ISIT 2012 early registration ends today — you can register here before the fees go up. I think I only got one email about this, which is sort of disappointing. So register today!
Tag Archives: conferences
ICITS Workshop Deadline Extension
(Via Adam Smith) The deadline for submitting workshop papers to the 6th International Conference on Information Theoretic Security (ICITS) has been extended from today to Monday, April 23 (at 3pm Eastern) due to holidays. It’s in Montreal in August, so if you have some recent results that you would like to present in a workshop setting, please send them in. “Papers which broaden the applicability of information-theoretic techniques (say, to areas such as data privacy or anonymity) would also be very welcome.”
ICITS will have two tracks this year : a more CS-style conference with published proceedings, and a workshop (think ITA) track without proceedings where you can present older stuff.
CISS 2012 : day 1
I’m at CISS right now on the magnolia-filled Princeton campus. The last time I came here was in 2008, when I was trying to graduate and was horribly ill, so this year was already a marked improvement. CISS bears some similarities to Allerton — there are several invited sessions in which the talks are a little longer than the submitted sessions. However, the session organizers get to schedule the entire morning or afternoon (3 hours) as they see fit, so hopping between sessions is not usually possible. I actually find this more relaxing — I know where I’m going to be for the afternoon, so I just settle down there instead of watching the clock so I don’t miss talk X in the other session.
Because there are these invited slots, I’ve begun to realize that I’ve seen some of the material before in other venues such as ITA. This is actually a good thing — in general, I’ve begun to realized that I have to see things 3 times for me to wrap my brain around them.
In the morning I went to Wojciech Szpankowski‘s session on the Science of Information, a sort of showcase for the new multi-university NSF Center. Peter Shor gave an overview of quantum information theory, ending with comments on the additivity conjecture. William Bialek discussed how improvements in array sensors for multi-neuron recording and other measurement technologies are allowing experimental verification of some theoretical/statistical approaches to neuroscience and communication in biological systems. In particular, he discussed an interesting example of how segmentation appears in the embryonic development of fruit flies and how they can track the propagation of chemical markers during development.
David Tse gave a slightly longer version of his ITA talk (with on DNA sequencing with more of the proof details. It’s a cute version of the genome assembly problem but I am not entirely sure what it tells us about the host of other questions biologists have about this data. I’m trying to wrestle with some short-read sequencing data to understand it (and learning some Bioconductor in the process), and the real data is pretty darn messy.
Madhu Sudan talked about his work with Brendan Juba (and now Oded Goldreich) on Semantic Communication — it’s mostly trying to come up with definitions of what it means to communicate meaning using computer science, and somehow feels like some of these early papers in Information and Control which tried to mathematize linguistics or other fields. This is the magical 3rd time I’ve seen this material, so maybe it’s starting to make sense to me.
Andrea Goldsmith gave a whirlwind tour of the work in backing away from asymptotic studies in information theory, and how insights we get from asymptotic analyses often don’t translate into the finite parameter regime. This is of a piece with her stand a few years ago on cross-layer design. High SNR assumptions in MIMO and relaying imply that certain tradeoffs (such diversity-multiplexing) or certain protocols (such as amplify-and forward) are fundamental but at moderate SNR the optimal strategies are different or unknown. Infinite blocklengths are the bread and butter of information theory but now there are more results on what we can do with finite blocklength. She ended with some comments on infinite processing power and trying to consider transmit and processing power jointly, which caused some debate in the audience.
Alas, I missed Tsachy Weissmann‘s talk, but at least I saw it at ITA? Perhaps I will get to see it two more times in the future!
In the afternoon I went to the large alphabets session which was organized by Aaron Wagner. Unfortunately, Aaron couldn’t make it so I ended up chairing the session. Venkat Chandrasekaran didn’t really talk about large alphabets, but instead about estimating high dimensional covariance matrices when you have symmetry assumptions on the matrix. These are represented by the invariance of the true covariance under actions of a subgroup of the symmetric group — taking these into account can greatly improve sample complexity bounds. Mesrob Ohanessian talked about his canonical estimation framework for large alphabet problems and summarized a lot of other work before (too briefly!) mentioning his own work on the consistency of estimators under some assumptions on the generating distribution.
Prasad Santhanam talked about the insurance problem that he worked on with Venkat Anantharam, and I finally understood it a bit better. Suppose you are observing i.i.d. samples 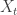


