Things got a bit technical for a while, and when he saw that some people were getting lost he encouraged us to “enjoy the music of it.” I’m totally going to use that line.
