Here are my much-belated post-ISIT notes. I didn’t do as good a job of taking notes this year, so my points may be a bit cursory. Also, the offer for guest posts is still open! On a related note the slides from the plenary lectures are now available on Dropbox, and are also linked to from the ISIT website.
From compression to compressed sensing
Shirin Jalali (New York University, USA); Arian Maleki (Rice University, USA)
The title says it, mostly. Both data compression and compressed sensing use special structure in the signal to achieve a reduction in storage, but while all signals can be compressed (in a sense), not all signals can be compressively sensed. Can one get a characterization (with an algorithm) that can take a lossy source code/compression method, and use it to recover a signal via compressed sensing? They propose an algorithm called compressible signal pursuit to do that. The full version of the paper is on ArXiV.
Dynamic Joint Source-Channel Coding with Feedback
Tara Javidi (UCSD, USA); Andrea Goldsmith (Stanford University, USA)
This is a JSSC problem with a Markov source, which can be used to model a large range of problems, including some sequential search and learning problems (hence the importance of feedback). The main idea is to map the problem in to a partially-observable Markov decision problem (POMDP) and exploit the structure of the resulting dynamic program. They get some structural properties of the solution (e.g. what are the sufficient statistics), but there are a lot of interesting further questions to investigate. I usually have a hard time seeing the difference between finite and infinite horizon formulations, but here the difference was somehow easier for me to understand — in the infinite horizon case, however, the solution is somewhat difficult to compute.
Unsupervised Learning and Universal Communication
Vinith Misra (Stanford University, USA); Tsachy Weissman (Stanford University, USA)
This paper was about universal decoding, sort of. THe idea is that the decoder doesn’t know the codebook but it knows the encoder is using a random block code. However, it doesn’t know the rate, even. The question is really what can one say in this setting? For example, symmetry dictates that the actual message label will be impossible to determine, so the error criterion has to be adjusted accordingly. The decoding strategy that they propose is a partition of the output space (or “clustering”) followed by a labeling. They claim this is a model for clustering through an information theoretic lens, but since the number of clusters is exponential in the dimension of the space, I think that it’s perhaps more of a special case of clustering. A key concept in their development is something they call the minimum partition information, which takes the place of the maximum mutual information (MMI) used in universal decoding (c.f. Csiszár and Körner).
On AVCs with Quadratic Constraints
Farzin Haddadpour (Sharif University of Technology, Iran); Mahdi Jafari Siavoshani (The Chinese University of Hong Kong, Hong Kong); Mayank Bakshi (The Chinese University of Hong Kong, Hong Kong); Sidharth Jaggi (Chinese University of Hong Kong, Hong Kong)
Of course I had to go to this paper, since it was on AVCs. The main result is that if one considers maximal error but allow the encoder only to randomize, then one can achieve the same rates over the Gaussian AVC as one can with average error and no randomization. That is, allowing encoder randomization can move from average error to max error. An analogous result for discrete channels is in a classic paper by Csiszár and Narayan, and this is the Gaussian analogue. The proof uses a similar quantization/epsilon-net plus union bound that I used in my first ISIT paper (also on Gaussian AVCs, and finally on ArXiV), but it seems that the amount of encoder randomization needed here is more than the amount of common randomness used in my paper.
Coding with Encoding Uncertainty
Jad Hachem (University of California, Los Angeles, USA); I-Hsiang Wang (EPFL, Switzerland); Christina Fragouli (EPFL, Switzerland); Suhas Diggavi (University of California Los Angeles, USA)
This paper was on graph-based codes where the encoder makes errors, but the channel is ideal and the decoder makes no errors. That is, given a generator matrix 
 coins with biases
coins with biases ![\{p_i : i \in [n]\}](https://s0.wp.com/latex.php?latex=%5C%7Bp_i+%3A+i+%5Cin+%5Bn%5D%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) . For some given
. For some given ![p \in [\epsilon,1-\epsilon]](https://s0.wp.com/latex.php?latex=p+%5Cin+%5B%5Cepsilon%2C1-%5Cepsilon%5D&bg=ffffff&fg=333333&s=0&c=20201002) and
and 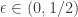 , each coin is “heavy” (
, each coin is “heavy” (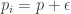 ) with probability
) with probability  and “light” (
and “light” (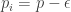 ) with probability
) with probability 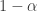 . The goal is to use a sequential flipping strategy to find a heavy coin with probability at least
. The goal is to use a sequential flipping strategy to find a heavy coin with probability at least  .
. . On the basis of that, you need a rule to pick which coin to flip. Finally, you need a stopping criterion.
. On the basis of that, you need a rule to pick which coin to flip. Finally, you need a stopping criterion.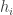 heads and
heads and  tails, then the likelihood ratio is
tails, then the likelihood ratio is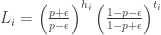
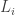 so far (breaking ties arbitrarily).
so far (breaking ties arbitrarily). . These appear in the stopping criterion. The algorithm keeps flipping coins until there exists at least one $i$ for which
. These appear in the stopping criterion. The algorithm keeps flipping coins until there exists at least one $i$ for which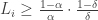
 heads and tails for a coin $i$,
heads and tails for a coin $i$,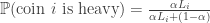 ,
,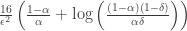
 (plus lower-order terms), since that is the maximum possible expected hitting time for a random walk on an n-vertex graph [2]; the same bound applies to the random cop [4]. It is easy to see that the greedy cop who merely moves toward the drunk at every step can achieve
(plus lower-order terms), since that is the maximum possible expected hitting time for a random walk on an n-vertex graph [2]; the same bound applies to the random cop [4]. It is easy to see that the greedy cop who merely moves toward the drunk at every step can achieve 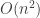 ; in fact, we will show that the greedy cop cannot in general do better. Our smart cop, however, gets her man in expected time
; in fact, we will show that the greedy cop cannot in general do better. Our smart cop, however, gets her man in expected time 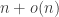 .
.
 -user interference channel with gains
-user interference channel with gains  between transmitter
between transmitter  . Then if
. Then if