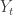

To round out the session, Wojciech Szpankowski gave a talk on analytic approaches to bounding minimax redundancy under different scaling assumptions on the alphabet and sample sizes. There was a fair bit of generatingfunctionology and Lambert W-functions. The end part of the talk was on scaling when you know part of the distribution exactly (perhaps through offline simulation or training) but then there is part which is unknown. The last talk was by Greg Valiant, who talked about his papers with Paul Valiant on estimating properties of distributions on 

I am not sure how much blogging I will do about the rest of the conference, but probably another post or two. Despite the drizzle, the spring is rather beautiful here — la joie du printemps.
ICITS Deadline Extension
Due to conflicts with other deadlines and conferences, the submission
deadline for the “conference” track of ICITS 2012 — the International
Conference on Information-Theoretic Security — has been moved back
ten days to Thursday, March 22, 2012.
The “conference” deadline is now Thursday, March 22 (3pm EDT / 19:00 GMT).
The “workshop” deadline is Monday, April 9.
ICITS will have two tracks this year, one which will act as a regular
computer science-style conference (published proceedings, original
work only) and the other which will behave more like a workshop,
without proceedings, where presentations on previously published work
or work in progress are welcome.
For more information, see the conference website.
Bellairs Workshop 2012

The beach at Bellairs
I am spending the week at the Bellairs Research Institute in Holetown, Barbados. McGill owns this facility and faculty organize informal workshops throughout the year on various topics. There are two going on right now — one on control theory approaches in computer animation, and out workshop on signal processing in networks. The McGill side is Mark Coates and Mike Rabbat and a number of their students, both masters and PhD. Anna Scaglione and Angelia Nedich arrived recently.
The format of the workshop has been a mix of tutorials and student presentations and plenty of time for discussion and some problem formation. And of course, for the beach, which is just behind the research facility. Holetown is on the west coast of Barbados, and the Caribbean is warm and inviting. I’m having a great time, even though I am falling behind on my other projects and email and whatnot.
People from Barbados call themselves Bajans (/ˈbeɪdʒənz/), so one should be careful not to discuss p-values or t-tests around them.
ITA Workshop 2012 : Talks
The ITA Workshop finished up today, and I know I promised some blogging, but my willpower to take notes kind of deteriorated during the week. For today I’ll put some pointers to talks I saw today which were interesting. I realize I am heavily blogging about Berkeley folks here, but you know, they were interesting talks!
Nadia Fawaz talked about differential privacy for continuous observations : in this model you see 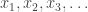

David Tse gave an interesting talk about sequencing DNA via short reads as a communication problem. I had actually had some thoughts along these lines earlier because I am starting to collaborate with my friend Tony Chiang on some informatics problems around next generation sequencing. David wanted to know how many (noiseless) reads 



Michael Jordan talked about the “big data bootstrap” (paper here). You have 
Anant Sahai talked about how to look at some decentralized linear control problems as implicitly doing some sort of network coding in the deterministic model. One way to view this is to identify unstable modes in the plant as communicating with each other using the controllers as relays in the network. By structurally massaging the control problem into a canonical form, they can make this translation a bit more formal and can translate results about linear stabilization from the 80s into max-flow min-cut type results for network codes. This is mostly work by Se Yong Park, who really ought to have a more complete webpage.
Paolo Minero talked about controlling a linear plant over a rate-limited communication link whose capacity evolves according to a Markov chain. What are the conditions on the rate to ensure stability? He made a connection to Markov jump linear systems that gives the answer in the scalar case, but the necessary and sufficient conditions in the vector case don’t quite match. I always like seeing these sort of communication and control results, even though I don’t work in this area at all. They’re just cool.
There were three talks on consensus in the morning, which I will only touch on briefly. Behrouz Touri gave a talk about part of his thesis work, which was on the Hegselman-Krause opinion dynamics model. It’s not possible to derive a Lyapunov function for this system, but he found a time-varying Lyapunov function, leading to an analysis of the convergence which has some nice connections to products of random stochastic matrices and other topics. Ali Jadbabaie talked about work with Pooya Molavi on non-Bayesian social learning, which combines local Bayesian updating with DeGroot consensus to do distributed learning of a parameter in a network. He had some new sufficient conditions involving disconnected networks that are similar in flavor to his preprint. José Moura talked about distributed Kalman filtering and other consensus meets sensing (consensing?) problems. The algorithms are similar to ones I’ve been looking at lately, so I will have to dig a bit deeper into the upcoming IT Transactions paper.
Banff blog
I figured I would blog about this week’s workshop at Banff in a more timely fashion. Due to the scheduling of flights out of Calgary, I will have to miss the last day of talks. The topics of people’s presentations varied rather widely, and many were not about the sort of Good-Turing estimator setup. Sometimes it was a bit hard to see how to see how the problems or approaches were related (not that they had to be directly), but given that the crowd had widely varying backgrounds, presenters had a hard time because the audience had to check in a new set of notation or approach for every talk. The advantage is that there were lots of questions — the disadvantage is that people insisted on “finishing” their presentations. By mid-week my brain was over-full, and a Wednesday afternoon hike up Sulphur Mountain was the perfect solution.

The view from Sulpur Mountain
Banfffffffffffffff
I’ve just arrived in chilly but beautiful Banff for a workshop on Information theory and statistics for large alphabets. I’m looking forward to it, although I will have to miss the last day due to the timing of flights out of Calgary that get me to Chicago before midnight. My itineraries there and back seem especially perverse : ORD-SEA-YYC and YYC-SFO-ORD. However, thanks to the new gig I have a new laptop with a functional battery so I am doing a bit more busy-work and less New Yorker reading in the plane. I might try to write a bit more about the topics in the workshop — although the topic seems focused, there are a wide range of approaches and angles to take on the problem of estimating probabilities/prevalences in situations where you may not get to see each outcome once. Certainly I hope I can get the journal version of a paper from last year’s Allerton squared away.
Allerton 2011
I am at the 7^2nd Allerton Conference at the moment and will write about the few talks I managed to take notes on in a bit. As usual, I have adopted a poor strategy for talk attendance – speakers often run over (poor planning for your talk, folks!) and if you switch sessions you end up standing in the back or outside the room. The key to success is to arrive early and not move. Alas, that is less fun.
Next year, they should consider heavy curtains for the front of the Solarium to block
HealthSec 2011
I also attended HealthSec ’11 this week, and the program was a little different than what I had expected. There was a mix of technical talks and policy/framework proposals around a couple of themes:
- security in medical devices
- auditing in electronic medical records
- medical record dissemination and privacy
In particular, a key challenge in healthcare coming up is how patient information is going to be handled in heath insurance exchanges (HIE’s) that will be created as part of the Affordable Care Act. The real question is what is the threat model for health information : hackers who want to wholesale health records, or the selling of data by third parties (e.g. insurance companies). Matthew Green from Dartmouth discussed implications of the PCAST report on Health Information Technology, which I will have to read.
The most interesting part of the workshop was the panel on de-identification and whether it was a relevant or useful framework moving forward. The panelists were Sean Nolan from Microsoft, Kelly Edwards from University of Washington, Arvind Narayanan from Stanford, and Lee Tien from the EFF. Sean Nolan talked a bit about how HIPAA acts as an impediment to exploratory research, which I have worked on a little, but also raised the thorny ethical issue of public good versus privacy, which is key to understanding the debate over health records in clinical research. Edwards is a bioethicist and had some very important points to raise about how informed consent is an opportunity to educate patients about their (potential) role in medical research, but also to make them feel like informed participants in the process. The way in which we phrase the tradeoff Nolan mentioned really relates to ethics in how we communicate the tradeoff to patients. Narayanan (famous for his Netflix deanonymization) talked about the relationship between technology and policy has to be rethought or turned more into a dialogue rather than a blame-shifting or challenge-posing framework. Lee Tien made a crucial point that if we do not understand how patient data moves about in our existing system, then we have no hope of reform or regulation, and no stakeholder in the system how has that “bird’s eye view” of these data flows.
I hope that in the future I can contribute to this in some way, but in the meantime I’ve been left with a fair bit to chew on. Although the conference was perhaps a bit less technical than I would have liked, I think it was quite valuable as a starting point for future work.
